- The paper introduces the K2V framework, integrating knowledge graph-based data synthesis with checklist verification to overcome reward sparsity in open-ended tasks.
- It demonstrates that small LLMs trained via K2V can match or outperform larger models by leveraging dense, process-level rewards.
- Empirical analyses across agriculture, law, and medicine show improved accuracy and stable training dynamics while preserving general reasoning skills.
Knowledge-to-Verification: Extending RLVR for LLMs in Knowledge-Intensive Domains
Motivation and Problem Statement
The paradigm of Reinforcement Learning with Verifiable Rewards (RLVR) has catalyzed advances in mathematical and coding reasoning for LLMs. However, RLVR regimes in knowledge-intensive domains have seen limited deployment due to two predominant bottlenecks: (1) the lack of high-quality, verifiable data and (2) reward sparsity, as most RLVR implementations focus exclusively on answer correctness, omitting process-level verification. Answer verifiability is trivial in formal domains, but non-trivial for open-ended, text-based knowledge tasks, where rule-based or executable verification is infeasible and dataset synthesis remains bottlenecked by manual annotation.
K2V Framework: Methodological Architecture
K2V introduces a scalable RLVR methodology that integrates automated data synthesis and reasoning verification to circumvent the aforementioned limitations. The workflow comprises several principal stages:
- Knowledge Graph Construction and Quintuple Sampling Unstructured domain corpora are processed using LLM-driven named entity recognition (NER) and relation extraction (RE). Entities and relations are systematically assembled into a domain-specific knowledge graph (KG), enabling structural grounding.
- Fill-Blank Style QA Pair Synthesis
Unlike classical KG completion (KGC) operating on triples, K2V samples quintuples to ensure expanded context and reasoning depth. Random masking of entities within quintuples yields masked KG paths, subsequently converted into fill-blank style questions via a text-to-question LLM. The masked entity label provides an objective ground truth.
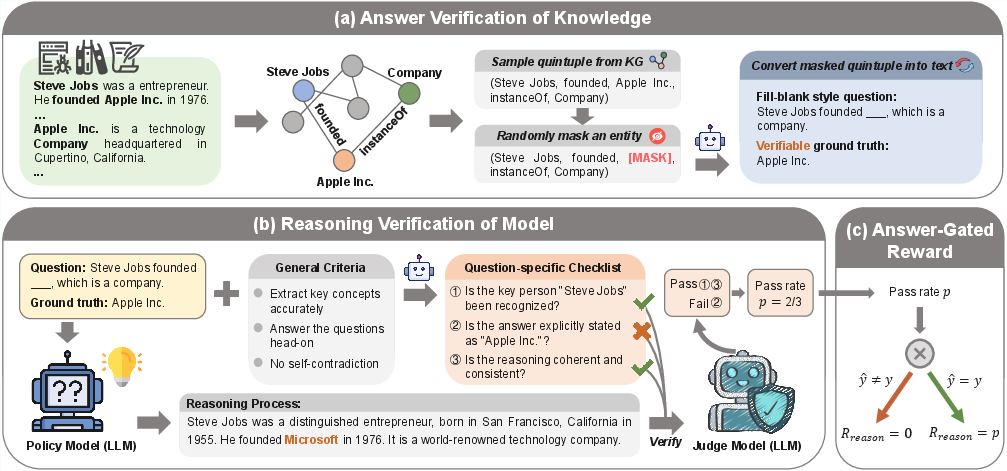
Figure 1: An overview of K2V: KG construction, quintuple sampling and masking, question synthesis, checklist-based reasoning verification, and answer-gated reward integration.
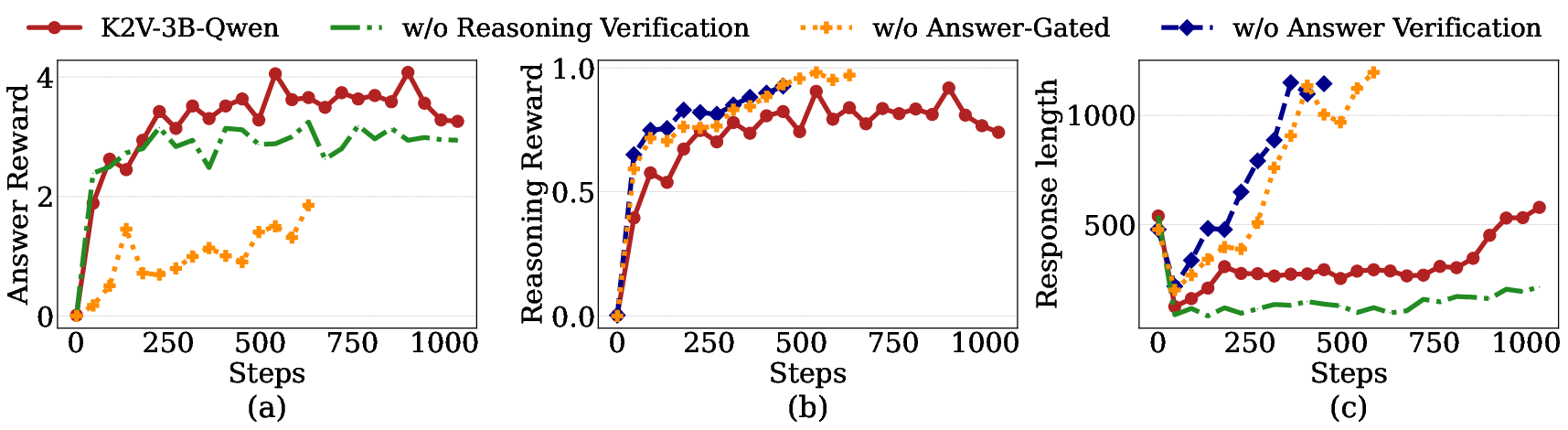
- Checklist-Based Reasoning Verification Direct reasoning verification remains intractable, given the length and open-ended nature of reasoning traces. K2V decomposes the verification process by synthesizing a question-specific, binary checklist instantiated from general criteria (e.g., factuality, logical progression, coverage). A judge LLM scores each reasoning trace against checklist items, with the pass rate serving as a dense reward signal.
