- The paper demonstrates that replacing dense feedforward layers with sparse MoE layers in looped transformers recovers expressivity lost through weight tying.
- The methodology employs parameter reuse, isoFLOP scaling laws, and precise numerical benchmarks to compare looped architectures with dense baselines.
- The findings suggest that sparse expert routing in looped models optimizes compute-quality tradeoffs and early-exit strategies, paving the way for efficient deployment.
Sparse Layers are Critical to Scaling Looped LLMs
Introduction
Looped LLMs (LoopLMs) employ parameter reuse by iteratively applying a stack of transformer layers through depth, minimizing memory costs and enabling early-exit strategies during inference. However, empirical results consistently show that naïvely looping dense transformer layers leads to inferior scaling compared to standard non-looped transformers, particularly under fixed-compute scenarios governed by established scaling laws [kaplan_scaling_2020], [hoffmann_training_2022]. This work systematically investigates the role of sparse Mixture-of-Experts (MoE) feedforward layers as a mechanism to break this scaling barrier in looped architectures. By explicitly isolating the contribution of sparse computation, the study sharply delineates the regime where looped architectures, with proper sparsification, can beat traditional transformers both in scaling and inference quality-cost profile.
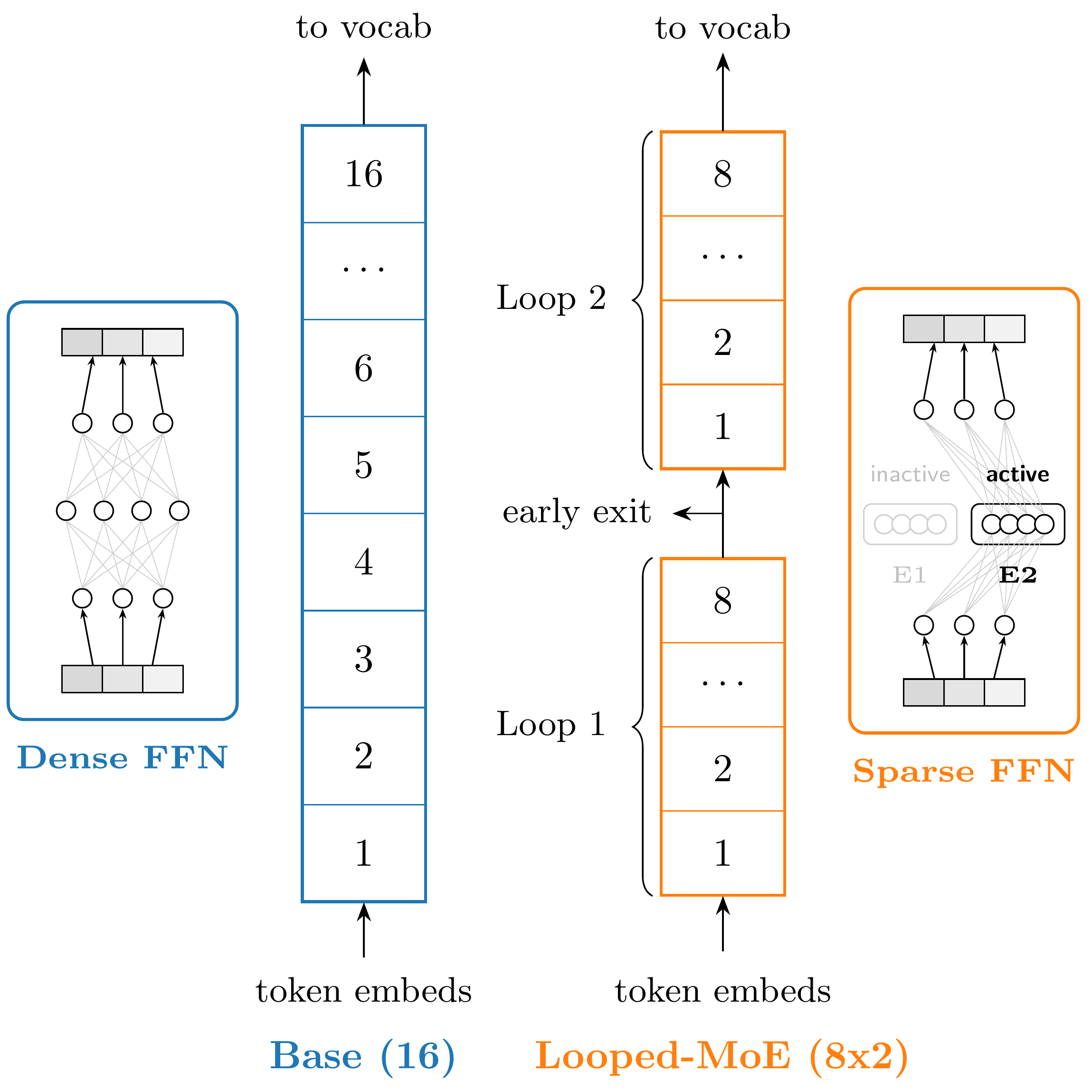
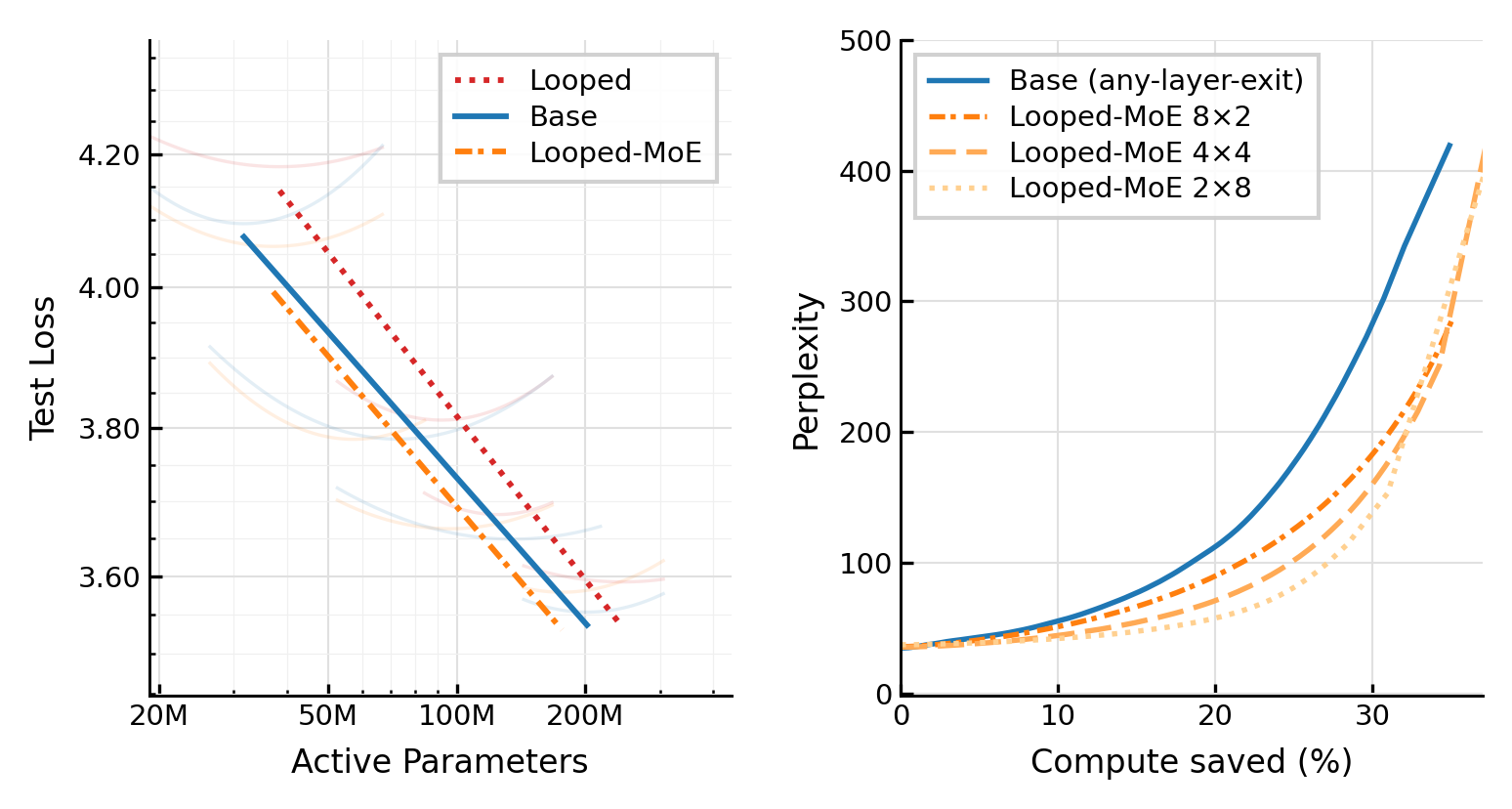
Figure 1: Looped-MoE models (with repeated stacks and sparse MoE FFNs) outperform dense base transformers in isoFLOP test loss and compute-quality early-exit tradeoffs. Larger numbers of loops further improve these tradeoffs.
Architectural Variants and Parameterization
The comparative analysis centers on four classes of decoder-only transformer models, distinguished by two axes: (a) dense versus sparse (MoE) feedforward layers, and (b) unique (Base/MoE) versus looped (Looped/Looped-MoE) stacking. All employ rotary positional embeddings, pre-RMSNorm, and SwiGLU activations. In looped variants, a reduced set of L unique layers is repeatedly applied R times such that effective depth matches non-looped baselines. MoE layers use token-level top-k routing with k=2 out of E=8 experts per position, with auxiliary load balancing and router z-losses to maintain expertise diversity and stability.
Optimal learning rate transfer across widths is validated via Maximal Update Parameterization (μP) [yang_tensor_2022], achieving consistent loss curves and <1% deviation in optimality—a critical property for efficient isoFLOP scaling law studies.
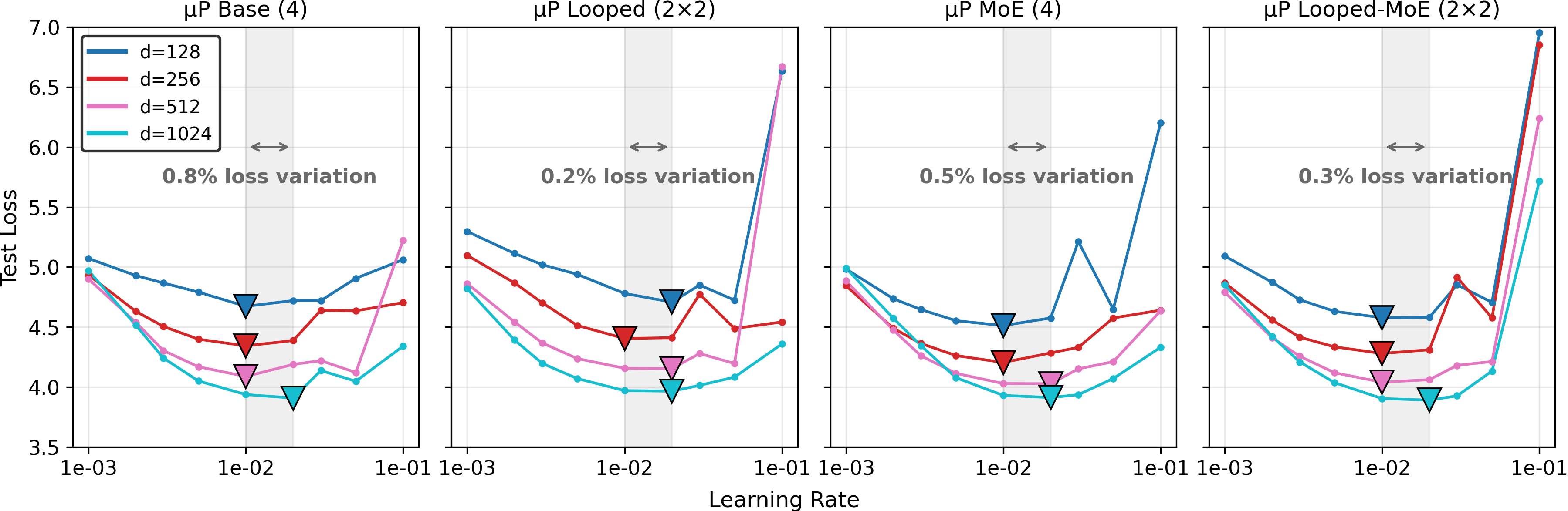
Figure 2: The µP transfer test demonstrates robust learning rate transfer across model widths; optimal small-model hyperparameters remain close to optimal as scale increases.
