From Model Scaling to System Scaling: Scaling the Harness in Agentic AI
Abstract: This paper studies the next major bottleneck in agentic AI as system scaling, not only model scaling: the design of auditable, persistent, modular, and verifiable architectures around foundation models. We refer to this shift as scaling the harness: treating the structured execution layer around a foundation model as a first-class object of design, evaluation, and optimization. Although recent LLMs enable agents to use tools, retrieve information, maintain memory, and execute long-horizon workflows, evaluation remains largely model-centric, often reducing agents to final-task success while treating memory, retrieval, tool use, orchestration, verification, and governance as secondary implementation details. This framing is increasingly inadequate because agent performance emerges from the interaction among the foundation model, memory substrate, context constructor, skill-routing layer, orchestration loop, and verification-and-governance layer. Together, these components form the agent harness, which translates model capability into long-horizon agent behavior. We study scaling the harness through three core bottlenecks: context governance, trustworthy memory, and dynamic skill routing, together with the orchestration and governance mechanisms that coordinate and constrain them. We further outline a research agenda for harness-level benchmarks that go beyond one-shot task success to measure trajectory quality, memory hygiene, context efficiency, communication fidelity, verification cost, and safe evolution over time. To make the discussion concrete, we develop CheetahClaws: https://github.com/SafeRL-Lab/cheetahclaws, a Python-native reference harness, and compare it with Claude Code and OpenClaw. Our main claim is that future progress in agentic AI will depend as much on system design as on stronger foundation models.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper says that making AI agents better isn’t just about building bigger, smarter models. It’s also about building better “systems” around those models—like giving a great engine a well-designed car frame, steering, brakes, dashboard, and safety checks. The authors call this “scaling the harness,” where the “harness” is everything that helps an AI agent use tools, remember things, choose the right skills, stay organized, and act safely over long tasks.
What the authors wanted to figure out
In simple terms, the paper focuses on three easy-to-understand questions:
- How should an AI decide what information to focus on right now? (context governance)
- How can an AI trust its own memories and avoid using outdated or wrong info? (trustworthy memory)
- How can an AI pick the right tool or sub-agent at the right time—and check that the result is correct? (dynamic skill routing and verification)
The bigger goal is to show that future progress in AI agents depends as much on this system design as on the intelligence of the core model.
How they approached the problem (with everyday analogies)
Instead of doing a giant math experiment, the authors build a clear framework and a reference system to make the ideas concrete.
- Think of an AI agent like a student doing a long project. The “model” is the student’s brain. The “harness” is the planner, notebook, folders, reminders, rules for checking work, and when to ask for help.
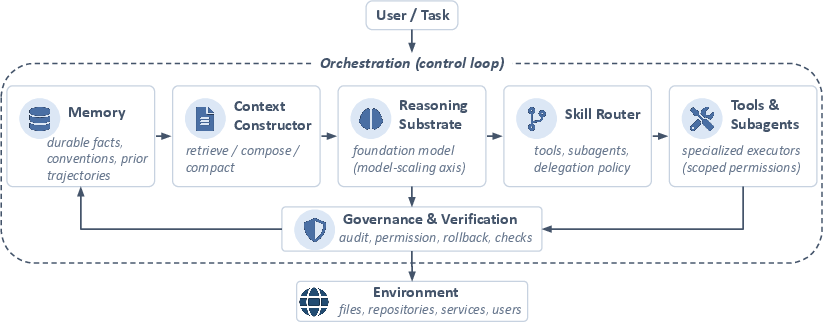
- The paper breaks an agent into six pieces that always work together:
- Reasoning substrate: the model’s thinking ability (the “brain”).
- Memory: what the agent stores to use later (the “notebook”).
- Context constructor: what to put on the desk right now (the “study pile” for today).
- Skill routing: choosing the right tool or teammate for each subtask (the “toolbox” or “who to ask”).
- Orchestration: the manager loop that keeps tasks in order (the “project planner”).
- Governance and verification: safety checks before actions (the “double-check and approvals”).
- They argue that long, realistic tasks depend on how these parts are designed and coordinated, not just on how smart the core model is.
To make it practical, they:
- Compare real agent systems (like Claude Code and OpenClaw) with their own open-source reference harness, CheetahClaws (Python-based).
- Show how different harness choices lead to different behaviors, even when the underlying model is similar.
- Propose new ways to evaluate agents that look at the whole process (not just whether the final answer is correct).
Key ideas explained simply
Here are the three main bottlenecks they focus on, using everyday language:
1) Context governance: choosing what to pay attention to
- Problem: A bigger “context window” (more things the AI can read at once) doesn’t help if it’s messy or irrelevant—like studying with a huge pile of random notes on your desk.
