- The paper’s main contribution is the joint optimization of the latent encoder with diffusion and decoding modules, resulting in enhanced latent geometry and improved generative perplexity.
- It details a composite training method that integrates hidden-state MSE, token reconstruction loss, and adaptive timestep sampling, stabilized by a diffusion-to-encoder warmup.
- Empirical results demonstrate up to 13× faster sampling and better quality-diversity tradeoffs on benchmarks like OpenWebText and LM1B compared to existing methods.
Joint Training of Latent Diffusion LLMs: A Technical Overview
Background and Motivation
Non-autoregressive text generation via diffusion models has emerged as a viable alternative to traditional autoregressive LMs. While discrete diffusion models defined directly in token space dominate current research, their limitations—including independent per-token decision-making at each denoising step—create fundamental barriers to efficiency and global sentence-level coordination. Continuous diffusion models operating in a latent space address many of these issues, enabling holistic refinement of representations and rapid, parallelizable sampling. However, the construction and parameterization of a suitable latent space remains a central challenge.
The latent space must simultaneously support high-fidelity decoding to text and be amenable to stable, effective denoising under diffusion dynamics. Prior latent diffusion approaches for language have typically relied on frozen, pre-trained encoders to construct this space, decoupling latent formation from the requirements of downstream diffusion. This paper posits and empirically validates that joint training of the latent encoder with the diffusion model and decoder yields superior latent geometry and model performance, but also reveals significant optimization difficulties that must be addressed.
Model Architecture and Training Procedure
The Latent Diffusion LLM (LDLM) consists of four main components: a frozen pre-trained token encoder (e.g., GPT-2), a trainable latent encoder, a trainable latent decoder, and a trainable diffusion transformer. Text sequences are first converted to contextual hidden states using the frozen encoder, then mapped by the latent encoder into a lower-dimensional, diffusion-friendly latent space. Decoding follows the reverse pathway, with optional Gaussian noise added to increase robustness, first reconstructing hidden states with the latent decoder and then tokens via a token-level decoder.
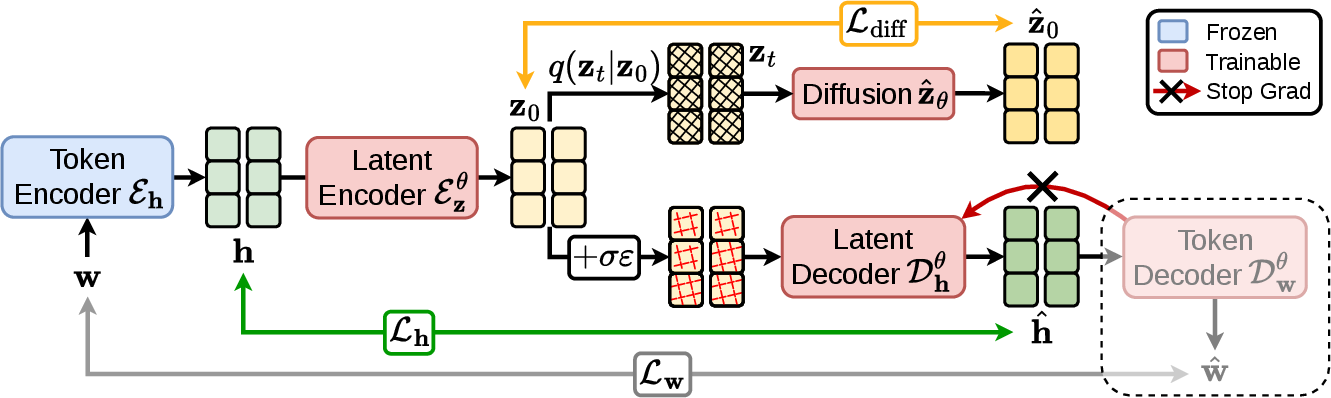
Figure 1: Schematic of the joint training framework showing frozen and trainable components and the forward/reverse latent pathways.
Joint Objective
LDLM is optimized with a composite objective:
- Latent decoder loss (Lh): MSE between clean contextual hidden states and decoder reconstructions from noisy latents, critical for stabilizing optimization and supporting smooth latent interpolations.
- Diffusion loss (Ldiff): MSE between clean and denoised latents, following standard continuous diffusion modeling.
- Token reconstruction loss (Lw): Standard token-level cross-entropy, applied with a stop-gradient to avoid interfering with latent encoder learning.
Key to effective training is a diffusion-to-encoder warmup, in which the encoder is first pretrained to reconstruct hidden states, activating gradients from the diffusion loss only after a prescribed number of steps. This initialization prevents collapse of the latent representation and enables stable end-to-end optimization.
Additionally, adaptive timestep sampling ensures a more uniform allocation of denoising difficulty across the diffusion trajectory, proven essential when the latent space itself evolves during training.
Ablative Analysis
The paper performs extensive ablations elucidating the contributions of each component of the training recipe.
- Reconstruction loss: Hidden-state MSE is vastly superior to token-level cross-entropy, both for generation quality and for achieving smoothness in latent space interpolations, confirmed by perplexity metrics along interpolated latent trajectories.