Scaling Laws and Numerical Outcomes
IsoFLOP scaling laws—stated as test loss L obeying L∝N−α at fixed training compute C=6ND—reveal Looped-MoE models decisively close the scaling gap induced by dense looping. In head-to-head comparisons at fixed compute and parameter count, Looped-MoE achieves lower test loss than both dense Looped and dense Base transformers. Derived scaling exponents α∼0.076–R0 match classic results for standard transformers, demonstrating that it is the sparse routing within looped models, not looping itself, that is essential to recover expressivity.
Critically, in compute-matched scenarios, Looped-MoE models with parameter tying and expert sparsity not only outperform their dense looped counterparts but also match or exceed both base dense and ungated MoE transformers for both test loss and average benchmark performance. For example, on the AI2 OLMES Core-9 benchmark suite, Looped-MoE achieves the highest mean score (39.6) with fewer unique parameters than Base (216M vs 246M), while vanilla MoE—despite best test loss—scores lowest on these downstream tasks, likely due to limited per-token expert coverage.
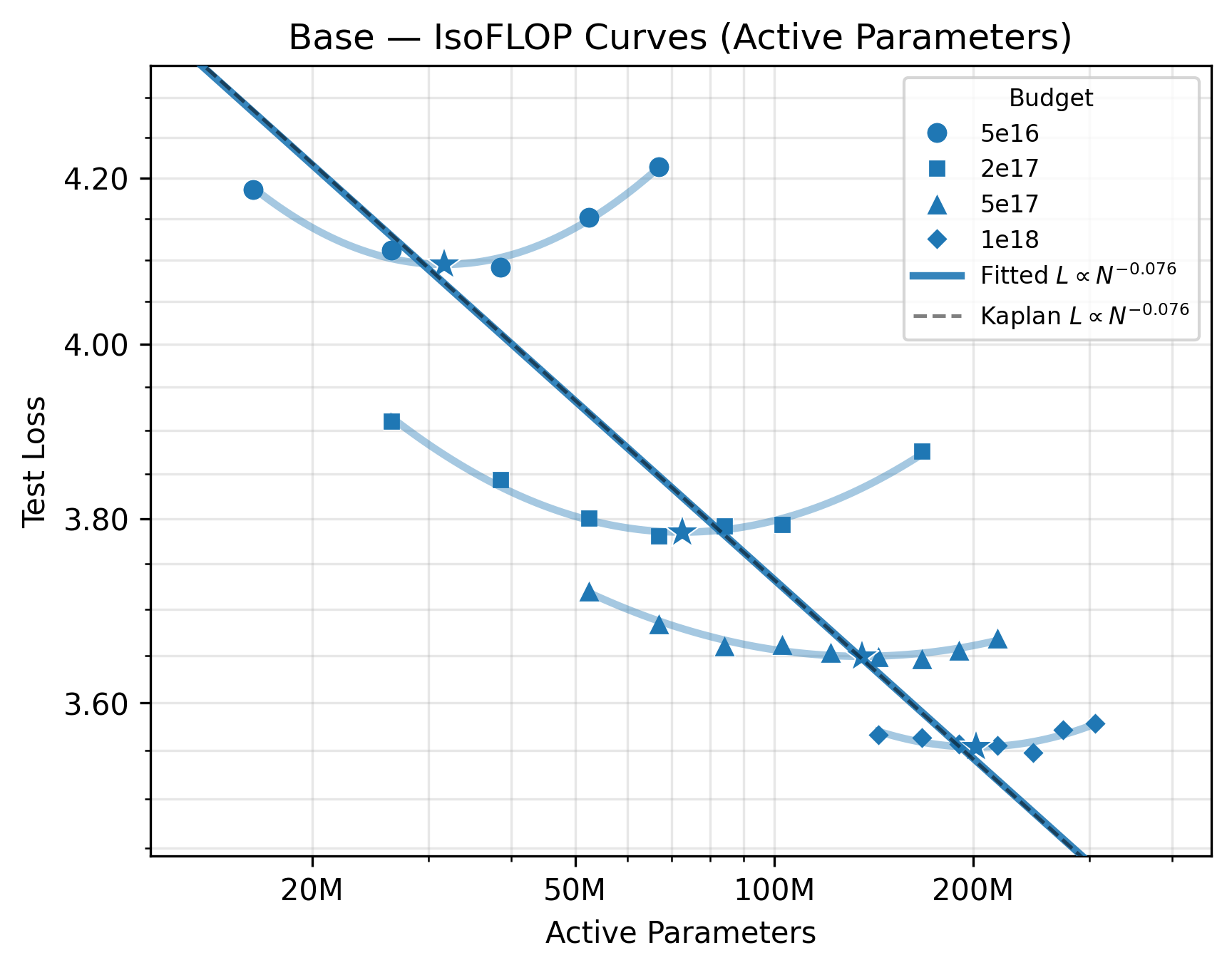
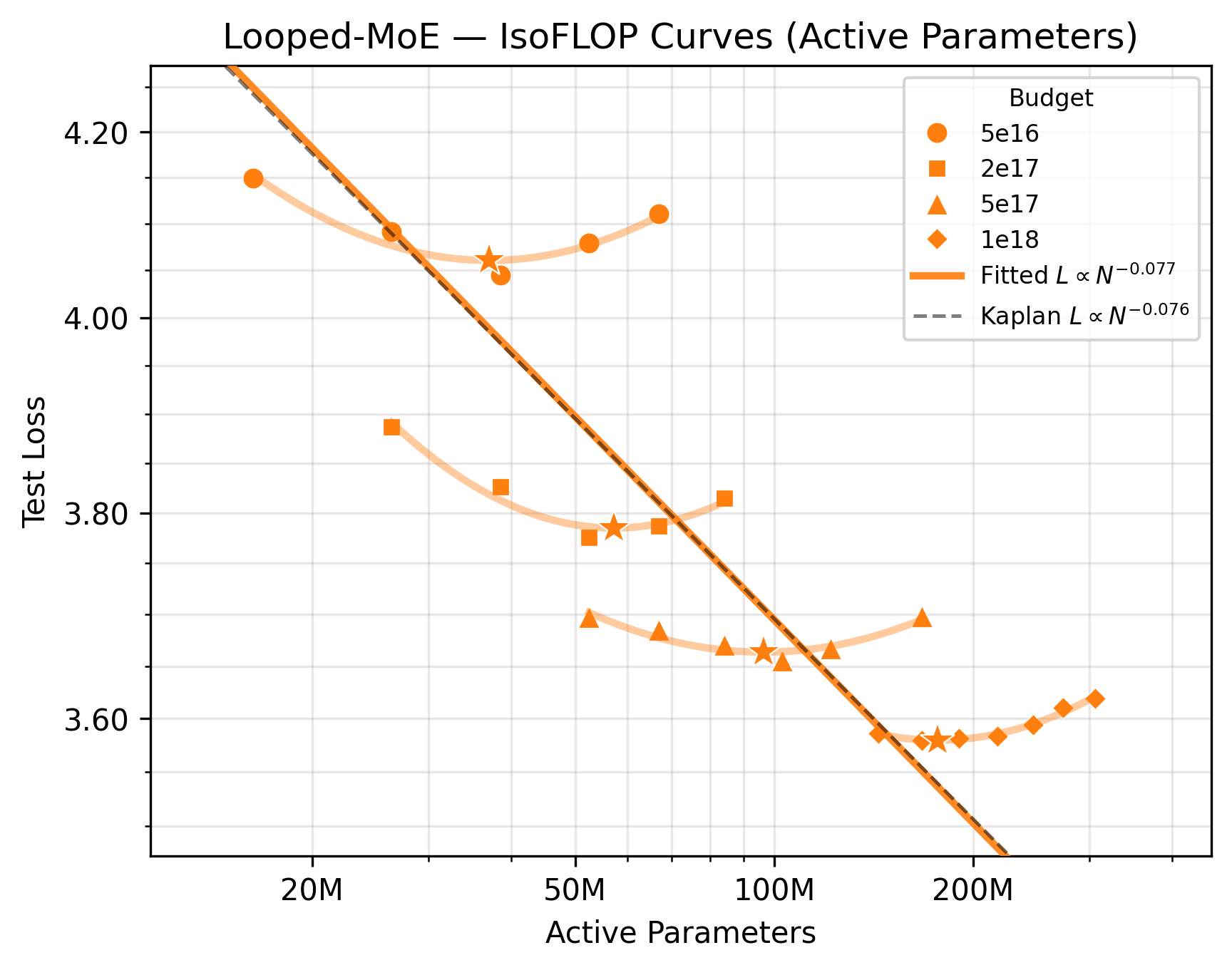
Figure 3: IsoFLOP scaling curves: Left, base transformer; Right, Looped-MoE. Compute-optimal model sizes at each budget and fitted R1 power-laws confirm that sparse expert routing in the looped regime restores scaling.
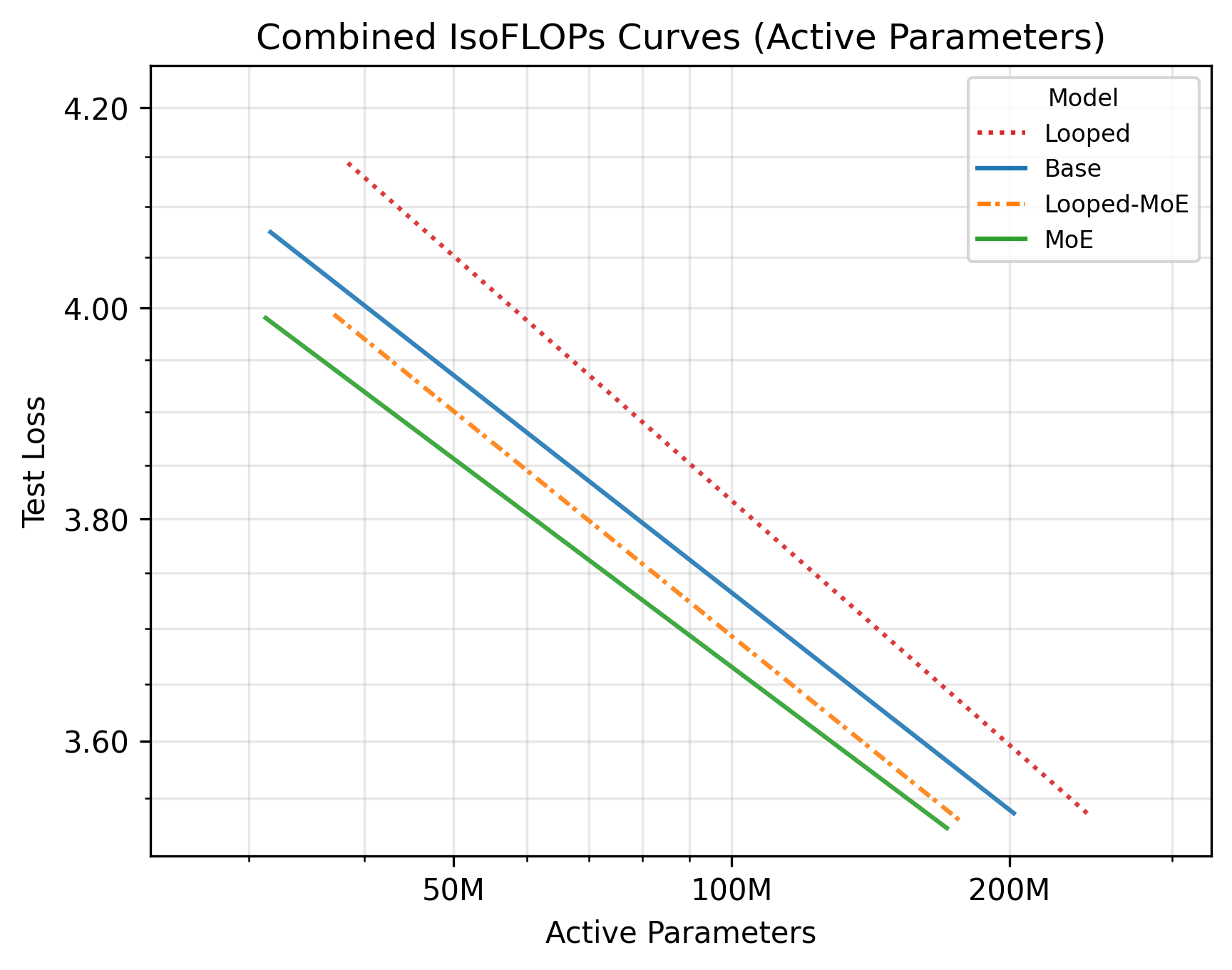