- Fix: Build a smart “context policy” that picks the most relevant, compact, and up-to-date information for each step, and keeps track of where everything came from. That means it’s not about “more pages,” but “the right pages.”
2) Trustworthy memory: remembering the right things safely
- Problem: Memories go stale. A note that used to be true (“the code is in file A”) can become false after changes (“now it’s in file B”). The agent may still confidently act on the old note.
- Fix: Treat memory as a hypothesis, not a fact—re-verify it when used. Rank what you retrieve by freshness and confidence, and sometimes check the live environment (e.g., search the current code) before acting. Store not just the content, but also when it was last verified.
3) Dynamic skill routing and verification: using the right tool, then checking the result
- Problem: Having many tools or sub-agents isn’t enough. The agent can pick the wrong one or accept a result that “sounds good” but isn’t actually checked.
- Fix: Make routing adaptive (choose tools based on the subtask and confidence), and require explicit post-condition checks (did the tool really achieve what it said?). Don’t just trust a fancy answer—verify it.
What they built and compared
To show these ideas in practice, the authors:
- Release CheetahClaws, a Python-native “reference harness” that makes design choices visible and auditable. For example, it stores per-memory confidence and recency so retrieval can prefer fresher, more reliable notes.
- Compare harnesses:
- Claude Code: a production-grade coding agent with tools, sub-agents, and a hybrid context strategy (some persistent notes plus just-in-time file lookups).
- OpenClaw: a community-built assistant harness focused on messaging and personal workflows.
- CheetahClaws: a research harness focused on transparency and reproducibility.
- Point out that these systems face the same core problems (context, memory, skills) but solve them differently depending on their goals.
What they found and why it matters
The main takeaways are:
- Performance comes from the model plus the harness. Many “scores” we see are really a combination of both.
- Bigger context windows aren’t a magic fix. Without good selection and ordering, more text can dilute attention and reduce accuracy.
- Memory must be treated with caution. The dangerous failure is “stale but confident.” Good systems re-check memory against the live environment and track freshness.
- Skills need routing and checks. Calling a sub-agent or tool isn’t enough—agents should verify outputs and learn when to escalate or switch strategies.
- We need better benchmarks and measurements. Don’t just ask “did the agent finish?” Also measure:
- How much unnecessary context it used
- How clean and accurate its memory is over time
- How often it verified claims
- How well multiple agents communicated and avoided stepping on each other’s toes
- Whether it stays safe and reliable over repeated use
- Agents should evolve safely. The paper suggests simple standards: clearly separate what can change (e.g., memory vs. permissions), measure drift and regressions over time, and keep an audit trail of what changed and why.
Why this matters: As AI agents start handling longer, real-world tasks—coding, research, personal assistance—reliability, safety, and cost are determined by the harness. Focusing only on a bigger model misses the everyday problems that make agents actually usable.
What this could change in the future
- Better design priorities: Teams building agents will spend more effort on memory quality, context policies, tool permissioning, and verification—not just prompts and model upgrades.
- New benchmarks: Competitions and tests will track process quality (like “memory hygiene”) and long-term behavior, not just one-shot correctness.
- Safer, more dependable agents: Clearer audit trails and verification steps make agents easier to trust in sensitive environments, like software development or enterprise workflows.
- Faster practical gains: Even without a new model, improving the harness can boost performance, cut costs, and reduce errors.
Quick recap
- The paper’s main message: Bigger brains help, but better backpacks, planners, and safety rules make the real difference in long, complex tasks.
- The three big bottlenecks: choosing the right context, trusting memory carefully, and routing skills with verification.
- The practical contribution: a framework, an evaluation agenda, and an open reference harness (CheetahClaws) to make design choices explicit.
- Impact: A roadmap for building AI agents that are not just smart, but reliable, auditable, and effective over time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, organized as a single bullet list for future researchers to address.
- Lack of empirical validation: No controlled experiments or ablations demonstrate the incremental impact of each harness component (memory, context, skill routing, orchestration, governance) on long‑horizon performance while holding the base model fixed.
- Unoperationalized framework: The function is conceptual; there is no quantitative decomposition, identifiable metrics, or methods for attributing performance changes to specific factors.
- Confounding factors: No protocol is provided to disentangle model improvements from harness effects (e.g., standardized prompts, budgets, retriever/tool interfaces) to avoid model–system confounds in reported scores.
- Missing baselines and controls: No head‑to‑head comparisons across harnesses with identical models, token/tool budgets, and tasks to isolate design choices such as context policies, memory verification frequency, or routing strategies.
