Fast Byte Latent Transformer
Abstract: Recent byte-level LMs match the performance of token-level models without relying on subword vocabularies, yet their utility is limited by slow, byte-by-byte autoregressive generation. We address this bottleneck in the Byte Latent Transformer (BLT) through new training and generation techniques. First, we introduce BLT Diffusion (BLT-D), a new model and our fastest BLT variant, trained with an auxiliary block-wise diffusion objective alongside the standard next-byte prediction loss. This enables an inference procedure that generates multiple bytes in parallel per decoding step, substantially reducing the number of forward passes required to generate a sequence. Second, we propose two extensions inspired by speculative decoding that trade some of this speed for higher generation quality: BLT Self-speculation (BLT-S), in which BLT's local decoder continues generating past its normal patch boundaries to draft bytes, which are then verified with a single full-model forward pass; and BLT Diffusion+Verification (BLT-DV), which augments BLT-D with an autoregressive verification step after diffusion-based generation. All methods may achieve an estimated memory-bandwidth cost over 50% lower than BLT on generation tasks. Each approach offers its own unique advantages, together removing key barriers to the practical use of byte-level LMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about making a special kind of LLM—one that reads and writes text as raw bytes (the smallest pieces of data, like letters and symbols)—much faster at writing. The model they build on is called the Byte Latent Transformer (BLT). BLT is accurate but slow because it writes one byte at a time. The authors introduce new ways to let BLT write several bytes at once, making it much more efficient while keeping quality high.
The main questions the paper asks
- How can we speed up byte-based LLMs so they don’t have to write text one byte at a time?
- Can we do that without losing the good things about byte models (like handling many languages and weird inputs well)?
- Can we keep the quality of the generated text while reducing how many times we have to run the big, heavy parts of the model?
How the methods work (in everyday terms)
First, a quick picture of BLT:
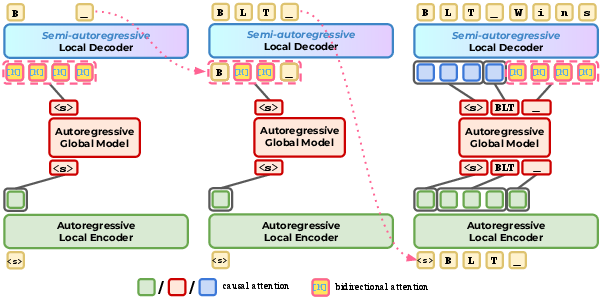
- Imagine writing a story with a helper. The helper groups nearby letters into “patches” based on how hard they look, then turns each patch into a compact summary (“latent token”). A big brain (the global model) thinks about the sequence of summaries, and a smaller brain (the decoder) turns each summary back into detailed letters.
- This setup is accurate, but writing one letter (byte) at a time is slow, especially because words usually take several bytes.
The paper proposes three speed-up ideas. Think of them like different ways to draft multiple letters at once before carefully checking them.
- BLT-D (Diffusion): Like filling in a small “blanked-out” block of letters all at once.
- Training: The model practices on blocks of letters where some are hidden with [MASK], learning to fill them in from the surrounding context.
- Inference (generation): When the model writes, it creates a block of [MASK] positions and fills several letters at once, using a “fill-the-blanks” strategy inside the block. This reduces the number of times it needs to call the heavy parts of the model.
- Analogy: It’s like solving a mini crossword: you fill a few squares together using clues.
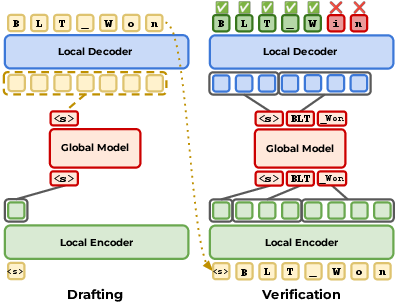
- BLT-S (Self-speculation): The model’s own small decoder drafts a few extra letters past the usual stopping point, then the full model checks.
- The small decoder “keeps going” for a short window.
- Then the full model verifies: if everything matches, accept; if not, roll back to the first mismatch and continue from the correct letter.
