- The paper reveals that language pretraining constructs a reusable sequential manifold that accelerates time-series forecasting via low-rank adaptation.
- Empirical results demonstrate that language-pretrained models converge faster and achieve lower early errors compared to randomly initialized models.
- Analysis of gradient alignment and linear probing indicates that pretrained representations yield interpretable temporal features, enhancing forecasting performance.
Geometric Mechanisms Underlying Cross-Modal Transfer from LLMs to Time Series
Introduction
The paper "LLM Pretraining Shapes a Generalizable Manifold: Insights into Cross-Modal Transfer to Time Series" (2605.20449) presents a comprehensive investigation into the geometric mechanisms that enable LLMs, specifically transformers pretrained on language, to transfer effectively to time-series forecasting tasks. By reframing language pretraining as the construction of a sequential manifold encompassing reusable temporal primitives—rather than pure acquisition of semantic information—the authors provide an incisive theoretical and empirical framework. The manuscript addresses the nature of inductive biases introduced by language pretraining and why these biases lead to rapid, data-efficient adaptation to new modalities such as time series.
Cross-Modal Transfer: Empirical Characterization
A critical empirical finding is that language-pretrained transformer models exhibit a significant optimization advantage in time-series forecasting compared to randomly initialized equivalents, regardless of the adaptation regime (full finetuning, IO-only, or parameter-efficient LoRA-based adaptation). Language-pretrained models converge faster and achieve lower error early during training across all principal metrics.
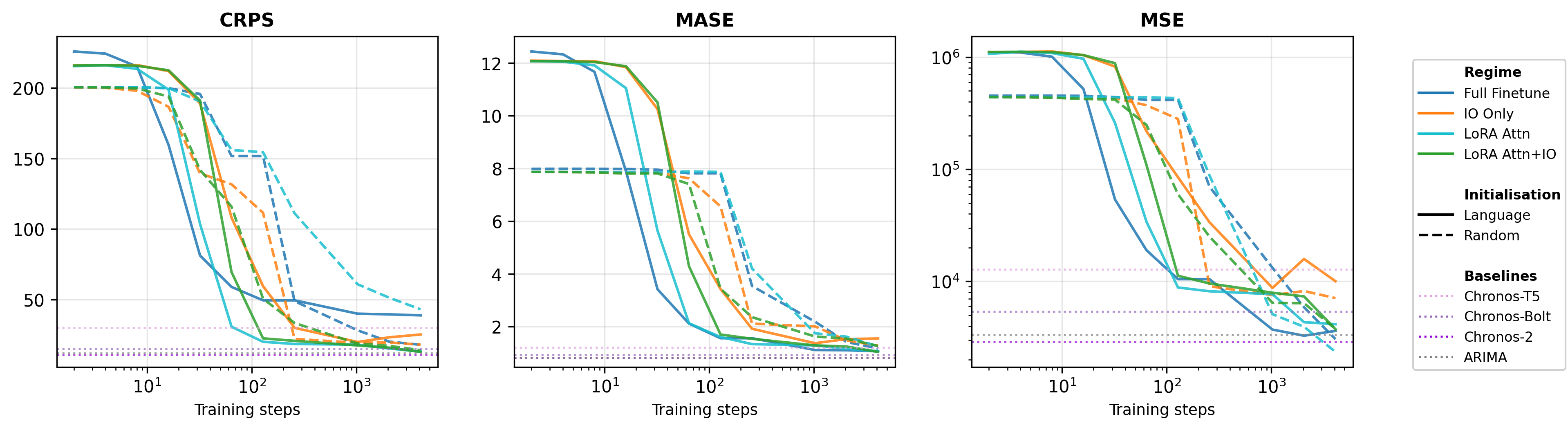
Figure 1: Language-pretrained models converge faster and to lower error across all adaptation regimes compared to random initialization; LoRA-based methods match full finetuning.
Both single-step and long-horizon metrics (e.g., CRPS, MASE, MSE for h=1 and h=64) demonstrate that the performance gap is most pronounced in the first 100 optimization steps, but the final performance is similar after sufficient training. This supports the hypothesis that language pretraining does not necessarily alter the ultimate attainable solution, but drastically accelerates access to beneficial regions of the loss landscape by preconditioning optimization.
