- The paper presents a modular architecture that decouples memory from reasoning, enabling continual updates without costly retraining.
- It introduces a dedicated compact Memory model trained on synthesized reflection QA datasets to internalize and verify new corpus knowledge.
- Empirical results on benchmarks like NarrativeQA and MuSiQue show robust multi-hop reasoning and scalability with minimal retrieval noise.
Memory as a Model: Modular Knowledge Integration for LLMs
Framework Overview and Motivation
LLMs remain statically frozen post-pretraining, which results in rapidly outdated internal knowledge and substantial limitations for domains demanding timely and domain-specific information. Retraining at frontier scale is computationally prohibitive, motivating a need for efficient architectural alternatives that support continual knowledge integration without expensive parameter updates, catastrophic forgetting, or reliance on model internals.
MeMo (Memory as a Model) addresses this by introducing a modular two-model architecture: a dedicated, compact Memory is trained to internalize new corpus knowledge, while a frozen Executive (LLM) queries the Memory via structured, multi-turn protocols. This setup bypasses context window constraints and retrieval noise sensitivities that plague non-parametric methods, circumvents catastrophic forgetting, and avoids representation coupling seen in prior latent memory approaches. MeMo enables plug-and-play deployment with both open and proprietary LLMs, and incurs retrieval cost independent of corpus size—critical for scalable, real-world integration scenarios.
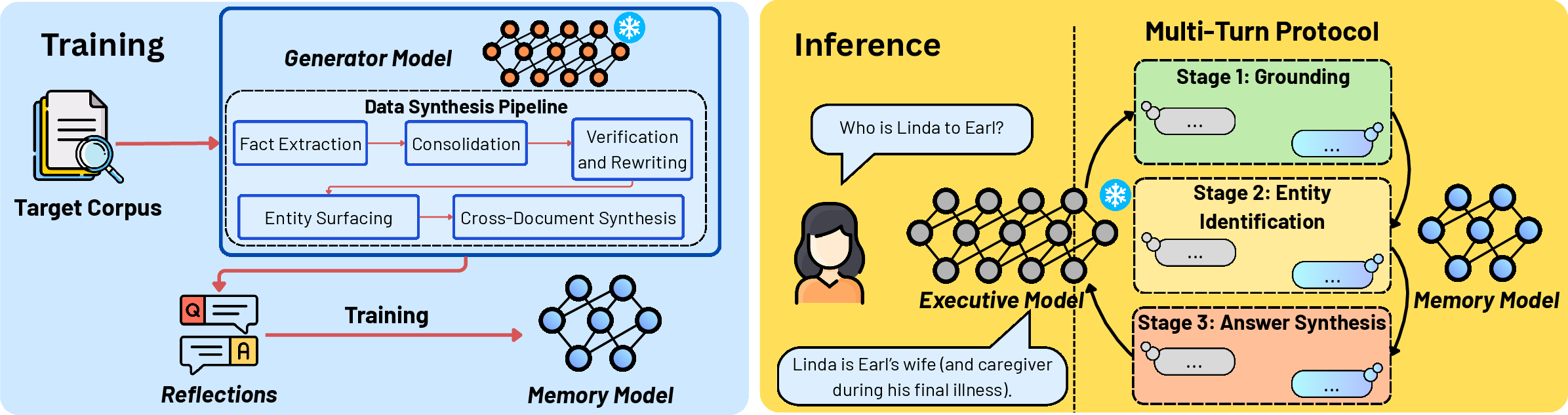
Figure 1: Overview of the training and inference pipeline of MeMo, showing modular Memory training and structured Executive interaction.
Data Synthesis and Memory Training
MeMo’s knowledge integration relies fundamentally on reflection QA datasets generated through a rigorous five-step synthesis pipeline:
- Fact Extraction: Parallel direct/indirect extraction ensures raw and inferred facts are distilled from document chunks.
- Consolidation: Redundant and compositional QA pairs are merged to represent cross-fact relationships.
- Verification/Rewriting: QA pairs are enforced to be self-contained, eliminating ambiguities and context dependencies.
- Entity Surfacing: Entity-centric queries train Memory to resolve entity identification from indirect descriptions, addressing reversal curse.
- Cross-Document Synthesis: Topically grouped chunks yield cross-document QA pairs reflecting convergent evidence and comparative properties.
Supervised fine-tuning of Memory on these datasets ensures parametric internalization of corpus facts and relationships, forcing generalization over unseen queries and complex reasoning requirements.
Inference-Time Integration and Multi-Turn Protocol
At inference, MeMo’s structured multi-turn protocol decomposes complex queries into sequential sub-questions. Executive executes three stages:
- Grounding: Atomic probing of constraints for contextual grounding.
- Entity Identification: Iterative sub-querying to isolate candidate entities.
- Answer Seeking/Synthesis: Targeted retrieval conditioned on entity context, accumulating evidence for final reasoning.
All interactions treat Memory as a black-box knowledge oracle. Thus, MeMo maintains constant-time retrieval and model compatibility across LLM families, agnostic to model internals and corpus size.