Figure 4: Combined scaling for all architectures. MoE and Looped-MoE display steeper scaling offsets compared to dense models, reaffirming that sparsity, not merely looping, drives improved scaling.
Early-Exit Properties and Compute-Quality Tradeoffs
Early exit mechanisms, especially entropy-threshold-based criteria, are explored systematically in both dense and looped architectures. Looped and Looped-MoE models exhibit strictly superior compute–quality Pareto frontiers compared to dense models, as measured by perplexity at fixed fractions of skipped FLOPs. At 10% FLOPs saved, Looped/Looped-MoE maintain significantly lower perplexity than both base and MoE, e.g., Looped-MoE R2 at 42.0 vs Base at 55.4 and MoE at 75.7.
This advantage is traced to the structural alignment between loop boundaries and final output layers in looped models: at loop boundaries, the activations are processed by the same stack responsible for the model’s end-of-depth output, facilitating much earlier convergence to near-final distributions. Jensen-Shannon divergence (JSD) analyses further corroborate that at these boundaries, a substantially higher fraction of tokens reach near-final output distribution states, both reducing wasted computation and improving early-exit accuracy.
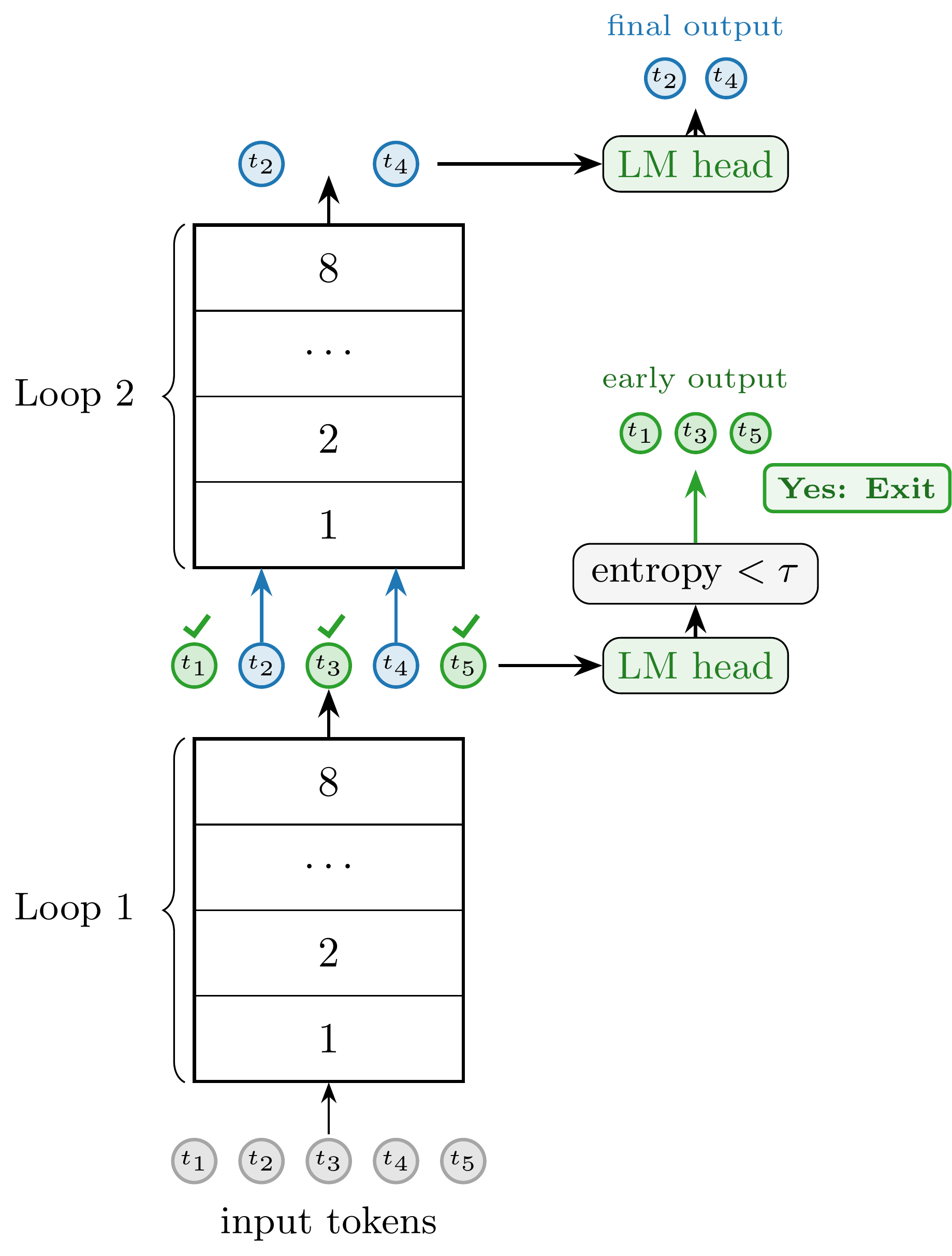
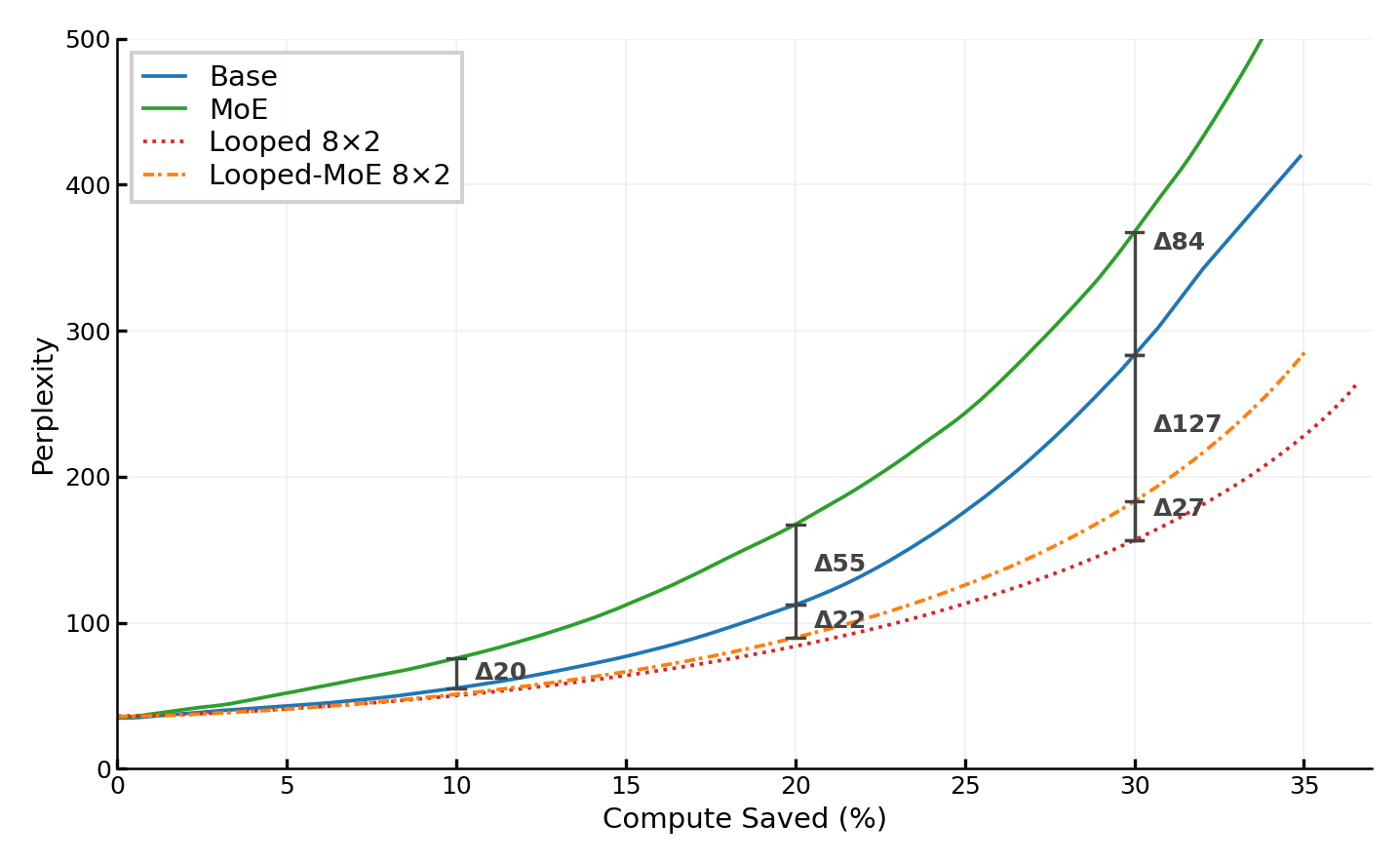
Figure 5: Schematic and empirical compute–quality Pareto curves demonstrate looped architectures yield inherently better early-exit profiles—tokens exit at pre-aligned loop boundaries, saving computation with limited quality degradation.