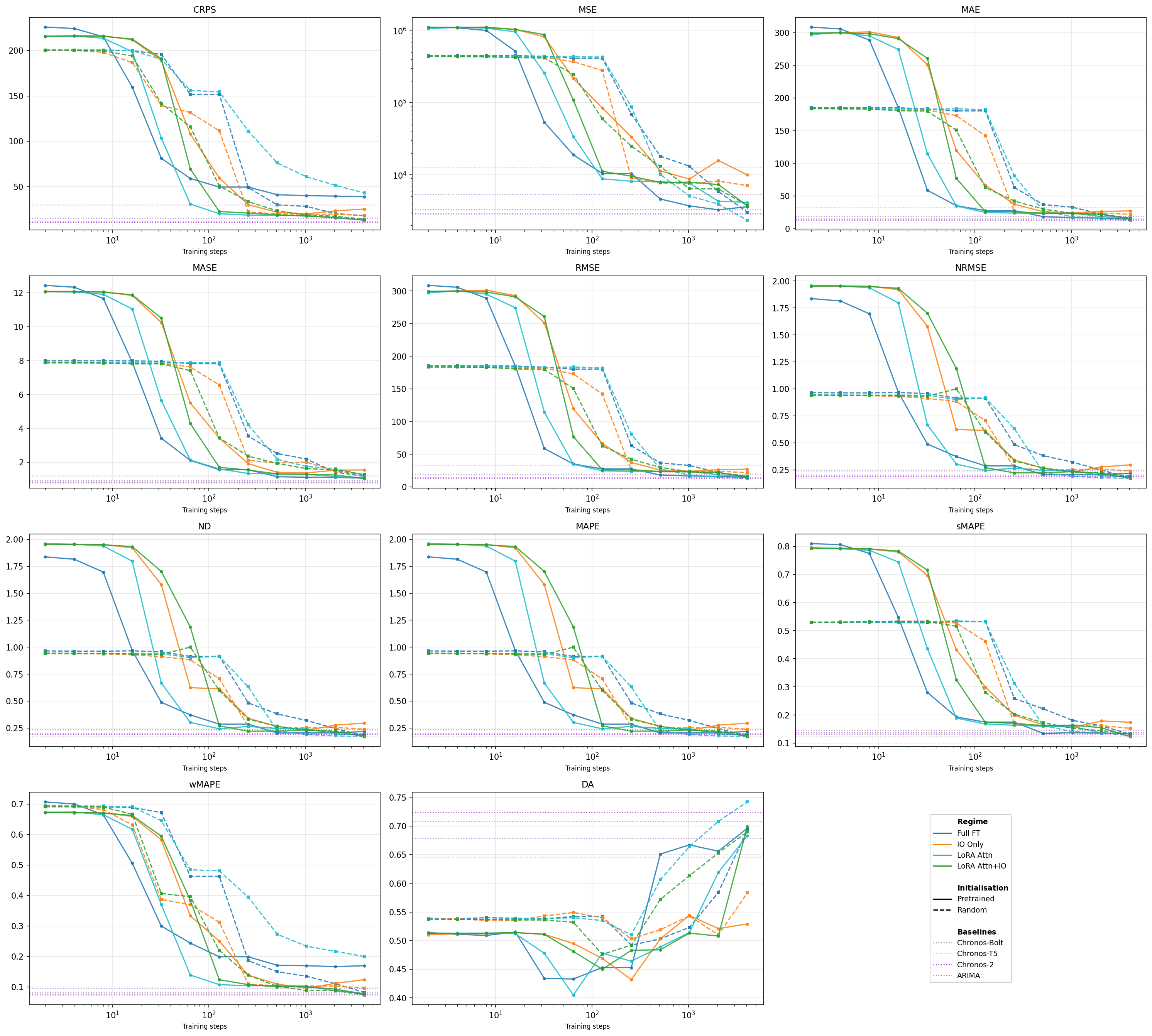
Figure 3: Faster convergence in all h=1 metrics for language-initialized models; the gap reduces after extended training but is substantial during early optimization.
Geometric Manifold View and Linear Probing Results
The core conceptual advance is the proposition that language pretraining constructs a structural manifold in representation space that encodes generic sequential patterns, such as trends, periodicities, and regime changes. To validate this, the authors deploy linear probing, revealing that a fixed, frozen LLM, when linearly projected, can decode realistic time-series trajectories from WikiText representations without explicit supervision or paired data.
This is achieved by training a linear decoder to map concatenated hidden states from all LLM layers to real time-series subsequences. The decoded outputs demonstrate shape-level similarity and significant diversity, with over one-third of projections matching uniquely to a real time series from a large, unpaired database. Ablation experiments decisively show that both the pretrained weights and semantically coherent input sequences are necessary and sufficient for the emergence of this structure; neither the architecture nor the input alone is adequate.