- Analogy: A fast typist drafts a sentence, and an editor checks it; any mistakes are fixed before moving on.
- BLT-DV (Diffusion + Verification): Mixes the two ideas above.
- First, use BLT-D’s fast “fill-the-blanks” block drafting.
- Then, verify the drafted block using the normal step-by-step method.
- Analogy: Draft a paragraph quickly, then have the editor approve it line by line.
Key ideas made simple:
- “Bytes” vs “tokens”: Tokens are chunks like words or word pieces. Bytes are tiny units like characters. Byte models are flexible for many languages and weird inputs, but writing letter-by-letter is slow.
- “Patches” and “latent tokens”: Grouping nearby letters into patches, then turning them into summaries so the big model thinks at a higher level.
- “Diffusion” here is like repeatedly unmasking hidden letters in a block, guided by context, instead of going strictly one letter at a time.
- “Verification” is a check step that guarantees the output is as trustworthy as normal step-by-step writing when using greedy decoding.
What they found and why it matters
They tested their methods on:
- Translation (French→English, German→English)
- Code generation (writing small programs)
Main results:
- All three methods reduce how often the big, heavy parts of the model have to run.
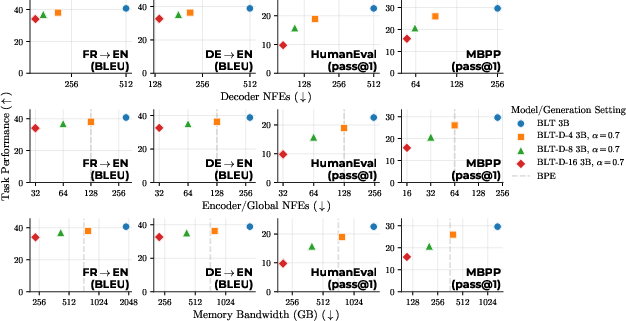
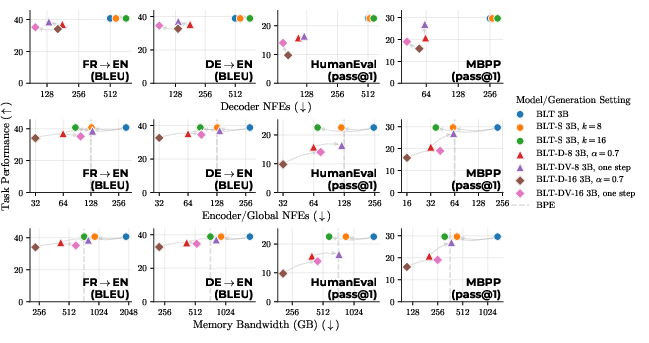
- BLT-D (Diffusion) is the fastest overall. It can cut estimated memory-bandwidth cost by over 50%, and with bigger blocks, up to about 92%. However, very large blocks can hurt quality on tougher tasks like code.
- BLT-DV (Diffusion + Verification) recovers much of that quality while still being very fast, saving up to about 81%.
- BLT-S (Self-speculation) speeds up the original BLT by up to about 77% without losing quality, because the verification step ensures the final output matches what the normal method would have produced.
Why it matters:
- Byte models are great at handling many languages, unusual text, and noisy inputs because they don’t rely on fixed vocabularies. These speed-ups make byte models practical for real applications by cutting the time and memory needed to generate text.
What this could change in the future
- Faster, more universal LLMs: Since byte models don’t depend on language-specific vocabularies, making them fast unlocks fairer support across languages and better handling of messy or mixed-format text.
- Lower costs and latency: Fewer “heavy” passes through the big model means cheaper and faster responses, which is key for phones, small servers, or latency-sensitive apps.
- Flexible trade-offs: You can choose pure speed (BLT-D with large blocks), balanced speed and quality (BLT-DV), or speed with guaranteed quality (BLT-S), depending on your needs.
- Next steps: Scaling the small decoder and tuning block sizes could make these methods even faster or more accurate.
