- The paper introduces a novel MEME benchmark that evaluates LLM memory across multi-entity and evolving temporal dynamics.
- The paper shows that current LLM systems struggle with dependency reasoning, with cascade and absence tasks reporting accuracies as low as 3% and 1%.
- The paper highlights that achieving cost-efficient, dependency-aware memory requires principled innovations beyond simple scaling of LLM capacity.
MEME: Multi-entity & Evolving Memory Evaluation — A Technical Analysis
Motivation and Benchmark Design
LLM agents operating in persistent, interactive environments increasingly require sophisticated memory architectures that support not just static retrieval, but also updating and reasoning over knowledge with intricate dependencies across multiple entities and over time. Existing benchmarks have focused almost exclusively on independent entity updates or static memory evaluations; critical aspects such as reasoning over dependencies, handling cascades of updates, deletions, and signifying uncertainty after knowledge invalidation have not been quantitatively evaluated.
The MEME benchmark (Multi-entity and Evolving Memory Evaluation) offers a rigorous evaluation framework covering the cross-product of two orthogonal memory dimensions: entity scope (single vs. multi-entity) and temporal dynamics (static vs. evolving). This taxonomy provides six atomic memory-intensive tasks: Exact Recall, Aggregation, Tracking, Deletion, Cascade, and Absence.
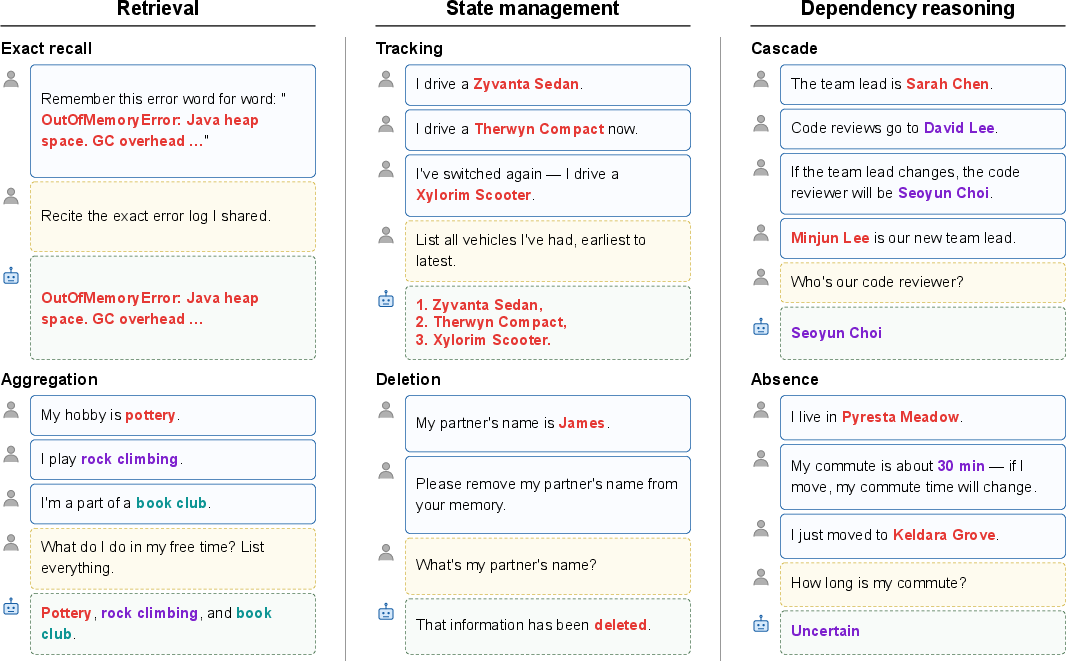
Figure 1: Examples of the six MEME task types across three categories: Left: Retrieval (Exact Recall, Aggregation), Middle: State Management (Tracking, Deletion), Right: Dependency Reasoning (Cascade, Absence).
Each task isolates a key operation required for stateful, dependency-aware dialogue agents:
- Retrieval: Exact Recall (verbatim reproduction), Aggregation (multi-entity synthesis)
- State Management: Tracking (chronological revision), Deletion (post-removal query)
- Dependency Reasoning: Cascade (propagation of upstream changes), Absence (uncertainty post-removal of supporting fact)
A Directed Acyclic Graph (DAG)-based knowledge graph underpins controlled episode generation across two domains (Personal Life, Software Project), guaranteeing gold-truth answers for each dependency chain.
Evaluation Protocol and Systems
Six representative memory systems, spanning raw retrieval (BM25, dense semantic), LLM-processed memory (Mem0, Graphiti), and file-based agentic storage (Karpathy Wiki, MD-flat), are benchmarked on 100 episodes. Each episode embeds up to ~35K tokens in conversational context, heavily interleaved with filler to test memory scaling and irrelevant/noisy input robustness.
The evaluation pipeline distinguishes between (i) encoding (storing facts/rules), (ii) maintenance (state retention), (iii) retrieval (context surfacing), and (iv) answer generation (final output). Role separation between internal (tooling/planning) and answering (response synthesis) LLMs ensures architectural effects are not conflated with model capacity. Uniform prompts and automated GPT-4o-based judging anchor evaluation reliability.