- Answer-Gated Reward Integration To prevent reward hacking and anchor logical fidelity to factual accuracy, reasoning rewards are issued only if the predicted answer matches the reference. The total reward—comprising format, answer, and reasoning components—ensures proper structural outputs, process-level coherence, and factual correctness.
Empirical Results and Ablation Analyses
Extensive experimentation was conducted on agriculture, law, and medicine domains using multiple open-source backbones (Qwen2.5-3B/7B, Llama3.2-3B-Instruct, Llama3.1-8B-Instruct). K2V consistently achieved superior accuracy relative to RLVR-capable baselines such as Liquid, Genie, Synthetic Data RL, and BDS.
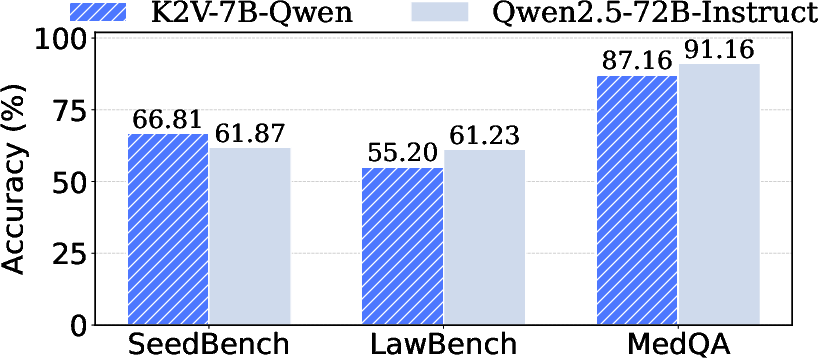
Figure 2: Accuracy comparison: K2V-7B-Qwen outperforms Qwen2.5-72B-Instruct in knowledge-intensive tasks, demonstrating strong efficiency scaling.
Key findings include:
Qualitative Analysis: Checklist-Guided Reasoning and Data Synthesis
Case studies in high-complexity medical questions illustrate the necessity of checklist-based verification. Checklists prompt models to articulate critical, relevant logical chains, enforcing depth and completeness beyond simple fact retrieval.

Figure 4: K2V-generated QA and checklist in clinical genomics, requiring both accurate identification of genes and biological function exposition.
Additional comparative samples indicate that alternative baselines (Liquid, Genie, SDR, BDS) are limited in either context richness or verifiability. Liquid and Genie questions are predominantly shallow or conversational, SDR yields single-step logic, and BDS’s multiple-choice structure is highly verifiable but less conducive to chain-of-thought reasoning.

Figure 5: Liquid-synthesized QA pairs with multiple candidate answers, highlighting lack of contextual and logical depth.
Practical and Theoretical Implications
K2V demonstrates RLVR generalizability across open-ended, text-based domains previously intractable to reward-based optimization. The integration of KG-structured data, fill-blank QA synthesis, and process-level verification enables scalable and automated creation of dense reward landscapes for RLVR regimes in knowledge-intensive settings.
Implications include:
- Generalization and Efficiency: Transfer of RLVR from formal to open-ended domains unlocks cross-domain generalization, evidenced by negligible loss in general reasoning when training for specialized tasks.
- Reward Engineering: Checklist-based verification systems modularize complex reasoning tasks into binary-verifiable subtasks, mitigating reward sparsity and facilitating stable policy optimization.
- Data Synthesis: KG-driven synthesis allows efficient, scalable creation of high-quality QA/reasoning datasets—independent of manual annotation—and supports robust model scaling, even with smaller LLM generators.
The framework is extensible to other knowledge-driven domains, and is robust to generator size, as demonstrated by minimal accuracy drop with reduced generator capacity.
Future Directions
The authors highlight limitations regarding model scale and domain breadth, noting experiments focus on small-to-medium models and only three knowledge-intensive verticals. There is substantial potential to unify RLVR across formal and open-ended domains and to extend checklist-style reward engineering to multimodal verification.
Conclusion
K2V operationalizes RLVR in domains previously resistant to verifiable reward optimization by exploiting structured data synthesis, dense reward signals, and answer-gated reward coupling. Comprehensive experiments, ablations, and qualitative analyses confirm its effectiveness, scalability, and generalization—establishing K2V as an authoritative approach for RLVR in knowledge-centric LLM training (2605.18261).