In short, this paper shows how to keep the strengths of byte-level models while removing one of their biggest weaknesses: slow, byte-by-byte generation. The three techniques—Diffusion, Self-speculation, and Diffusion+Verification—offer practical ways to generate multiple bytes at once, saving time and memory without giving up quality.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances byte-level generation speed with BLT-D, BLT-S, and BLT-DV, but leaves several important issues unresolved. The following concrete gaps can guide follow-up research:
- Real-world speedups vs. estimated memory bandwidth:
- No end-to-end wall-clock throughput/latency measurements (tokens/sec, bytes/sec) across hardware (e.g., A100/H100, CPUs) and batch sizes; results rely on an estimated memory-bandwidth proxy and NFE counts.
- Absent profiling of time spent in encoder/global vs. decoder vs. patcher, and the effect of KV-cache reads/writes and attention FLOPs on actual runtime.
- KV-cache and memory behavior:
- Lack of analysis on KV-cache size/eviction behavior under BLT-D’s mixed causal/bidirectional masks and frequent re-encoding for verification.
- No quantification of memory usage and cache reuse when patch boundaries shift after drafting, potentially invalidating caches.
- Scaling beyond 1B/3B:
- No evaluation at larger model scales (e.g., 7B, 13B, 70B) to test whether speed–quality trade-offs and acceptance rates hold, and whether decoder capacity scaling recovers quality for large block sizes.
- Task and domain coverage:
- Limited to FLORES (Fr/De→En) and two code tasks; no tests on long-form generation, open-ended QA, reasoning/math, multilingual beyond two source languages, or noisy/OOD inputs where byte-level models often excel.
- The degradation on code tasks with large B is noted but not analyzed; no error typology (e.g., syntax vs. semantics) or task-specific mitigations.
- Long-context behavior:
- No evaluation on long sequences (e.g., 8–32k+ bytes) to assess patcher stability, diffusion block reliability over long horizons, and coherence under mixed causal/bidirectional attention.
- Greedy-only verification:
- BLT-S/DV verification is proven only for greedy decoding; no method or results for sampling (temperature, top-k/p), nor guarantees that the verified output matches the target distribution under stochastic decoding.
- No study of rejection sampling variants or distribution-preservation criteria for non-greedy decoding.
- Draft acceptance dynamics:
- Missing quantitative analysis of acceptance rates and rollback frequency vs. block/window size, domain, or entropy; no model of expected verified length per draft and its variance.
- No ablation on how acceptance rates affect actual throughput once verification recompute is included.
- Unmasking policies:
- Only confidence-based and entropy-bounded (EB) unmasking are explored; no learned or adaptive policies, and no comparison of calibration quality vs. thresholds (α, γ).
- No theoretical or empirical study of mutual-information approximations behind EB selection, nor their effect on error coupling within a block.
- Training–inference mismatch in diffusion:
- Training masks blocks starting at each patch boundary and uses a uniform without timestep embeddings; inference drafts a fixed-size future block conditioned only on the last latent token.
- Unclear whether embedding (or using a non-uniform schedule) improves quality, or whether training on block positions that more closely match inference improves acceptance.
- Diffusion schedule and step count:
- One-step diffusion is suggested as fastest with verification but can degrade quality without it; no exploration of multi-step schedules, number of unmasking iterations , or curriculum over that might improve quality–speed trade-offs.
- Cross-attention design for drafted bytes:
- Drafted block positions cross-attend only to the last latent token (); the impact of allowing cross-attention to predicted future latent tokens or a small set of recent tokens is not studied.
- Adaptive block sizing:
- Block size is fixed; no exploration of dynamically choosing conditioned on local entropy/uncertainty or model confidence to balance speed and quality.
- Decoder capacity and allocation:
- Authors hypothesize that a larger decoder could help BLT-D/DV, but provide no scaling study; optimal allocation of parameters between global model and local decoder remains unclear.
- Interaction with the entropy patcher:
- No analysis of how patcher calibration/thresholds affect BLT-D/S/DV efficiency and acceptance, nor whether the patcher becomes a bottleneck.
