- The paper presents a three-phase framework that transfers high-capacity SLM precision into compact models for efficient sponsored search retrieval.
- It employs teacher-student alignment, progressive pruning, and contrastive refinement to reduce latency by over 27× while preserving retrieval quality.
- Empirical tests on Bing Ads show that a pruned 190M parameter student closely matches a 4B/8B teacher’s precision, offering practical operational benefits.
Introduction and Motivation
The HARNESS-LM (HLM) framework addresses the fundamental production bottleneck in commercial sponsored search retrieval: the need to maximize retrieval precision while minimizing online latency, throughput, and cost. Large SLM-based dual-encoder retrievers, as exemplified by recent Qwen3-Embedding models, establish quality upper bounds but are impractical due to billions of parameters and extravagant GPU requirements at sub-15 ms latency constraints. HLM proposes a decoupling of the offline (document encoder) and online (query encoder) paths, explicitly leveraging the offline/online serving asymmetry by transferring retrieval quality from high-capacity SLMs into deployable, compact student models.
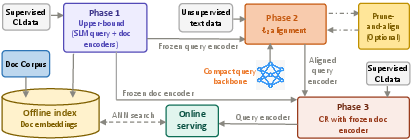
Figure 1: HLM: A three-phase training framework for developing effective and compact SLM retrievers.
Core Framework: Three-Phase Training Recipe
HLM comprises three sequential and modular phases:
1. Teacher Construction:
A symmetric dual-encoder is trained with relaxed constraints using larger SLM backbones (up to 8B parameters) and richer offline-only features (oracle context expansions). The teacher maximizes retrieval precision, serving as the source of semantic representation and defining the upper bound for downstream compression/distillation.
2. Query Encoder Alignment and Compression:
A compact student query encoder, typically <600M parameters, is aligned to the teacher's query embedding space via ℓ2 regression over massive, unlabeled query corpora. The frozen teacher document encoder serves as the retrieval index, while the student is optimized for compatibility in the asymmetric retrieval setup. Further compression is achieved through progressive structured pruning of transformer layers and FFN units, with re-alignment after each step, tracing the quality–latency frontier.
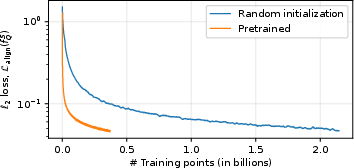
Figure 2: Alignment loss (Eq. ℓ2 regression) as a function of training data, showing convergence rates for pretrained vs. randomly initialized students.
3. Contrastive Refinement (CR):
The aligned student undergoes supervised contrastive learning using query-document pairs, with the teacher document encoder frozen. This phase ensures task-specific discrimination, improving retrieval margins and correcting errors inherited from alignment, yielding further uplift in precision.
Empirical Evaluation and Results
Quality–Latency Trade-off
HLM delivers robust retrieval performance with drastic reductions in latency and deployment cost. On Bing Ads sponsored search benchmarks, the final pruned and contrastively refined 190M parameter student matches the retrieval precision of a 4B/8B teacher (e.g., P@100 of 64.3 vs. 64.8 for Qwen3-8B), with >27× lower online latency ($6.8$ ms vs. $186$ ms) and 20× higher throughput (6,800 vs. 338 queries/sec on A100 GPUs). Progressive pruning preserves most retrieval quality up to 4 transformer layers, with rapid degradation only at extreme compression.
Ablations and Knowledge Transfer
- Teacher Quality Effects: Stronger teachers yield better students, but the transfer gap increases (up to 2.3 absolute P@100 for 8B → 0.6B).
- Alignment Objectives: Direct ℓ2 embedding-level regression vastly outperforms KL-divergence or kernel-matrix alignment, confirming faithful space compatibility as central for asymmetric retrieval.
- Pretraining: Pretrained student checkpoints require an order of magnitude less alignment data and converge faster.
- Feature Richness: Oracle teachers (additional LLM-generated context) can be partially distilled into deployable students, attaining near teacher-level precision.
- Embedding Dimension: Moderate embedding sizes (d=128–$2048$) suffice; further increases show diminishing returns on fine-tuned models.
Superiority of Decoupled Recipe
Naive asymmetric fine-tuning, where the compact query encoder and large document encoder are trained jointly, underperforms HLM by 8–10 P@100. This validates explicit decoupling and sequential transfer: the student absorbs the high-capacity document space via alignment before learning discrimination.
Embedding Space Visualization
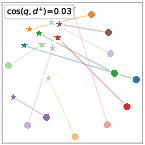

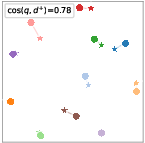
Figure 3: Zero-Shot, Aligned, and Contrastive refinement phases showing 2-D projections of embeddings shifting from dispersed (zero-shot) to tightly compatible (aligned), to discriminative (CR) spaces.
Production Deployment and Online Impact
Large-scale A/B tests on Bing Ads live traffic with the pruned HLM model show:
- Revenue +1%
- Impressions +0.6%
- Clicks +0.4%
all while preserving Quick Back Rate and ad defect rates at baseline. This demonstrates that HLM's models are competitive with, and supersede, the production ensemble under strict latency constraints, delivering tangible business and engagement gains.
Practical and Theoretical Implications
HLM establishes a blueprint for deploying strong SLM-based retrieval in latency-critical settings by decoupling representation quality from serving efficiency. The modularity enables transfer of richer teacher signals (larger capacity, oracle features) into compact models, supporting practical scaling to new languages, domains, or tasks. The recipe also ensures compatibility with precomputed document indices, reducing costly recompute cycles and maximizing operational flexibility.
Theoretically, HLM quantifies the transfer gap and exposes the limits of knowledge distillation across scale and feature axes. The effectiveness of simple ℓ2 embedding regression over more complex distillation objectives suggests the prominence of direct representation space alignment in large dual-encoder architectures.
Future Directions
Opportunities include leveraging stronger teachers (larger SLMs, improved oracle context), optimizing unsupervised alignment objectives, and generalizing the recipe for broader embedding-based tasks (e.g., reranking, matching, or cross-modal retrieval). Further work could also explore automated quality–latency frontier selection and more advanced pruning strategies for extreme compression scenarios without sacrificing precision.
Conclusion
HARNESS-LM demonstrates that careful decoupling of representation transfer, alignment, compression, and task refinement enables high-quality, deployable retrieval models in sponsored search. Extensive empirical results validate the efficacy of the approach, and its modular recipe provides actionable guidance for production retrieval systems where latency, throughput, and cost are paramount. The framework paves the way for practical deployment of next-generation SLM-based retrievers and invites future extensions in scale and task breadth.