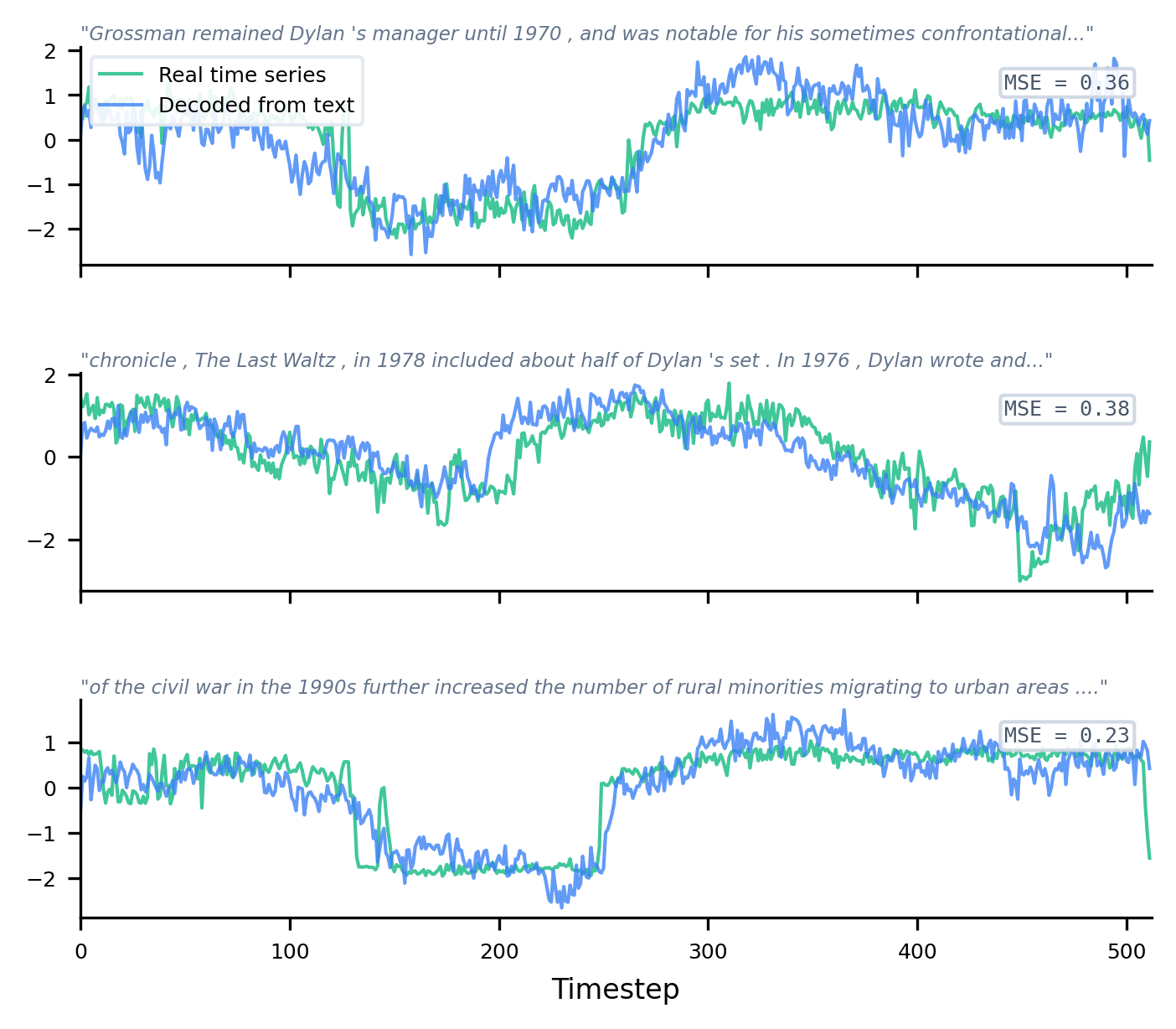
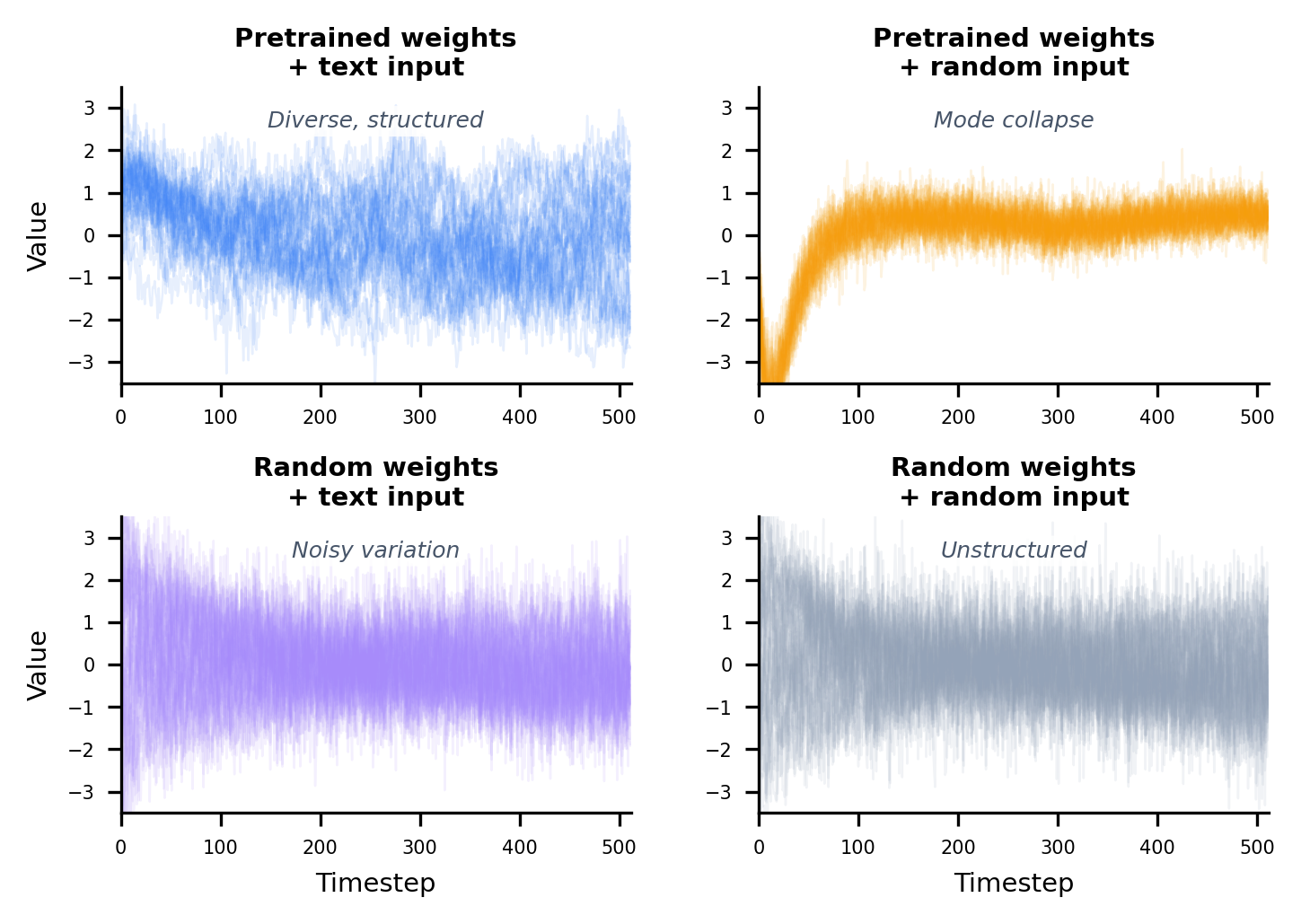
Figure 4: Decoded time series linear projections from frozen pretrained LLM hidden states substantially overlap with real diverse time series samples.
Retrieval-Based Forecasting and Manifold Predictivity
The authors further show that these manifold projections are not only structurally similar but can be utilized for actual forecasting. By retrieving the