- Incomplete metrics definitions: “Trajectory quality,” “memory hygiene,” “context efficiency,” “communication fidelity,” “verification cost,” and “safe evolution” are proposed but not precisely defined, instrumented, or standardized for benchmarking.
- Process instrumentation gap: No concrete logging schema or telemetry standard is specified to capture per‑turn context composition, retrieval decisions, tool actions, verification steps, and provenance for audit and reproducibility.
- Cost accounting gap: No principled framework for normalizing and reporting costs (tokens, tool calls, wall‑clock time, human interventions) alongside outcomes across different harnesses and tasks.
- Context selection policy learning: How to learn or optimize a context governance policy that trades off relevance, compactness, and provenance under token budgets is unspecified (e.g., supervised vs RL, offline vs online learning).
- Relevance and salience estimation: No method is provided to estimate decision‑importance of candidate context items beyond semantic similarity, especially under long‑context attention dilution.
- Provenance representation: Concrete data structures, schemas, and storage policies for traceability (source documents, versions, retrieval time, verification status) are not detailed.
- Refresh and recency policies: There is no algorithmic guidance on when to refresh context entries, how to prioritize re‑verification, or how to manage aging policies under compute and latency constraints.
- Memory trust calibration: How to estimate and calibrate per‑entry confidence and staleness (e.g., via Bayesian updating, uncertainty quantification, or empirical calibration) remains open.
- Verification pipelines for memory: Efficient, incremental strategies to re‑check retrieved memory items against live environments (e.g., code repos, APIs) and to amortize verification cost over time are not specified.
- Drift detection and repair: Formal methods to detect semantic drift, split/merge of entities (e.g., file moves, API changes), and to automatically update or retire memory items are not provided.
- Contamination and poisoning defenses: Concrete detection and mitigation for memory pollution (malicious or accidental), including adversarial examples, identity spoofing, and untrusted tool outputs, are not developed.
- Privacy and retention policies: How to bound privacy leakage during compaction/retrieval and to define retention/expiry policies for sensitive memory is not addressed.
- Trust‑aware retrieval ranking: There is no concrete scoring function or empirical study on integrating relevance, staleness, confidence, and risk into retrieval ranking and action gating.
- Skill specification standard: A formal schema for skills (pre‑conditions, post‑conditions, side‑effects, interfaces, verification hooks, resource costs, permissions) is not defined, hindering interoperability and verification.
- Learning to route skills: The paper advocates learned routing but does not specify training signals, datasets, feedback (success/verification outcomes), or algorithms (bandits, RL, meta‑learning) for adaptive routing.
- Composition and scheduling: Strategies for composing multiple skills with dependencies, batching, or parallelism (and resolving conflicts) are not specified; no scheduler analogy is made precise.
- Post‑condition checking: There is no reusable framework for defining, executing, and logging post‑condition tests per skill, including failure handling and automatic rollback policies.
- Failure recovery policies: Escalation, fallback, and de‑duplication policies after misrouting or verification failures (e.g., retry with different skill, request clarification, human handoff) are not concretely designed.
- Orchestration governance: Permission models (e.g., role‑based, capability‑based), approval thresholds, and safe defaults for tool access are not specified; no guidelines for the granularity of action gating.
- Verification cost modeling: There is no model to trade off verification depth against latency, cost, and risk, nor strategies to adapt verification intensity based on uncertainty or impact.
- Multi‑agent communication protocols: Concrete designs for uncertainty sharing, contradiction detection, task de‑duplication, and conflict resolution across subagents are not offered; message schemas and semantics remain unspecified.
- Heterogeneous subagent management: Methods to estimate capability profiles of diverse subagents/LLMs, calibrate their confidence, and allocate work accordingly are not developed.
- Longitudinal benchmark design: No concrete datasets, task suites, or procedures are provided to evaluate repeated‑use properties (memory improvement vs drift, contamination rates, recovery after errors).
- Evolution standard formalization: The proposed questions for agent evolution lack enforceable criteria, versioning policies, review gates, and CI/CD‑style pipelines for safe updates to memory, skills, and routing.
- Backdoor and reward‑hacking tests: Practical testbeds and detection methods for sleeper behaviors and proxy‑objective exploitation during agent evolution are not presented.
- Security threat modeling: A systematic mapping from OWASP‑style threats to harness controls (sandboxing, capability scoping, identity/authN/Z, supply‑chain security for tools) is missing.
- Interoperability gaps: There is no proposed standard for skills, memory entries, or provenance across harnesses to enable reproducible, cross‑system comparisons and component reuse.
- Domain and modality generalization: Claims and designs focus on coding agents; transferability to other domains (e.g., scientific workflows, enterprise operations) and modalities (vision, speech) is not evaluated.