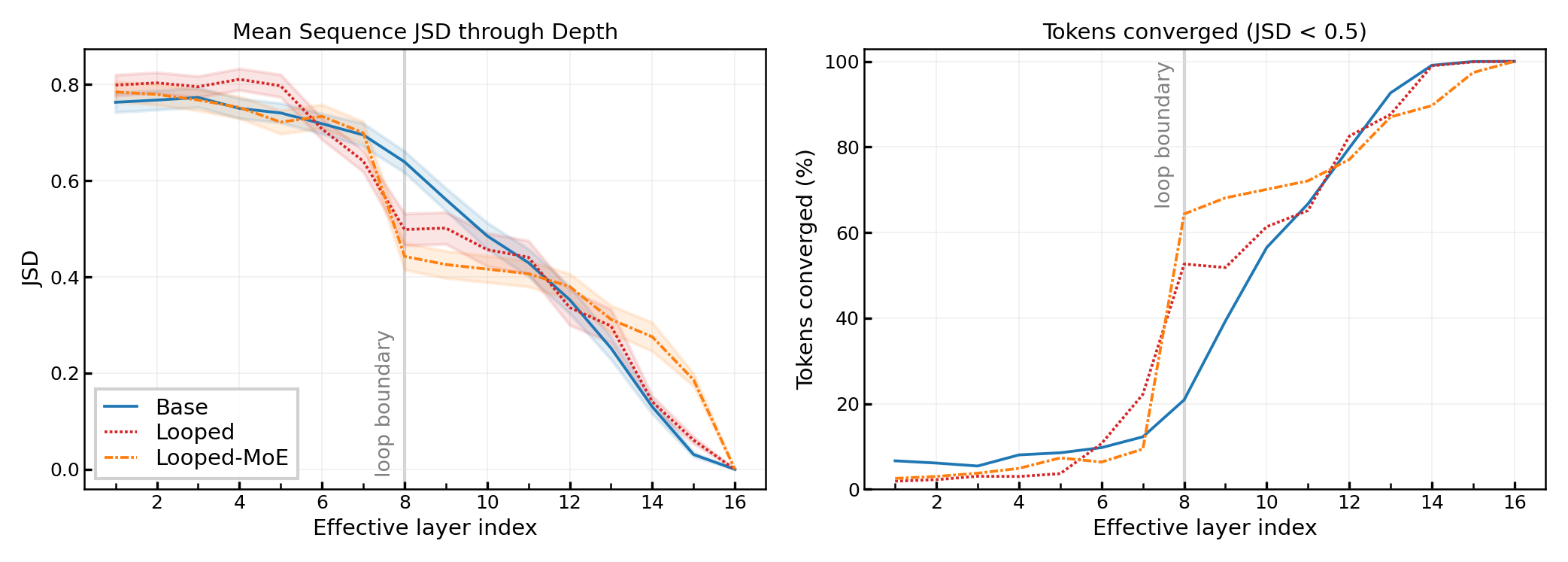
Figure 6: Distributional JSD analysis: tokens in looped models converge more quickly to their eventual output distributions at well-defined loop boundaries, confirming architectural benefits for early exit.
Mechanistic Explanation: Routing Divergence Across Loops
The core architectural insight is that sparse MoE routing enables looped models to sidestep the expressivity loss entailed by weight tying. In Looped-MoE, the expert routing decisions for a given token heavily diverge between repeated passes through the same physical layer, yielding different functional computations per loop iteration without additional parameters. Analysis across layers demonstrates that for the vast majority of tokens and physical layers, the assigned experts on subsequent loop passes are largely non-overlapping. This per-loop specialization is the dominant source of recovered expressivity.
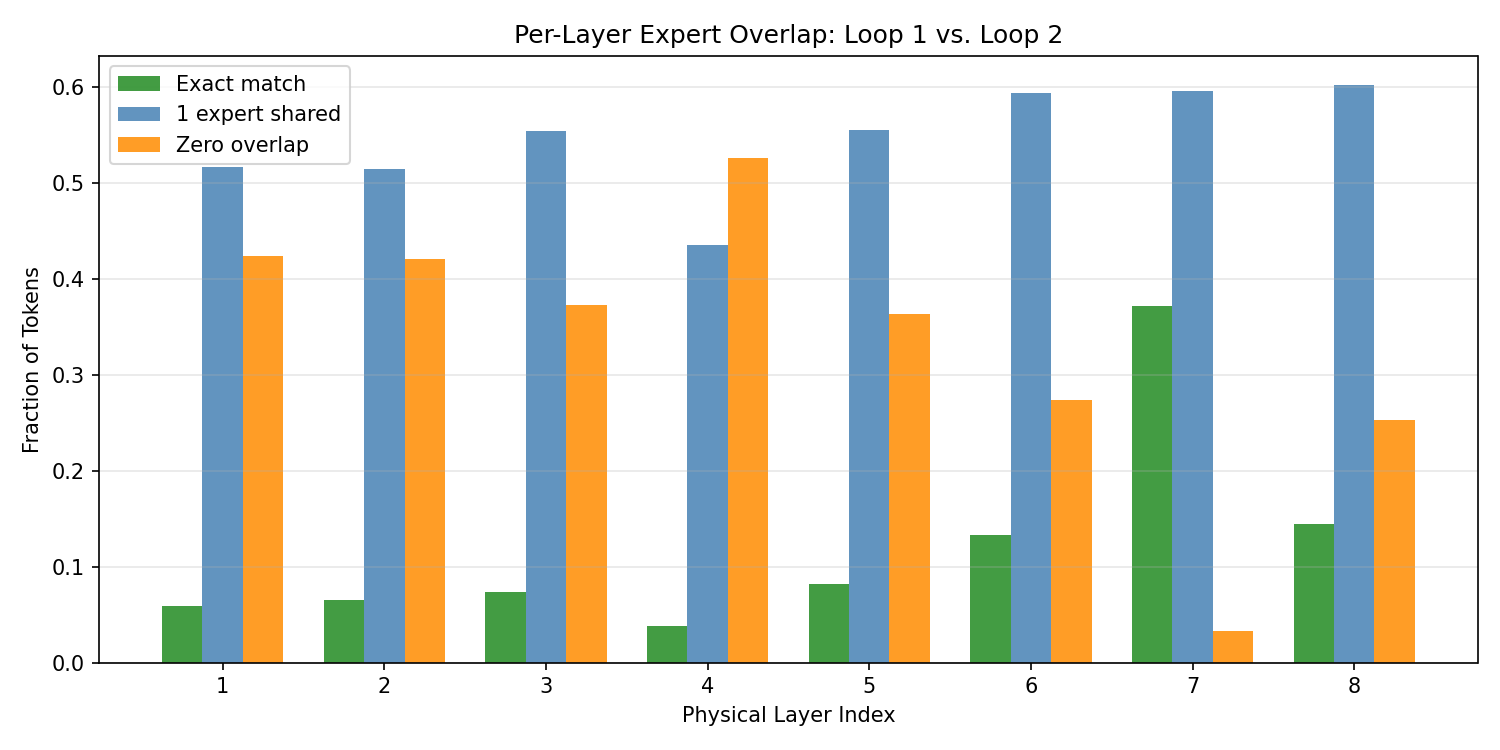
Figure 7: Expert assignment overlap between loop passes in Looped-MoE shows most tokens access distinct experts on different passes, demonstrating how expressivity is restored via per-loop specialization.