most similar WikiText-induced trajectory to the observed portion of a time series and using its continuation for prediction, the approach yields lower median MSE than naive baselines, especially where there are pronounced trends or level shifts.
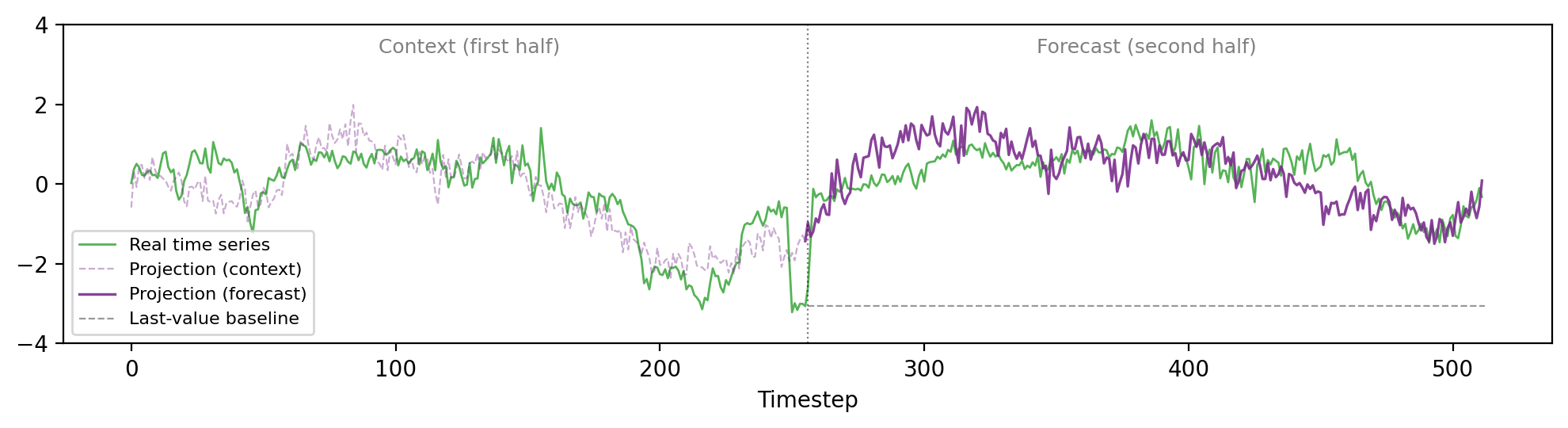
Figure 5: Retrieval-based forecasting using projected hidden states captures trends and level shifts, outperforming naive baselines when structure exists.