- Scalability constraints: Storage, indexing, and latency challenges for very large, long‑lived memories and high‑throughput multi‑agent orchestration are not analyzed.
- Human‑in‑the‑loop integration: When and how the harness should solicit human feedback, expose rationale, and present audit trails to users for trust and oversight is not concretely addressed.
- Economic optimization: No framework to optimize harness behavior under explicit budgets or SLOs (cost, latency, accuracy, risk), including anytime/interruptible policies.
- Reproducibility of CheetahClaws claims: The asserted benefits of per‑entry confidence/recency in retrieval are not supported by quantitative studies, benchmarks, or ablations.
- Observability and auditability standards: A concrete, vendor‑agnostic log schema (events, timestamps, IDs, hashes, environment versions) to support audits and cross‑lab replication is not proposed.
Practical Applications
Immediate Applications
Below are deployable use cases that can be implemented now by adapting the paper’s “harness” principles (context governance, trustworthy memory, dynamic skill routing, orchestration, and verification-and-governance) and, where helpful, by starting from the open-source CheetahClaws reference harness.
- Software engineering: trust-aware coding agents in CI/CD (Software)
- Use case: Integrate a coding agent with a hybrid context policy (persistent project priors + just‑in‑time retrieval via glob/grep), staleness-weighted memory retrieval, and post-condition checks tied to unit tests and linters.
- Tools/workflows: GitHub/GitLab Actions; IDE plugins; CLAUDE.md–style project priors; automated test gating before code writes; failure attribution logs per edit.
- Dependencies/assumptions: Access to a capable LLM with tool use; mature test suites; repository permissions and sandboxing; token/cost budgets for verification.
- Enterprise assistants with audit trails and permissions (Enterprise IT/Compliance)
- Use case: Deploy assistants that log provenance for every tool call, enforce granular permissions, and gate external actions through verification policies.
- Tools/workflows: Policy-as-code guardrails; signed action logs; role-based access control (RBAC); approval workflows for high-risk actions.
- Dependencies/assumptions: Identity and access management (IAM) integration; data retention policies; security review for tool surfaces.
- Customer support copilots with live-verified answers (Customer Service)
- Use case: Route queries through dynamic retrieval from knowledge bases, re-verify “environment-dependent” facts before responding, and quarantine low-confidence or stale items.
- Tools/workflows: Retrieval with freshness scoring; confidence-calibrated response modes; escalation to human agents when verification fails.
- Dependencies/assumptions: Search over live KBs/FAQs; content freshness signals (timestamps, version tags); human-in-the-loop escalation paths.
- Research and analysis agents using orchestrator + subagents (R&D, Market/Patent Intelligence)
- Use case: Lead-agent orchestrates breadth-first exploration while subagents specialize (e.g., literature triage, data extraction); every handoff includes uncertainty and post-condition checks.
- Tools/workflows: Multi-window parallelization; per-subagent prompts/context; explicit handoff schemas with required summaries and open questions.
- Dependencies/assumptions: Compute budget for parallelism; libraries for inter-agent messaging; clear evaluation tasks with verification criteria.
- Process-centric agent benchmarking inside organizations (MLOps/QA)
- Use case: Instrument internal agent runs to report not only success but also tokens, tool calls, retries, passk reliability, memory hygiene, and verification cost.
- Tools/workflows: Telemetry hooks in harness; dashboards for trajectory quality and context efficiency; regression gates on process metrics.
- Dependencies/assumptions: Access to logs/telemetry; privacy filtering for traces; agreement on acceptable process-cost envelopes.
- Personal multi-channel assistants with memory hygiene (Daily life/Personal productivity)
- Use case: OpenClaw-style assistants that manage Slack/Email/Calendar with recency- and confidence-tagged memory, context compaction, and explicit user approvals for actions.
- Tools/workflows: Channel connectors; compact summaries of threads; verification prompts for scheduling and messaging.
- Dependencies/assumptions: OAuth access to channels; user consent and privacy controls; rate limits and throttling.
- Healthcare documentation and admin support with verification gates (Healthcare admin)
- Use case: Draft notes or insurance pre-auth packets by retrieving from EHR templates, verifying fields against live EHR, and logging provenance per data element.
- Tools/workflows: EHR-integrated read APIs; structured field checks; audit trails for each extracted datum; clinician confirmation steps.
- Dependencies/assumptions: HIPAA-compliant infrastructure; strict access controls; clinical oversight; institution-specific integrations.