- Stability of patch boundaries pre- and post-draft (and its effect on recomputation/caching) is unmeasured.
- Likelihood and calibration:
- While likelihood-based evaluations are mentioned, there is no clear comparison of NLL/per-byte perplexity across methods or the impact of diffusion training on calibration (e.g., confidence–accuracy curves for unmasking decisions).
- Baselines with strong token-level accelerators:
- Comparisons to token-level acceleration methods (e.g., speculative decoding with a separate draft model, Medusa, EAGLE) are missing; the BPE “dashed line” uses a naive baseline and may understate the token-level state of the art.
- Hardware–software co-design:
- No exploration of kernel-level optimizations (e.g., fused attention, FlashAttention with bidirectional blocks) or quantization (INT8/INT4) and their interplay with memory bandwidth and acceptance rates.
- Energy and cost:
- Absent measurements of energy consumption or cost-per-output-byte in realistic serving settings; memory-bandwidth proxy may not reflect total cost.
- Robustness and multilingual:
- No tests on scripts with complex Unicode (e.g., CJK, Indic), mixed encodings, or adversarial/noisy bytes that often highlight byte-level advantages.
- Training compute and convergence:
- Added diffusion loss and data preprocessing costs are not reported; no analysis of training stability, convergence speed, or the effect of loss weighting between and .
- End-of-sequence and boundary effects:
- Blocks that exceed the sequence are padded with [PAD]; effects on learning near document boundaries and on EOS handling are not analyzed.
- Formal guarantees:
- No theoretical characterization of error propagation within a block, or bounds linking unmasking confidence/entropy to expected block error rate and acceptance probability.
- Safety and alignment:
- No consideration of how block-wise diffusion and verification interact with safety filters, guardrails, or instruction-following alignment during inference-time control.
These gaps suggest immediate experiments (e.g., acceptance-rate curves vs. B and domain; wall-clock benchmarks with KV-caching across hardware), architectural ablations (e.g., decoder capacity, cross-attention targets, adaptive B), and algorithmic extensions (e.g., sampling-consistent verification, learned unmasking, non-uniform diffusion schedules) to strengthen the proposed methods and broaden their applicability.
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed now, leveraging the paper’s methods (BLT-D, BLT-S, BLT-DV) to reduce memory bandwidth and speed up byte-level LMs without sacrificing their tokenizer-free advantages.
Software and Developer Tools
- Faster code assistants with tokenizer-free robustness
- Sectors: software, IDEs, DevOps
- What/How: Replace or augment current code LLM backends with BLT-S (no quality loss vs BLT) or BLT-DV (quality-preserving), cutting encoder/global NFEs while remaining robust to unusual encodings, mixed scripts, and rare symbols in code and logs.
- Tools/Products/Workflows: “Speculative byte decoding” plugin for common inference stacks (vLLM/TensorRT/Triton), IDE extensions using BLT-S for drafting and BLT-DV for verification in critical blocks (e.g., function bodies).
- Assumptions/Dependencies: Greedy decoding verification guarantees identical outputs to standard BLT; sampling requires additional tuning. Integrations must implement dynamic masks and KV-cache reuse.
- Reliable text normalization and sanitization utilities
- Sectors: software, data engineering
- What/How: Use BLT-D for high-throughput byte-level cleaning (deobfuscation, Unicode normalization, removing control chars) where slight quality trade-offs are acceptable; use BLT-DV/BLT-S when exactness is needed.
- Tools/Products/Workflows: Microservices for byte cleaning before tokenization-dependent pipelines, ensuring consistent downstream behavior.
- Assumptions/Dependencies: Throughput gains assume small-batch, latency-oriented serving.
Localization, Translation, and Customer Support
- Low-latency, multilingual chat/translation with fairness across scripts
- Sectors: customer support, localization, telecom
- What/How: Serve translation and multilingual chat on BLT-D-4/8 (near-BLT quality at significantly lower bandwidth); switch to BLT-S/BLT-DV for premium tiers demanding no regressions.
- Tools/Products/Workflows: Call-center copilots and real-time subtitling services with adaptive block sizes by language pair.