These results suggest that the LLM's representation manifold contains directions that correspond to meaningful temporal dynamics before any time-series-specific training—a central assertion of the "shared manifold hypothesis."
Optimization Geometry: Gradient Alignment and Low-Rank Adaptation
A crucial mechanistic insight is the identification of coherent, highly aligned gradient signals in the language-pretrained models from the very first training step, in contrast to the initially destructive gradient interference observed in the random-initialization regime. This leads to immediate loss decrease and confirms that language pretraining not only provides inductive bias but also aligns the optimization landscape for time-series objectives.
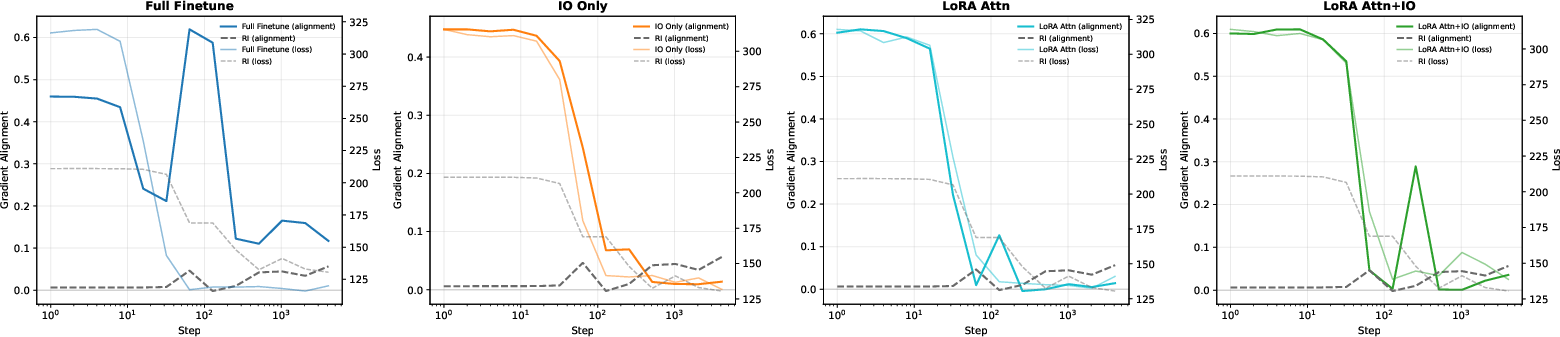
Figure 6: Language pretraining produces highly coherent, aligned gradients for time-series objectives from the outset, in contrast to random initialization.
Moreover, the finetuning process is demonstrated to be low-rank. LoRA-style adaptations concentrating on the attention subspace recapitulate nearly all of the benefits of full finetuning, indicating that adaptation amounts to subspace selection and minor realignment rather than wholesale representational reconstruction. This is reinforced by the metrics of "effective data transfer," where pretrained + LoRA finetuning saves several factors of optimization steps over random initialization for equivalent validation loss.
Representational Dynamics: Effective Rank and Phase Structure
Detailed analysis of the hidden-state covariance evolution reveals that randomly initialized models undergo rapid and dramatic effective-rank collapse in all layers, corresponding to the construction of a new, low-dimensional subspace optimized for temporal prediction. In contrast, language-pretrained models start with already compressed representations that further undergo selective, layer-dependent modularity changes, particularly in the middle layers. The effective rank of text representations in these models exhibits catastrophic forgetting, elucidating that the model's available representational capacity is adaptively reallocated for the new modality.