MeMo achieves superior accuracy on NarrativeQA and MuSiQue—benchmarks demanding multi-hop and cross-document reasoning—outperforming retrieval baselines (BM25, NV-Embed-V2, HippoRAG2, Cartridges) and exhibiting marked gains when paired with stronger Executives (e.g., Gemini-3-Flash over Qwen2.5-32B-Instruct).
Ablation studies confirm MeMo’s robustness to retrieval noise: unlike RAG baselines, MeMo’s performance remains virtually unchanged with increased distractor documents, attributed to Executive’s ability to retrieve targeted knowledge from a compact, high-precision Memory.
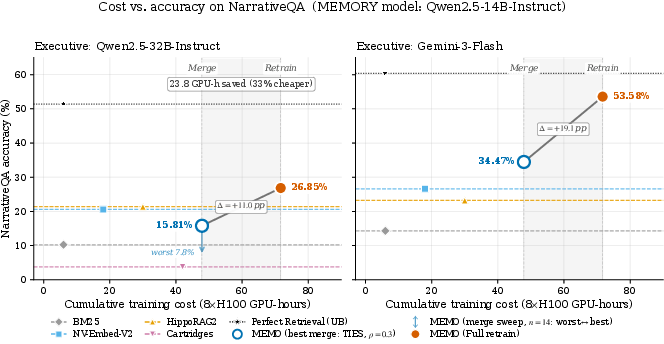
Figure 2: Cost–accuracy trade-off on NarrativeQA as a second corpus arrives; model merging substantially reduces computation.
Scaling experiments demonstrate positive accuracy trends with larger Memory sizes, with task-dependent interaction patterns between Memory scale and Executive reasoning capability. Cross-family ablations highlight that Memory's compressed knowledge representation generalizes well across divergent transformer architectures, confirming architectural independence.
Continual Knowledge Integration via Model Merging
MeMo explores modular integration through parameter-space model merging. Task vector arithmetic (e.g., TIES, DARE), sparsification, and sign-conflict resolution effectively preserve knowledge across disjoint corpora at a fraction of the compute cost of full retraining (Θ(K) vs. Θ(K2) scaling). While merging incurs accuracy trade-offs (e.g., $11$–$19$ percentage points lower), merged Memory modules consistently outperform retrieval baselines, offering a strong practical trade-off for real-world incremental deployment.
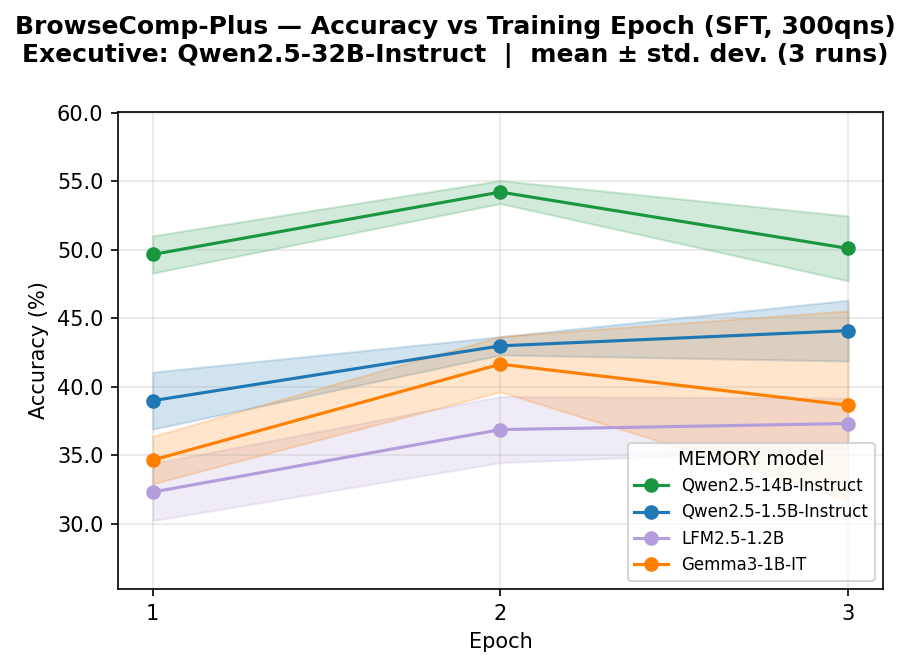
Figure 3: BrowseComp-Plus accuracy as a function of training epoch for different Memory sizes and families.