- Assumptions/Dependencies: Quality-speed tuning per language; monitoring acceptance rates in verification.
Trust & Safety and Content Moderation
- Unicode-hardening for moderation at scale
- Sectors: trust & safety, social media
- What/How: Detect and normalize adversarial Unicode obfuscations (homoglyphs, ZWJ, confusables) using tokenizer-free byte models; BLT-D for bulk triage, BLT-DV for appeals/precision passes.
- Tools/Products/Workflows: Moderation pipelines that pre-normalize content bytes before rule or model evaluation.
- Assumptions/Dependencies: Clear policy mappings; latency SLAs benefit from reduced memory bandwidth.
Security and Observability
- Byte-native malware, binary, and log analysis
- Sectors: cybersecurity, platform reliability
- What/How: Analyze obfuscated code, scripts, and mixed-encoding logs; BLT-D for rapid triage, BLT-S/BLT-DV for verified signatures and rule generation.
- Tools/Products/Workflows: SOC copilots that parse binaries/firmware blobs and noisy logs without tokenizers.
- Assumptions/Dependencies: Domain-specific fine-tuning; careful evaluation for false positives.
Edge and On-Device Experiences
- On-device writing, translation, and autocorrect
- Sectors: mobile, IoT, consumer apps
- What/How: Deploy BLT-S to preserve quality with reduced global-model invocations; BLT-D for lightweight devices where small accuracy trade-offs are tolerable.
- Tools/Products/Workflows: Keyboards, email drafting, offline translation with configurable block sizes.
- Assumptions/Dependencies: Memory-bandwidth gains strongest at small batch sizes; hardware must support dynamic/bidirectional attention masks.
Healthcare and Regulated Domains (with proper validation)
- Robust clinical text utilities (EHR normalization, OCR cleanup)
- Sectors: healthcare IT
- What/How: Clean and normalize clinical notes with mixed encodings/typos; BLT-DV for verified outputs in safety-critical workflows.
- Tools/Products/Workflows: Pre-ingestion byte-level normalization service for EHR systems.
- Assumptions/Dependencies: Requires domain validation, governance, and compliance; use verification for determinism.
Academia and Research Infrastructure
- Fair and robust multilingual benchmarks at scale
- Sectors: academia
- What/How: Use BLT-S/BLT-DV for high-fidelity evaluation without tokenization artifacts; BLT-D for large sweeps or ablations.
- Tools/Products/Workflows: Open-source evaluation harnesses supporting diffusion blocks and verification, dataset releases with byte-level preprocessing.
- Assumptions/Dependencies: Reproducible patcher settings; reporting of acceptance rates and speed–quality trade-offs.
Long-Term Applications
These rely on further engineering, scaling, or research to mature (e.g., enhanced verification under sampling, larger decoders, new kernels, broader domain validation).
Foundation Model Strategy and Platformization
- Tokenizer-free foundation models as default backends
- Sectors: software, cloud platforms
- What/How: Replace BPE-centric stacks with byte-native models leveraging BLT-D/BLT-S/BLT-DV to unify handling of long-tail languages, noisy text, and mixed encodings.
- Tools/Products/Workflows: Managed “Byte-native LLM” services with policy-driven speed–quality knobs (block size, EB sampling thresholds).
- Assumptions/Dependencies: Continued parity with token-level models on broad benchmarks; production inference engines optimizing dynamic masks and cache reuse.
Safety-Critical Verified Generation
- Verified drafting frameworks for code, configs, contracts
- Sectors: software, fintech, safety-critical systems
- What/How: Generalize BLT-DV into standardized “draft+verify” pipelines with stronger acceptance criteria, coverage metrics, and rollback strategies under sampling.
- Tools/Products/Workflows: CI/CD gates that only accept verified bytes; policy controls for maximum unverified span.
- Assumptions/Dependencies: Extensions of verification beyond greedy decoding; calibrated rejection and backoff strategies.