- Financial back-office RPA with controlled tool execution (Finance/Operations)
- Use case: Orchestrate reconciliation/report generation via tool chaining and verifiable post-conditions (e.g., totals match, schema validated) before writes or submissions.
- Tools/workflows: Skill library for recurring procedures; post-condition validators; rollback on failed checks; immutable audit logs.
- Dependencies/assumptions: Data source connectors; change-management policies; segregation of duties and approvals.
- Security-minded agent deployments (Security/Policy)
- Use case: Apply the paper’s governance levers to mitigate OWASP-style agentic risks: memory poisoning, tool misuse, identity spoofing, goal manipulation.
- Tools/workflows: Signed memory writes; source provenance tags; tool allowlists with scopes; anomaly detection on agent trajectories.
- Dependencies/assumptions: Secure key management; tamper-evident logs; incident response playbooks for agent actions.
- Academic experimentation with reproducible harnesses (Academia)
- Use case: Use CheetahClaws to isolate and study context policies, memory trust scoring, and routing strategies, enabling reproducible ablations beyond model choice.
- Tools/workflows: Versioned skills; per-entry memory confidence/recency; standardized evaluation with process metrics.
- Dependencies/assumptions: Access to LLM APIs; reproducible datasets/environments; community benchmark sharing.
Long-Term Applications
These uses require further research, scaling, standardization, or regulatory alignment but are directly motivated by the paper’s framework and agenda.
- Standardized “agent evolution” governance (Policy/Compliance across sectors)
- Use case: Establish regulatory and industry standards specifying what persists (memory, skills, guardrails), what can auto-update, what needs review, and how to audit longitudinal behavior.
- Tools/workflows: “AgentSOX” compliance frameworks; change logs for routing policies and skills; replayable traces for audits.
- Dependencies/assumptions: Cross-industry consensus; reference audits; regulator guidance; secure and interoperable trace formats.
- Harness-aware model training optimizing process metrics (AI/ML R&D)
- Use case: Train policies to minimize verification cost, maximize context efficiency, and improve passk reliability, with harness signals (checks, staleness, provenance) in the learning loop.
- Tools/workflows: Offline RL from logged trajectories; simulators for long-horizon tasks; reward shaping over process metrics.
- Dependencies/assumptions: Rich labeled traces; compute budgets; methods to avoid reward hacking and overfitting to proxies.
- Interoperable communication protocols and “skill marketplaces” (Software/Platform economy)
- Use case: Cross-agent protocols for handoffs, uncertainty, and post-conditions; registries for versioned, verifiable skills discoverable and callable across vendors.
- Tools/workflows: Open schemas for skill specs; signed skill bundles; compatibility tests; broker services for routing.
- Dependencies/assumptions: Open standards; security models for third-party skills; economic incentives and curation.
- Trustworthy memory infrastructure as a managed service (Enterprise platforms)
- Use case: “Memory with trust” services providing staleness-aware retrieval, periodic re-verification against live systems, and provenance enforcement across apps.
- Tools/workflows: Connectors for databases/repositories; scheduled re-checks; confidence decay policies; conflict resolution APIs.
- Dependencies/assumptions: Vendor-neutral integrations; privacy-preserving sync; SLAs for verification latency.
- Sector-specific longitudinal benchmarks (Academia/Industry consortia)
- Use case: Benchmarks that measure memory retrieval precision, hygiene, minimal-context efficiency, communication fidelity, drift over long sessions, and recovery after wrong routing.
- Tools/workflows: Open testbeds (code, terminal, web, EHR sandboxes); standardized process metrics; community leaderboards reporting outcomes + process.
- Dependencies/assumptions: Shared datasets/environments; accepted metric definitions; funding for maintenance.
- Autonomous but governed clinical/operations agents (Healthcare)
- Use case: Agents that perform limited-scope tasks (e.g., care-gap closure, prior auth, scheduling) with strict verification, auditability, and rollback.
- Tools/workflows: Clinical skill libraries with explicit post-conditions; safety cases; human approval checkpoints; integration with EHR and payer APIs.
- Dependencies/assumptions: Regulatory clearance; robust on-call oversight; rigorous validation; liability frameworks.
- Industrial robotics with harness-level safety (Robotics/Manufacturing)
- Use case: Route high-level tasks to verified skills (motion plans, inspections), with command gating and environment re-checks before actuation.
- Tools/workflows: Simulation-in-the-loop verification; digital twins; capability-scoped skills; sensor-fusion checks before commits.
- Dependencies/assumptions: Reliable perception stacks; safety certifications; latency budgets for verification in the control loop.
- Energy and grid operations assistants (Energy/Utilities)
- Use case: Dispatch analyses and control proposals through verifiable skills (load forecasts, contingency checks) with operator-in-the-loop approvals and auditable traces.