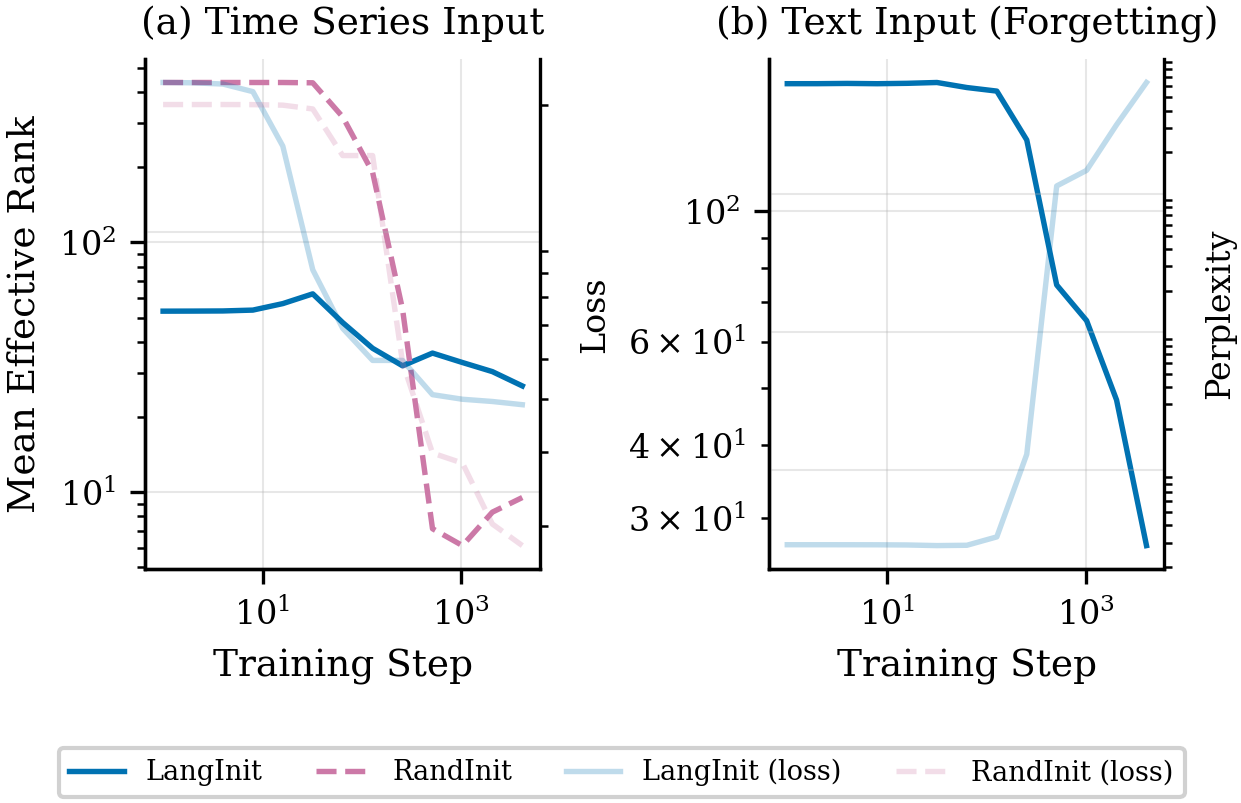
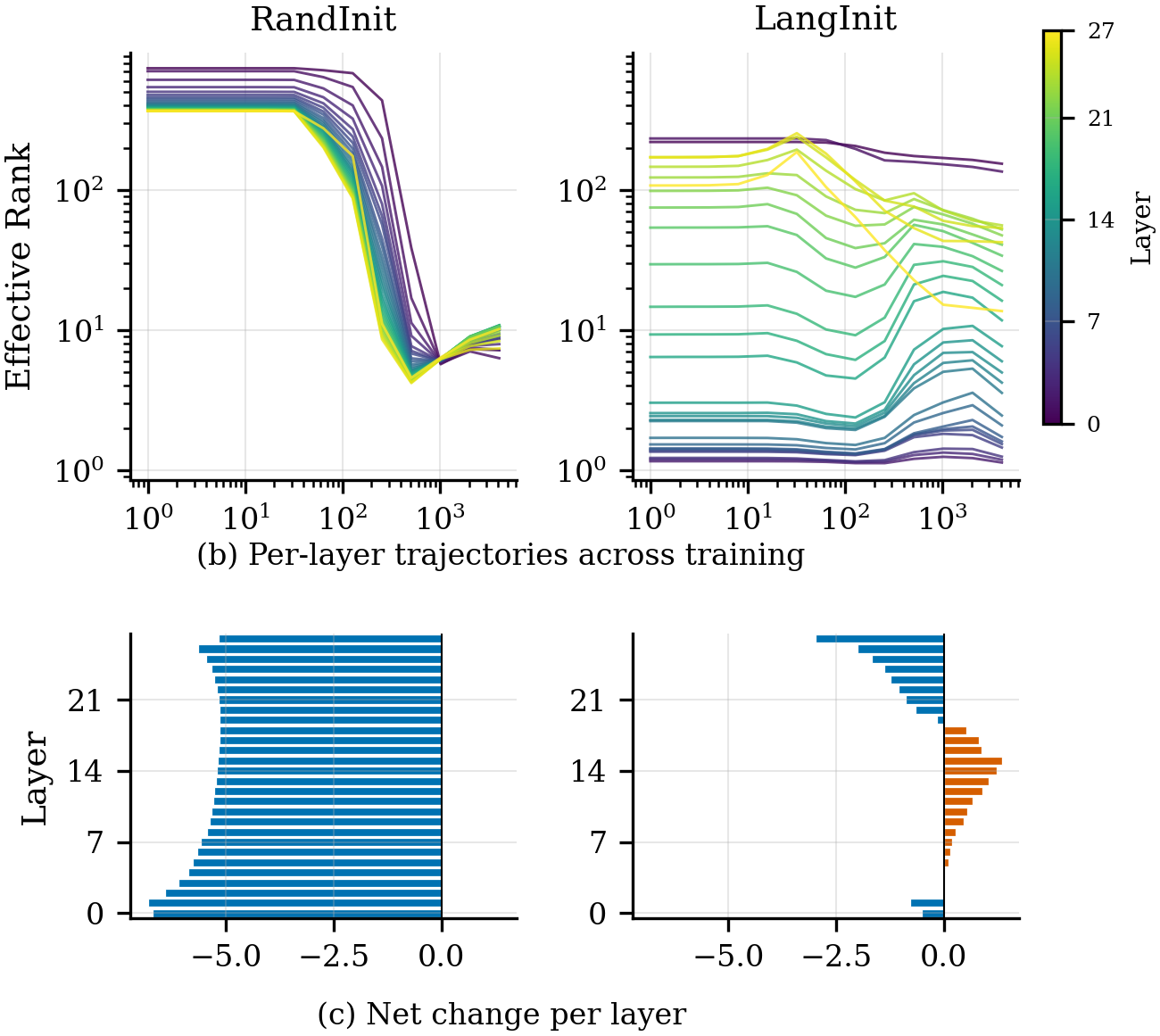
Figure 7: Effective rank dynamics show isotropic-to-collapsed transitions in random-initialized models, while language-pretrained models selectively compress and redistribute variance.