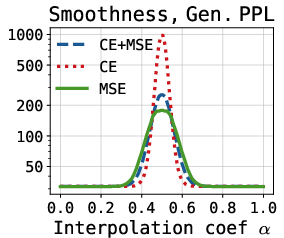
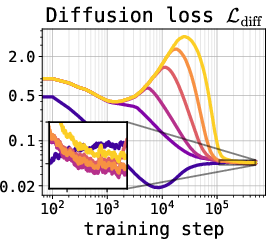
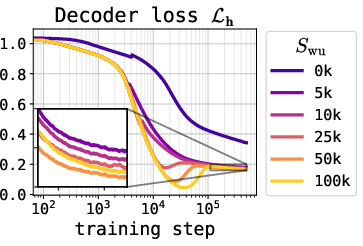
Figure 2: Left—Superior smoothness of the latent space during interpolation when using MSE loss; Middle/Right—effect of warmup schedule on diffusion and decoder loss dynamics, indicating the necessity of appropriate warmup.
- Token encoder choice: Contextual representations from frozen transformer encoders outperform shallow learned embeddings as the basis for diffusion modeling by substantial margins.
- Decoder input noise (σdec): Proper regularization via latent input noise to the decoder prevents overfitting to spurious latent directions, increases robustness to denoising error, and allows better capacity allocation.
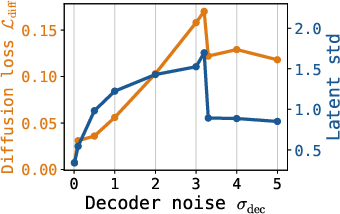
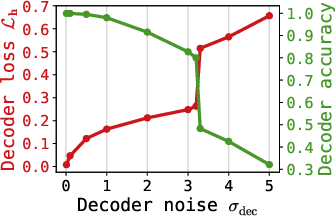
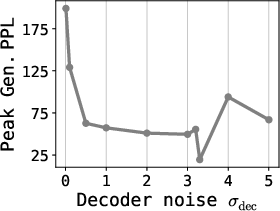
Figure 3: Influence of decoder input noise σdec on latent space smoothness and sample quality.
Comparison of Latent Spaces
LDLM's joint optimization regime was rigorously compared against several existing paradigms for constructing diffusion latent spaces:
- Shallow token embeddings (trained or frozen)
- Pre-trained transformer encodings (frozen, as in TEncDM)
- Latents from a frozen autoencoder trained with explicit smoothing objectives (COSMOS)
Results substantiate that jointly learned latents are significantly more "diffusable," with markedly better generative perplexity, sample diversity, and distributional fidelity (Mauve score).
Main Results and Empirical Findings
On both OpenWebText and LM1B benchmarks, LDLM establishes a notably improved Pareto frontier in the quality-diversity tradeoff, achieving lower generative perplexity at equivalent diversity levels, and, crucially, doing so with 2–13× faster sampling than all competing discrete and continuous diffusion baselines.
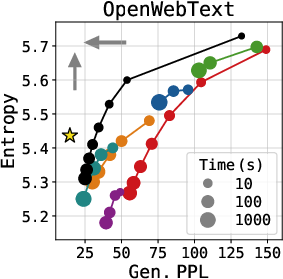
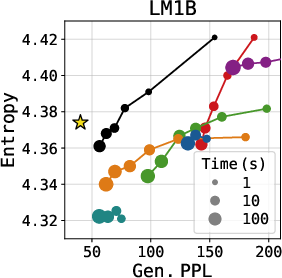

Figure 4: Quality-diversity trade-off across different methods—LDLM trace achieves superior perplexity-entropy curves and lower generation times (marker size).
The efficiency gain stems from the lower-dimensional latent space, which enables a drastic reduction in per-step computational overhead relative to vocab-projection-intensive discrete approaches. Further, the elimination of iterative token-level decoding reduces sampling latency, enabling application in contexts previously dominated by autoregressive or shallow continuous models.
Theoretical and Practical Implications
The strong empirical superiority of LDLM underlines the necessity of shaping the latent space to the idiosyncratic needs of diffusion-based generation directly, not merely inheriting it from unrelated upstream objectives. This insight parallels converging trends in vision (e.g., joint training on DINO or CLIP embeddings for image diffusion [stable_diffusion]) and calls into question the practice of freezing powerful pre-trained encoders as universal feature providers in generative tasks.
Moreover, the procedure outlined here—joint latent-diffusion learning with careful loss composition, staged optimization, and adaptive noise schedules—provides a blueprint for further advances, including:
- Conditional and controlled text generation: Extending joint latent training to conditional paradigms may bridge the remaining gap to high-reasoning, long-context text synthesis.
- Few-step and distillation approaches: While LDLM achieves strong performance with moderate step counts, integration with state-of-the-art acceleration techniques (e.g., DPM-solver [dpm-solver], SA-Solver [sa_solver]) could close the gap to instantaneous generation regimes.
- Latent space geometry and interpretability: The explicit influence of the denoising objective on representation geometry offers avenues for structured decoding, compositionality, and enhanced controllability.
Conclusion
This work establishes that competitive, efficient, and high-quality non-autoregressive text generation via diffusion models is best achieved by jointly learning the latent space in concert with the diffusion dynamics and decoder. The techniques developed—particularly reconstruction via hidden-state MSE, adaptive training schedules, and robust noise augmentation—are immediately transferable to other latent generative models. The findings strongly suggest that future advances in non-autoregressive language generation will depend on further breaking down the separation between latent representation learning and generative modeling, and replacing "frozen" practices with task-driven, end-to-end protocols.
Reference: "How to Train Your Latent Diffusion LLM Jointly With the Latent Space" (2605.07933)