- Tools/workflows: SCADA/EMS read-only mirrors for verification; scenario simulators; skill routing based on grid state.
- Dependencies/assumptions: Secure integrations; safety interlocks; regulatory oversight; real-time performance constraints.
- Financial agents with provable post-conditions (Finance/RegTech)
- Use case: Agents that execute compliant workflows (KYC review, report filing) where every step has verifiable post-conditions and evidentiary logs for regulators/auditors.
- Tools/workflows: Formalized post-condition libraries; immutable logs; reconciliation validators; change-control for skills.
- Dependencies/assumptions: Regulator-accepted audit formats; data lineage guarantees; periodic external audits.
- Education: longitudinal, adaptive tutors with memory hygiene (Education/EdTech)
- Use case: Tutors that retain student progress and misconceptions with durable, precise, and verifiable memory; adapt curricula while avoiding drift and over-generalization.
- Tools/workflows: Skills for feedback, spaced repetition, and mastery checks; assessment-driven post-conditions; parent/teacher oversight dashboards.
- Dependencies/assumptions: Privacy-preserving data storage; validated pedagogical models; fairness and bias monitoring.
- Cross-vendor “context governors” and “verification orchestrators” (Developer tooling)
- Use case: Libraries/services that plug into any agent runtime to assemble minimal sufficient context and manage verification workflows across tools/subagents.
- Tools/workflows: Relevance + freshness scoring; provenance tagging; declarative verification pipelines; policy packs.
- Dependencies/assumptions: Stable plugin APIs in agent runtimes; benchmarking to prove efficacy; alignment with enterprise governance tools.
- Safety certifications for tool-using agents (Policy/Standards)
- Use case: Certification schemes that require evidence of harness controls (permissions, verification gates, auditability, evolution policy) before deployment in sensitive settings.
- Tools/workflows: Test suites simulating failure modes (memory poisoning, drift); conformance tests for governance layers; incident reporting standards.
- Dependencies/assumptions: Standards bodies engagement; incident databases; stakeholder consensus on risk thresholds.
Notes on feasibility across items:
- Many immediate deployments assume access to a sufficiently capable foundation model with reliable tool APIs and manageable latency/cost.
- Gains from multi-agent routing depend on available parallelism and well-defined post-conditions to prevent error amplification.
- Regulated sectors (healthcare, finance, energy) require human oversight, rigorous verification, and acceptance by regulators; harness-level auditability is a prerequisite but not a substitute for approval.
- Organizational readiness (test coverage, data connectors, IAM, logging) materially affects the benefits of system scaling.
Glossary
- agent evolution: The process by which an AI agent updates its skills, memory, routing policies, and coordination protocols over time while remaining safe and auditable. Example: "the field still lacks a mature framework for agent evolution over time, including how agents should update skills, refine memory, communicate across roles, and remain auditable as they adapt."
- agent harness: The structured system layer that surrounds a foundation model to manage tools, memory, context, routing, orchestration, and governance. Example: "Together, these components form the agent harness, the system that translates model capability into long-horizon agent behavior."
- agentic AI: AI systems designed to act as agents that autonomously plan, use tools, and interact with environments over multiple steps. Example: "This paper studies the next major bottleneck in agentic AI as system scaling, not only model scaling..."
- auditability: The property of an agent system that enables tracing, inspection, and accountability of actions, memory writes, and policy changes. Example: "they operate over private files, credentials, tools, repositories, browsers, and external services. In these settings, auditability, permission control, rollback, and provenance are not optional."
- backdoored behaviors: Hidden, malicious or unintended behaviors embedded within models that can persist through training and evade simple tests. Example: "Behavioral evaluation alone is insufficient for persistent risks of the kind documented in \citep{hubinger2024sleeper}, where backdoored behaviors survive SFT, RL, and adversarial training."
- calibrated uncertainty: A model’s well-calibrated estimate of its own uncertainty used to decide whether to retrieve information or seek verification. Example: "and that agents still need calibrated uncertainty to decide when to retrieve at all~\citep{guo2026llms}."
- chain-of-thought prompting: A prompting technique that elicits step-by-step reasoning from LLMs to improve problem solving. Example: "extending earlier work on chain-of-thought prompting~\citep{wei2022chain} and prompt-pattern catalogs~\citep{white2023prompt}."
- communication fidelity: The accuracy and reliability with which information is conveyed between components or agents, preserving intent and content. Example: "going beyond one-shot task success to measure trajectory quality, memory hygiene, context efficiency, communication fidelity, verification cost, and safe evolution over time."