Synthetic probes using periodic, trend, and oscillatory signals establish that language-pretrained models encode input phase and structure with greater geometric complexity and lower principal component variance than their randomly initialized counterparts, which form simpler low-dimensional curves after training. The comparative geometric analysis (PCA, t-SNE, and CKA) indicates that while both optimization approaches recover usable temporal representations, the pretrained models inherit and repurpose a richer, layered, and nonlinear manifold.
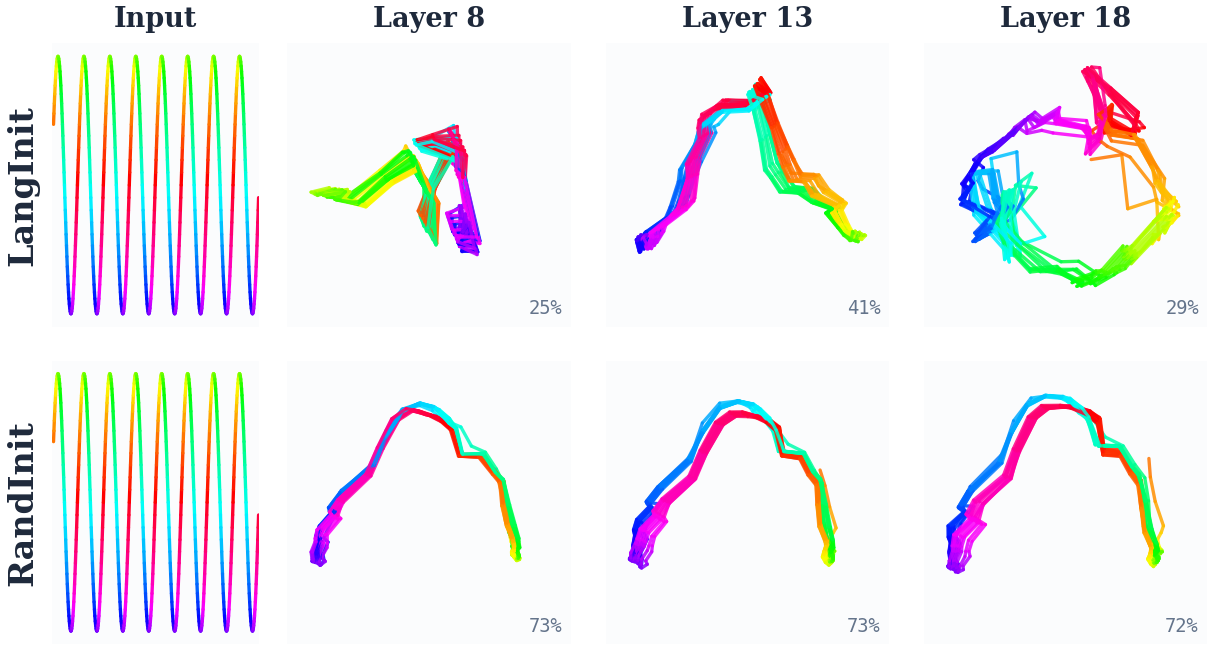
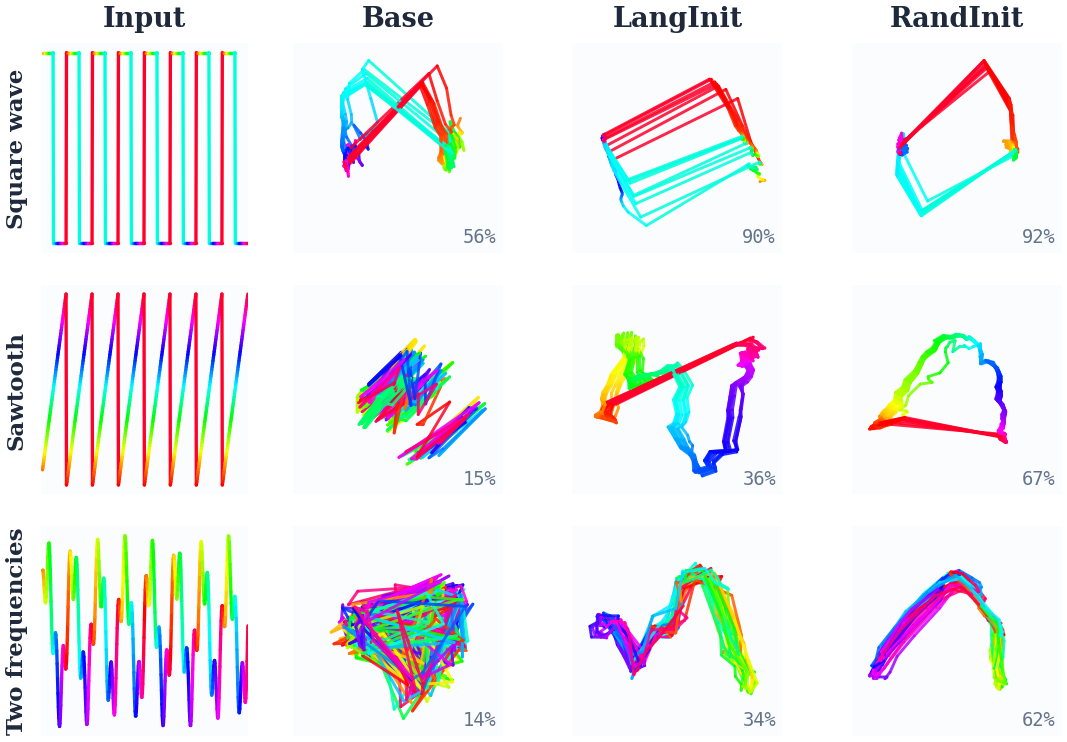
Figure 8: LangInit (pretrained) produces heterogeneous, complex but structured representations across layers and input types; RandInit converges to simple, low-dimensional geometries.
Interpretable Features and Subspace Analysis
The research goes further to identify interpretable temporal features within the cross-modal transfer subspace. Using sparsity-driven crosscoders, the authors find that shared latent features are localized within particular layers (notably 7–10) and correspond both to characteristic time-series motifs (e.g., magnitude jumps, regime-switching, isolated spikes, missing data) and to coherent WikiText genres such as measurement-heavy or repetitive passages.
(Figures 17–19)
Figure 2: Interpretable cross-modal features fire for analogous time-series motifs and textual genres, evidencing aligned abstract temporal primitives.
Additionally, preliminary causal circuit ablation identifies specific model components (e.g., Layer 1 head 4 and MLP) critical for periodic time-series prediction and for language sequences exhibiting grammatical repetition or regular templates.
Implications and Theoretical Significance
The findings have strong implications for both theory and practice in representation learning and cross-modal transfer. The consistent observation is that LLMs transfer not by imparting semantic or lexical knowledge but by providing access to a geometric manifold structured over generic sequential statistics. Consequently, the adaptation to new modalities is mathematically and algorithmically low-rank, explainable as a process of direction selection rather than structural invention. This confirms and operationalizes the "Platonic Representation Hypothesis" in the context of temporally autoregressive transformers.