Empirical Results and Analysis
Dependency Reasoning Failure Modes
All practical-cost memory configurations exhibit catastrophic failure on the Cascade (average 3% accuracy) and Absence (1%) tasks, independent of retrieval or LLM paradigm. By contrast, static recall and tracking tasks yield substantially higher scores.
Ablative studies uncover that the encoding and maintenance phases typically retain both dependency rules and update events. However, retrieval pipelines often fail to surface change events, either due to top-k ranking placing outdated facts above relevant updates (vector retrievers), or due to agent execution policy never accessing the event logs (tool-based systems). Even when both rule and change events are in the retrieval context, current answering LLMs frequently fail to perform the required dependency resolution, continuing to output stale/incorrect values.
Failure Case Illustration
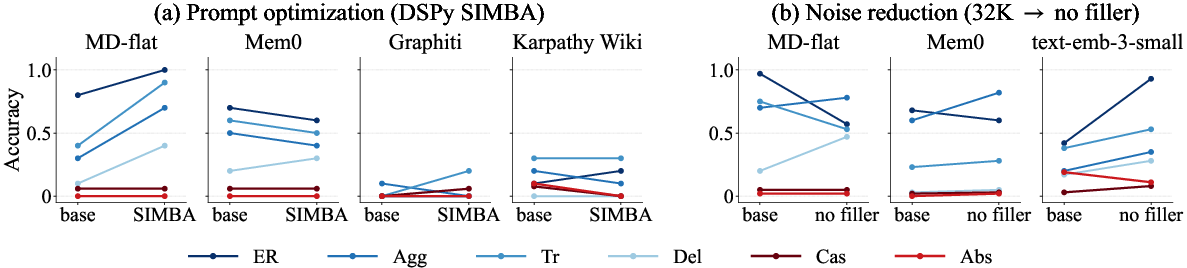
Figure 2: Two interventions external to the memory architecture: (a) prompt optimization (DSPy SIMBA), (b) noise reduction (removal of fillers). Cas/Abs (red lines) accuracy remains at floor, indicating non-recoverability through these interventions.
Prompt optimizations (using DSPy SIMBA), retrieval depth increases, utilizing stronger answering LLMs, and reducing input noise volume all fail to significantly improve Cascade or Absence performance. This indicates a fundamental representational and reasoning bottleneck rather than instructional or capacity limitations.
Success Case and Cost Barriers
The only configuration achieving substantial improvements on dependency tasks is a file-based agent (MD-flat) paired with Claude Opus 4.7 as its internal LLM. Opus 4.7 both explicitly structures memory to encode contingent dependencies and propagates changes by proactively updating downstream facts at ingestion. This yields Cascade accuracy of 32% and Absence of 59%, but increases per-episode compute cost by ∼70× compared to baseline, and degrades tasks sensitive to verbatim or historical recall due to its aggressive memory restructuring.
Theoretical and Practical Implications
The failure of all practical-cost systems on dependency reasoning tasks identifies a critical unsolved challenge for persistent agentic LLM deployments, particularly in scenarios requiring robust propagation of updates and explicit handling of knowledge uncertainty. These results emphasize that:
- Architectural changes alone are insufficient: Bottlenecks are present both in retriever ranking/logical access and in answer-generation reasoning, requiring joint advances.
- LLM capacity scaling alone is not a panacea: Frontier LLMs (e.g., Opus 4.7) partially close the gap only via aggressive, costly memory rewriting and with negative impact on other tasks.
- Principled propagation mechanisms are needed: Reliance on LLM inference at ingestion for update propagation is cost-prohibitive. Architectures that natively synchronize related entities' states and maintain uncertainty are necessary for scalable, robust agentic memory.
For longitudinal agent design, the results suggest that cost-efficient deployment in dependency-heavy environments is not feasible with existing memory paradigms. As short-term mitigations, explicit upstream design (recording dependency rules directly in dialogue) may help but is non-scalable and non-generalizable.
For theoretical advances, MEME provides a diagnostic substrate for quantifying progress, enforcing benchmarks on (i) multi-entity, (ii) evolving, and (iii) dependency-aware memory.
Future Directions
Several research avenues are motivated by these findings:
- Native propagation modules: Graph-based or logic-programming-inspired middle layers capable of routing and updating dependent states post-ingest, decoupled from heavyweight LLM inference.
- Hybrid retrieval-reasoning architectures: Integration of symbolic dependency tracking with dense retriever layers to enable scalable, update-propagating memory.
- Explicit uncertainty signaling: Developing representations and answering mechanisms that robustly output “I don’t know” or abstain in settings where knowledge has become invalidated.
- Externalized reasoning traces: Providing retrieval-stage justifications and explicit state transitions for auditability and downstream reasoning transparency.
MEME’s DAG-based schema, controlled dialogue synthesis, and diagnostic coverage of core memory sub-tasks anchor future architecture and evaluation research pipelines.
Conclusion
MEME establishes that current cost-efficient LLM-based agent memory systems fundamentally fail at dependency reasoning tasks crucial to persistent, stateful AI applications. Achieving true multi-entity, evolving memory—particularly under resource constraints—demands principled innovations in architectural memory design far beyond retriever/LLM/hardware scaling alone. MEME offers the evaluation infrastructure to drive and measure those advances going forward (2605.12477).