- confident-but-unchecked: A failure mode where an agent or skill produces plausible outputs that are not validated, leading to errors. Example: "The threat we are guarding against is confident-but-unchecked: a specialized subagent can return plausible output that no downstream layer validates."
- context constructor: The component that assembles the set of inputs (context) provided to the model at each step, drawing from memory and environment. Example: "agent performance emerges from the interaction among the foundation model, memory substrate, context constructor, skill-routing layer for tools and subagents, orchestration loop, and verification-and-governance layer."
- context governance: The policies and mechanisms that determine what information is retrieved, ordered, compressed, refreshed, and trusted in the agent’s context. Example: "We therefore study scaling the harness through three core bottlenecks in agentic AI: context governance, trustworthy memory, and dynamic skill routing..."
- context windows: The maximum number of tokens a model can attend to at once; larger windows do not guarantee effective use. Example: "Context length is another example: larger context windows do not guarantee effective information access, because attention dilutes over long inputs~\citep{gu2026long}..."
- dynamic skill routing: The learned or adaptive process of selecting and sequencing specialized skills or subagents during a task. Example: "We therefore study scaling the harness through three core bottlenecks in agentic AI: context governance, trustworthy memory, and dynamic skill routing..."
- execution harness: The operational runtime and control system that integrates the model with tools, verification, and workflows. Example: "What distinguishes modern agentic coding systems from classic code assistants is therefore not stronger token-level generation alone, but the presence of an execution harness that supports tool use, iterative verification, and task decomposition."
- exposure without access: A failure mode where more tokens are presented to the model but relevant information is not effectively attended or retrieved. Example: "The threat we are guarding against is exposure without access: as context grows, the model sees more tokens but does not necessarily attend to the right ones."
- governance boundaries: Defined limits and policies that constrain agent actions, updates, and permissions for safety and compliance. Example: "Update policies should distinguish components that may adapt online from those requiring review, replay, or stronger verification, especially when changes interact with tool permissions or governance boundaries."
- hierarchical memory management: A structured approach to memory that organizes information at multiple levels of abstraction or priority. Example: "MemGPT's hierarchical memory management~\citep{packer2023memgpt}..."
- long-horizon: Referring to tasks or behaviors that span many steps, sessions, or extended periods. Example: "Recent progress in LLMs has enabled agents that use tools, retrieve information, maintain memory, and execute long-horizon workflows."
- memory hygiene: The quality and cleanliness of an agent’s memory, including avoidance of contamination, staleness, and drift. Example: "going beyond one-shot task success to measure trajectory quality, memory hygiene, context efficiency, communication fidelity, verification cost, and safe evolution over time."
- memory poisoning: Malicious or accidental insertion of harmful or misleading information into an agent’s memory. Example: "the OWASP catalogue of agentic threats lists memory poisoning, identity spoofing, tool misuse, and goal manipulation as exploitable failure surfaces~\citep{owasp2025agentic}."
- memory substrate: The underlying storage and data structures used by an agent to persist information across steps or sessions. Example: "agent performance emerges from the interaction among the foundation model, memory substrate, context constructor, skill-routing layer for tools and subagents, orchestration loop, and verification-and-governance layer."
- mixture-style composition: Combining outputs or capabilities of multiple skills or models in a mixture-like manner for improved performance. Example: "The open research direction is to make this allocation adaptive through online estimates of subtask type, confidence-aware escalation, mixture-style composition, and policies optimized for verified rather than fluent intermediate outputs..."
- model scaling: Improving performance by increasing model size, data, and post-training quality, focusing on the model itself. Example: "By model scaling, we refer to improvements in the standalone foundation model, including model size, training data, post-training, and raw reasoning capability."
- multi-agent systems: Arrangements where multiple agents coordinate (or fail to) on tasks, often requiring communication protocols. Example: "Multi-agent systems show a similar pattern: they can outperform single agents on breadth-first tasks but introduce coordination failures that single-agent metrics miss~\citep{anthropic_multiagent, cemri2025multiagent}..."
- non-Pareto-optimal: Describing results that can be simultaneously improved on at least one metric without worsening another when accounting for costs or constraints. Example: "A field-level analysis of agent benchmarks finds that many results do not separate capability from costs, prompting strategy, and demonstrations, and become non-Pareto-optimal once these factors are controlled~\citep{kapoor2024aiagents}."
- orchestration loop: The control loop that sequences context construction, skill routing, verification, and memory updates around the model. Example: "This framing is increasingly inadequate: agent performance emerges from the interaction among the foundation model, memory substrate, context constructor, skill-routing layer for tools and subagents, orchestration loop, and verification-and-governance layer."