Practically, these results provide a principled rationale for the empirical efficacy of low-rank finetuning (e.g., LoRA), especially in data-constrained or distribution-shift contexts, and motivate further research into more general and scalable cross-modal transfer mechanisms based on manifold structure rather than content knowledge.
Limitations and Future Directions
The study is limited to a single backbone (Qwen3-0.6B), dataset (GiftEval), and discretization scheme (uniform binning). The generalizability to larger models, alternate architectures, or different data modalities remains to be shown. The analysis neither isolates whether observed gradient coherence arises solely from manifold geometry or from specific initialization statistics, nor does it exhaustively characterize the entire transferred subspace. The causal evidence for cross-modal feature reuse, while suggestive, is preliminary.
Future research could pursue manifold-centric transfer analyses at larger model scales, including vision and audio modalities, seek circuit-level mechanistic explanations, and develop unified theories of cross-modal adaptation grounded in geometry.
Conclusion
This paper provides a compelling geometric account of why and how language-pretrained transformers transfer efficiently to time-series forecasting: language pretraining builds a reusable manifold of sequential structure, and adaptation operates predominantly via low-dimensional realignment. The convergence of empirical, representational, and mechanistic analyses provides substantive evidence that cross-modal transfer is rooted in shared statistical structure, not in semantic overlap. This perspective recontextualizes the role of pretraining and raises the prospect that any sufficiently rich, sequentially preconditioned model can become a universal backbone for other modalities, provided manifold structure is adequately exploited.