Public Sector and Policy
- Fair, efficient multilingual access at scale
- Sectors: government services, NGOs
- What/How: Tokenizer-free chat/translation for underserved languages with reduced energy and cost; BLT-D for high-volume intake, BLT-DV for official outputs.
- Tools/Products/Workflows: Procurement guidelines favoring tokenizer-free fairness and energy efficiency; standardized speed–quality reporting.
- Assumptions/Dependencies: Robustness audits; language coverage extension; privacy and security certifications.
Data Compression and Transmission
- Learned text compression with diffusion blocks
- Sectors: telecom, storage
- What/How: Leverage byte diffusion to propose compact representations or error-resilient reconstructions; hybrid AR/diffusion decoding for consistent fidelity.
- Tools/Products/Workflows: Compression codecs that co-design with block unmasking and verification.
- Assumptions/Dependencies: Research on rate–distortion, error propagation, and streaming constraints.
Security and Binary Understanding
- General-purpose binary/doc format assistants
- Sectors: cybersecurity, firmware, reverse engineering
- What/How: Train domain-specialized BLT-D/BLT-DV models to parse and transform heterogeneous binary formats, packed malware, and firmware images.
- Tools/Products/Workflows: Assisted reverse-engineering environments that propose and verify transformations at the byte level.
- Assumptions/Dependencies: Curated datasets; rigorous evaluation against obfuscation tactics.
Energy and Hardware Co-Design
- Inference kernels and hardware for block diffusion + verification
- Sectors: semiconductors, cloud
- What/How: Specialized attention kernels for mixed causal/bidirectional masks; memory systems tuned for reduced weight loads and KV-cache footprints.
- Tools/Products/Workflows: Compiler passes that fuse unmasking steps; schedulers that adapt block sizes to hardware counters.
- Assumptions/Dependencies: Vendor support; standardized APIs for dynamic attention patterns.
Education and Accessibility
- Byte-robust literacy and assistive tools for noisy inputs
- Sectors: education, accessibility
- What/How: Tutors and readers robust to typos, OCR, and mixed scripts; locally verified drafting for exams or formal submissions.
- Tools/Products/Workflows: Classroom devices running BLT-S locally; institution-level verification services for submissions.
- Assumptions/Dependencies: Usability studies; policy alignment for academic integrity.
Federated and Privacy-Preserving Learning
- On-device/federated training for low-resource languages
- Sectors: mobile, privacy tech
- What/How: Combine tokenizer-free coverage with efficient inference to enable training and personalization on-device for underserved languages.
- Tools/Products/Workflows: Federated fine-tuning loops with diffusion drafting and conservative verification for stability.
- Assumptions/Dependencies: Communication-efficient updates; privacy accounting; legal frameworks for data sharing.
Notes on Feasibility and Dependencies
- Speed–quality trade-offs: Larger diffusion blocks (BLT-D) maximize speed but can reduce task quality; BLT-S and BLT-DV recover quality with some overhead.
- Verification guarantees: Exact-match verification as presented preserves greedy-decoding outputs; extending to temperature/sampling needs further methods and calibration.
- Serving assumptions: Measured memory-bandwidth gains assume small batch sizes and KV-cache usage typical of latency-oriented serving; throughput at high batch may differ.
- Engineering requirements: Productionization needs dynamic attention masks (causal prefix + bidirectional blocks), cache reuse across blocks, and patcher integration.
- Model availability: Deployments depend on access to trained BLT/BLT-D weights and the entropy-based patcher; domain adaptation may be necessary for specialized sectors.
- Safety and compliance: Healthcare, finance, and public-sector uses require validation, monitoring, and governance; use BLT-DV/BLT-S for deterministic outputs where needed.
Glossary
- Absorbing discrete diffusion: A discrete diffusion formulation for text where a special mask token acts as an absorbing state and corruption is applied by masking tokens with probability based on a timestep. "Here, we focus on absorbing discrete diffusion with conventions similar to those presented by~\citet{ye2025dream7b} and~\citet{nie-etal-2025-llada}, which is conceptually very similar to masked LLMs~\citep{devlin-etal-2019-bert}."