Effect of Loop Depth on Efficiency
Varying the number of loops (and thus, natural early-exit points) further improves compute-quality tradeoffs. As the number of loops increases (e.g., R3 versus R4 for 16 effective layers), more exit opportunities arise, each corresponding to a point where the model’s output is well-formed.
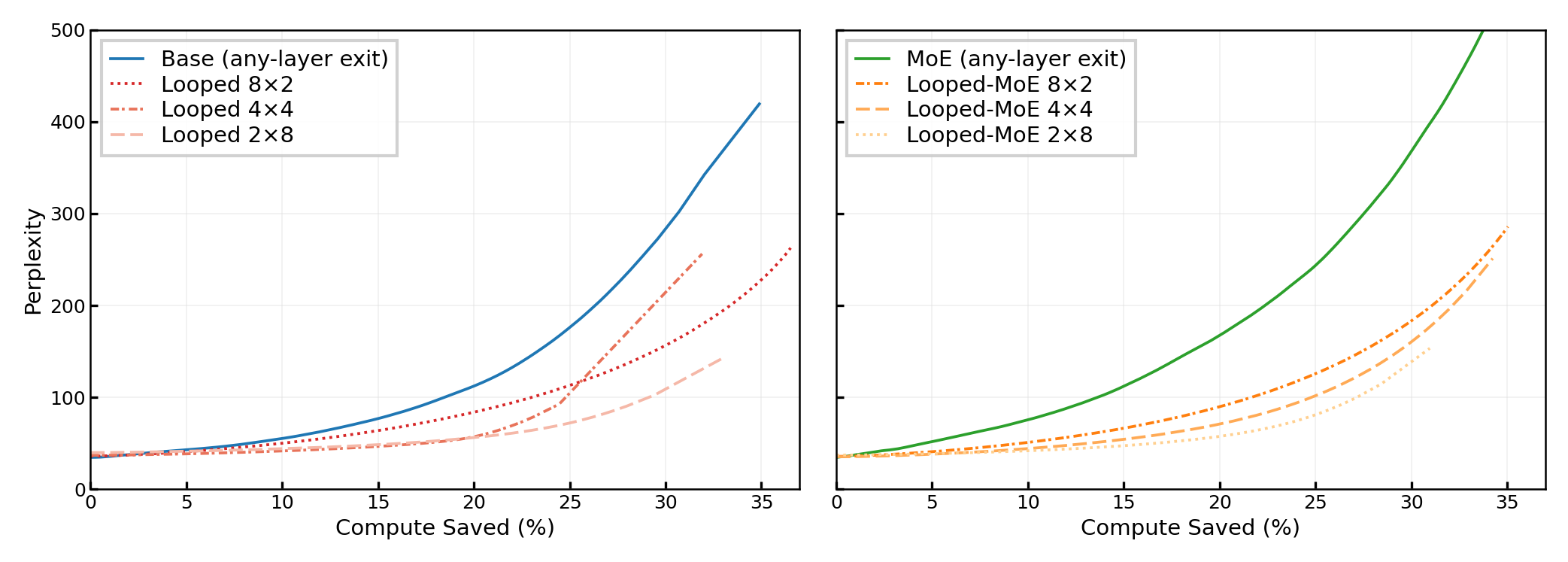
Figure 8: Increasing loop count enhances the compute-quality tradeoffs—more loop boundaries provide more high-quality exit opportunities; Looped-MoE configurations dominate non-looped MoE regardless of exit restrictions.
Practical and Theoretical Implications
The empirical evidence shows that the simple substitution of dense FFNs with sparse MoE layers in looped transformers is both necessary and sufficient to close the scaling gap relative to dense baselines. This positions Looped-MoE as the optimal design point for practitioners aiming to minimize storage and inference costs at a given quality level. The mechanism is purely architectural; no additional supervision or training regime is required.
On the theoretical side, this work clarifies that the scaling deficit of looped architectures is caused by the interaction between weight tying and dense, input-invariant computation. Sparse, per-token expert routing injects the required per-depth heterogeneity for scaling laws to hold under weight sharing. The finding that looped models with MoE routing can outperform larger dense models on downstream tasks under matched compute suggests fertile ground for further investigation, particularly in test-time adaptive computation and hardware specialization.
Conclusion
Sparse Layers are Critical to Scaling Looped LLMs establishes that parameter tying in transformers, when combined with MoE routing, enables parameter- and compute-efficient architectures that scale comparably or better than traditional dense stacks. Looped-MoE not only matches or exceeds dense baselines in loss and downstream benchmark accuracy, but also unlocks superior early-exit strategies for inference acceleration. The architectural mechanisms underlying these results—specifically loop-divergent expert assignment and loop-boundary alignment for early exit—indicate clear, robust paths for the efficient deployment of increasingly deep LLMs. Future directions include extending to larger parameter regimes, integrating adaptive loop-depth mechanisms, and exploring the alignment of these architectural properties with emerging compute and memory-constrained hardware platforms.