- orchestrator-plus-subagent configurations: Architectures where a central agent coordinates specialized subagents to parallelize or decompose work. Example: "Anthropic reports substantial gains from orchestrator-plus-subagent configurations on breadth-first research tasks~\citep{anthropic_multiagent}."
- OWASP catalogue of agentic threats: A community-maintained list of security risks specific to agentic systems. Example: "and the OWASP catalogue of agentic threats lists memory poisoning, identity spoofing, tool misuse, and goal manipulation as exploitable failure surfaces~\citep{owasp2025agentic}."
- passk: The probability of succeeding on k independent rollouts, used to evaluate reliability beyond single attempts. Example: "In particular, -bench shows that agents that look strong under single-shot pass rates can collapse under , the probability of succeeding on independent rollouts."
- post-condition checking: Verifying that a skill or action’s expected outcomes hold in the environment before proceeding. Example: "and to make post-condition checking a first-class component of each skill specification."
- privacy drift: The phenomenon where extended or accumulated context leads to unintended exposure or leakage of private information over time. Example: "At the same time, recent analyses show that longer context windows come with their own failure modes such as privacy drift~\citep{gu2026long}..."
- provenance: Recorded origin and lineage of information used by the agent, supporting accountability and debugging. Example: "prefer recently validated content, and record provenance so failures can be attributed at audit time."
- prompt engineering: The practice of designing prompts to control model behavior and improve performance on specific tasks. Example: "Prompt engineering~\citep{white2023prompt} remains useful for local control, but long-horizon performance increasingly depends on reusable skills, persistent memory, disciplined context construction, and verification-aware execution."
- reasoning substrate: The base reasoning component of the system—typically the foundation model—on which the agent relies. Example: "a reasoning substrate (), a memory store (), a context constructor ()..."
- retrieval-augmented generation: A paradigm that augments LLMs with external memory or documents retrieved at inference time. Example: "Retrieval-augmented generation~\citep{lewis2020rag} showed that augmenting parametric LLMs with external non-parametric memory can substantially improve knowledge-intensive generation and question answering."
- signal dilution: Degradation of relevant information due to excessive or poorly governed context, reducing attention to the right tokens. Example: "Relevant evidence competes with low-value padding (signal dilution~\citep{gu2026long})..."
- skill router: The mechanism that dispatches tools or subagents based on the current task state and policy. Example: "The skill router () dispatches tools or subagents; their effects on the environment, together with the model's intermediate steps, are gated through verification and governance ()..."
- skill routing: The selection and sequencing of skills or subagents to solve subtasks effectively and safely. Example: "We use system scaling to denote improvements in this harness that determine how information, computation, authority, and verification are allocated over time... a skill-routing layer (, which dispatches tools and subagents)..."
- stale-but-confident: A failure mode where outdated memory is treated as reliable, leading to erroneous actions. Example: "The threat we are guarding against is stale-but-confident."
- system scaling: Improving the architecture around the model—memory, context construction, tools, orchestration, verification—rather than only the model itself. Example: "Our key claim is therefore that agentic AI should be studied and evaluated as a system-scaling problem, not merely as a model-scaling problem."
- tool schemas: Structured interface specifications for tools that define how agents can call and use them effectively. Example: "SWE-agent's agent--computer interface, which shows that carefully designed tool schemas can by themselves move benchmark accuracy substantially even with a fixed backbone model~\citep{yang2024sweagent}."
- trustworthy memory: Memory that remains precise, durable, retrievable, and verifiable over time, with mechanisms to check for drift. Example: "We therefore study scaling the harness through three core bottlenecks in agentic AI: context governance, trustworthy memory, and dynamic skill routing..."
- verification-and-governance layer: The component that gates actions, checks outputs, enforces policies, and ensures safety and compliance. Example: "agent performance emerges from the interaction among the foundation model, memory substrate, context constructor, skill-routing layer for tools and subagents, orchestration loop, and verification-and-governance layer."
- verification-aware recovery: Strategies for detecting and correcting errors based on verification signals during or after execution. Example: "The next generation of agent benchmarks should additionally measure... verification-aware recovery after stale memory or wrong routing..."
- verification cost: The resource and time overhead associated with verifying actions, outputs, or memory updates. Example: "going beyond one-shot task success to measure trajectory quality, memory hygiene, context efficiency, communication fidelity, verification cost, and safe evolution over time."
- vector retrieval: Retrieving information based on vector embeddings (e.g., semantic similarity) rather than exact keyword match. Example: "Memory & Persistent text memory, auto-extraction & Conversation history, vector retrieval & Structured entries with confidence, recency \"
Collections
Sign up for free to add this paper to one or more collections.