- Absorbing state: A state in a diffusion process that, once entered, cannot transition out (here, the [MASK] token). "Prior work has shown that this masking process can be interpreted as the marginal of a discrete diffusion model with an absorbing state, where is absorbing and controls the diffusion time."
- Autoregressive verification step: A verification phase that checks drafted outputs using causal next-token predictions from the same or target model. "BLT Diffusion+Verification (BLT-DV), which augments BLT-D with an autoregressive verification step after diffusion-based generation."
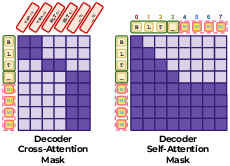
- Bidirectional attention: Attention that allows each position to attend to both past and future positions in a sequence. "These models are typically non-autoregressive, employing bidirectional attention over all tokens, or semi-autoregressive, using bidirectional attention within fixed-length blocks while maintaining causal dependencies across blocks"
- Block diffusion decoding: Generating multiple future positions in parallel by denoising a masked block rather than producing one token at a time. "BLT-D directly addresses this challenge by introducing block diffusion decoding in a way that is fully compatible with BLTâs hierarchical architecture"
- Byte-level LMs: Models that operate directly on raw bytes instead of subword tokens. "Recent byte-level LMs match the performance of token-level models without relying on subword vocabularies"
- Byte-pair encoding (BPE): A common subword tokenization method that merges frequent byte pairs to form a vocabulary. "The NFEs and memory bandwidth for a byte-pair encoding (BPE) model matching BLT's global model size are shown as a dashed line."
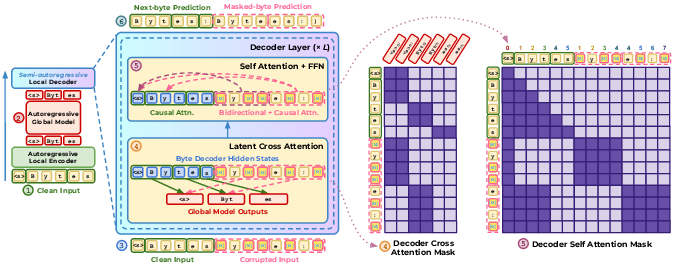
- Causal attention: An attention mask that restricts each position to attend only to itself and previous positions. "After a block of bytes is drafted (via self-speculation in BLT-S or diffusion in BLT-DV), the full model re-encodes the candidate sequence and produces next-byte predictions using causal attention."
- Causal decoder masks: Attention masks applied to the decoder to enforce autoregressive (left-to-right) dependencies. "Since BLT-D is trained with a next-byte prediction objective, it can be run autoregressively using the same causal decoder masks as BLT."
- Confidence-based unmasking: A parallel decoding strategy that unmasks positions whose predicted probability exceeds a confidence threshold. "The first strategy is confidence-based unmasking~\citep{ghazvininejad-etal-2019-mask}."
- Cross-attention: Attention where one sequence (e.g., decoder states) attends to another (e.g., encoder or latent tokens). "At each layer, byte-level hidden states are updated via cross-attention to latent token representations before applying a standard Transformer layer."
- Denoising objective: A training loss that reconstructs original data from corrupted inputs, common in diffusion and masked modeling. "Training minimizes the weighted denoising objective"
- Diffusion LLMs (dLMs): LLMs trained with diffusion-style corruption and denoising on discrete tokens. "We first draw inspiration from diffusion LLMs (dLMs), which improve decoding efficiency by generating multiple tokens in parallel within a single forward pass"
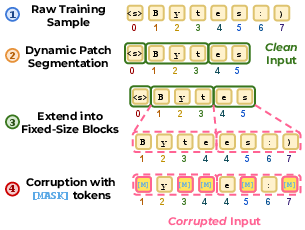
- Dynamic patching: Adaptive grouping of bytes into variable-length segments based on local complexity/entropy to allocate compute. "Our goal is to enable byte-level parallel generation while preserving the main benefits of BLT: operating directly on bytes, using dynamic patching, and concentrating computation in latent token representations."