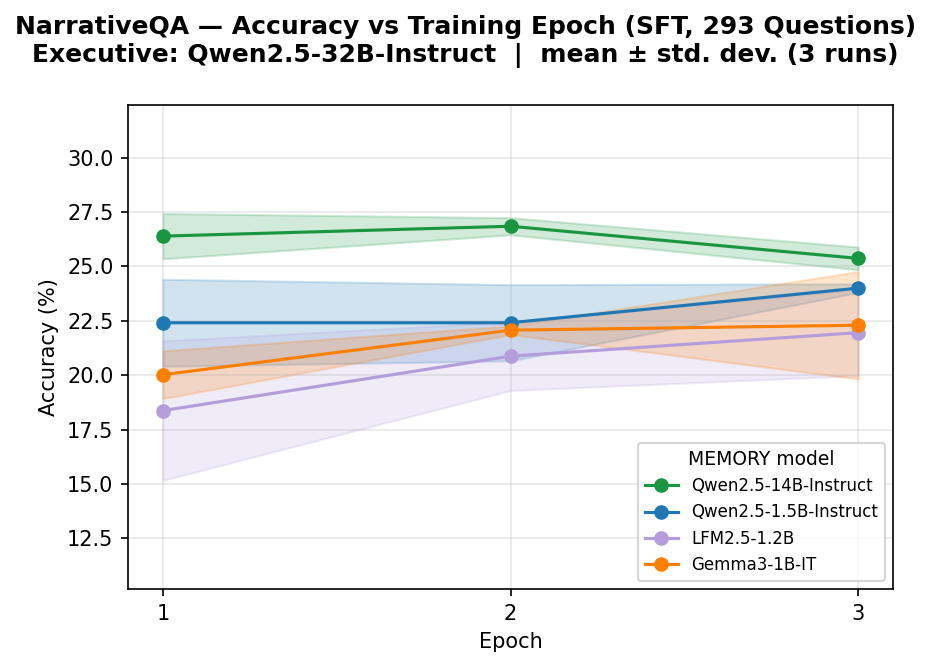
Figure 4: NarrativeQA accuracy trends over epochs, illustrating saturation and generalization.
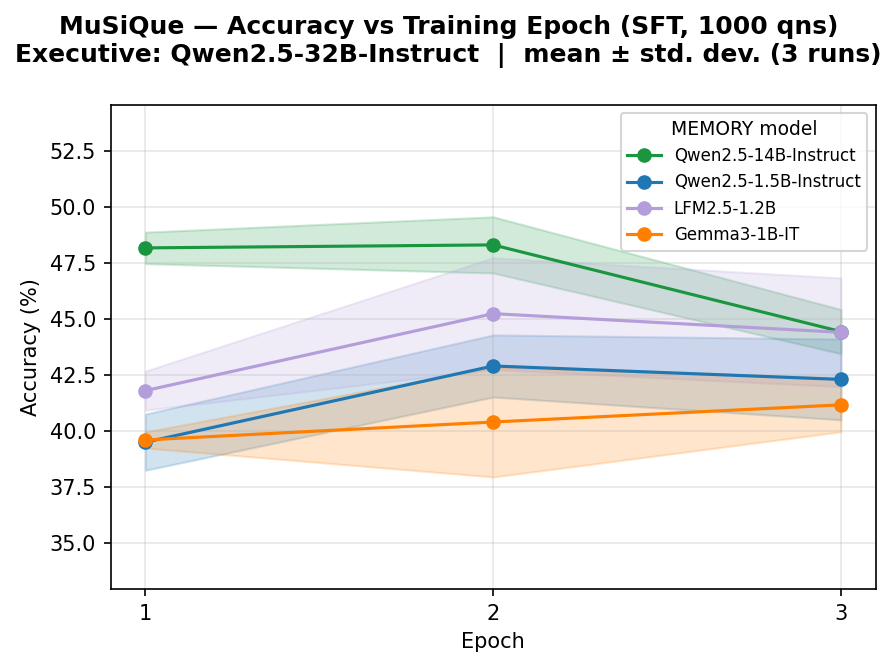
Figure 5: MuSiQue accuracy versus training epoch, highlighting the impact of Memory scale and architectural diversity.
Practical and Theoretical Implications
MeMo provides a scalable modular solution for knowledge integration with guaranteed compatibility across LLM APIs, supporting both open and closed-source models. Its data synthesis pipeline and inference protocol enable high-fidelity cross-document reasoning and compositional fact retrieval, overcoming context bottlenecks and retrieval noise inherent to RAG systems. The framework's independence from LLM internals and model-specific representations makes it suitable for deployment in computationally constrained and proprietary settings.
Theoretically, MeMo exemplifies a robust decoupling of memory from reasoning, providing a path toward more flexible, updatable, and knowledge-aware AI systems, and facilitating continual integration at operational scale. Empirical validations and ablations substantiate its superiority on core knowledge-intensive benchmarks and its resilience to retrieval-induced noise.
Conclusion
MeMo establishes a modular architecture for knowledge integration in LLMs by training dedicated Memory models on synthesized reflection QA datasets and deploying a structured, multi-turn inference protocol for Executive interaction. The approach demonstrates clear advantages over traditional retrieval and parametric finetuning methods, supporting continual updates, plug-and-play deployment, and robust performance across diverse benchmarks. MeMo's principles lay the groundwork for scalable, adaptable AI systems capable of timely and domain-specific reasoning, with future research directions centering on efficiency in memory construction, streamlining incremental integration, and augmenting Executive–Memory coordination.