- Evidence lower bound (ELBO): A variational objective that lower-bounds the log-likelihood, often optimized in generative modeling. "which has been shown to correspond to a simplified evidence lower bound (ELBO) on the data log-likelihood, or equivalently, an upper bound on the negative log-likelihood"
- Entropy-based patcher: A segmentation module that uses predictive uncertainty (entropy) to define patch boundaries. "Segment into patches via entropy-based patcher"
- Entropy-bounded sampling: A parallel unmasking strategy that selects positions whose cumulative entropy stays below a threshold. "The second strategy is entropy-bounded (EB) sampling~\citep{ben-hamu2025accelerated, gat2025setblockdecodinglanguage}."
- Greedy decoding: Deterministic generation that selects the highest-probability token at each step. "All task-evaluation inference uses greedy decoding."
- Hierarchical latent tokenization: Creating and operating on higher-level latent tokens derived from bytes to enable efficient computation. "BLT achieves scalable and efficient byte-level modeling by dynamically allocating compute resources through hierarchical latent tokenization."
- KV cache: Cached key and value tensors from attention to speed up autoregressive inference by avoiding recomputation. "BLT-D supports KV caching, and therefore benefits from any techniques that reduce KV-cache memory footprint."
- Latent token representations: Higher-level embeddings summarizing groups of bytes that the global model processes. "The encoder then processes into latent token representations"
- Masked LLMs: Models trained to predict masked tokens from their context, often using bidirectional attention. "which is conceptually very similar to masked LLMs~\citep{devlin-etal-2019-bert}."
- Masked-byte prediction loss: A loss that trains the model to reconstruct masked bytes within corrupted blocks. "and a masked-byte prediction loss on corrupted byte blocks."
- Memory bandwidth: The amount of data transfer required (e.g., for loading weights/KV cache) that can bottleneck inference speed. "inference still faces a memory bandwidth bottleneck."
- Mutual information: A measure of dependence between variables; used here to reason about joint uncertainty across masked positions. "Since mutual information among masked tokens is intractable to compute directly"
- Network function evaluations (NFEs): Counts of forward passes through model components used as a proxy for inference cost. "Compared to BLT, this inference approach decreases the forward passes/network function evaluations (NFEs) of all model components (encoder, global model, and decoder)."
- Next-byte prediction loss: The standard autoregressive objective of predicting the next byte given the prefix. "trained with an auxiliary block-wise diffusion objective alongside the standard next-byte prediction loss."
- Pre-LayerNorm: A Transformer variant applying layer normalization before attention/MLP sublayers. "The decoder Transformer layer employs multi-head attention, pre-LayerNorm, and RoPE positional encodings."
- RoPE positional encodings: Rotary positional embeddings that encode relative positions via rotations in embedding space. "The decoder Transformer layer employs multi-head attention, pre-LayerNorm, and RoPE positional encodings."
- Self-speculation: Using the same model’s lightweight component to draft future tokens beyond normal boundaries before verification. "The first extension is BLT Self-speculation (BLT-S)."
- Semi-autoregressive: A decoding regime that is autoregressive across blocks but bidirectional within each block. "These models are typically non-autoregressive, employing bidirectional attention over all tokens, or semi-autoregressive, using bidirectional attention within fixed-length blocks while maintaining causal dependencies across blocks"
- SentencePiece BLEU: A BLEU evaluation computed over SentencePiece subword units, used for translation metrics. "with performance measured by SentencePiece BLEU."
- Speculative decoding: A two-stage generation method where a draft is proposed by a fast model/component and then verified by a stronger model. "we introduce two additional inference extensions inspired by speculative decoding that trade some of this speed for higher generation quality"
- Top-p sampling: Nucleus sampling that selects from the smallest set of tokens whose cumulative probability exceeds p. "This unmasking strategy may be combined with top- sampling to obtain diverse generations from the model."
- Verification: A step that checks drafted tokens against the model’s own autoregressive predictions, accepting up to the first mismatch. "Verification procedure shared by BLT-S and BLT-DV."
Collections
Sign up for free to add this paper to one or more collections.

