ScientistOne: Towards Human-Level Autonomous Research via Chain-of-Evidence
Abstract: Autonomous research agents produce competitive solutions and professional-looking manuscripts, yet their outputs contain verifiability failures undetectable by surface-level evaluation: fabricated citations, unreproducible scores, and method descriptions that diverge from the implementation. We address this through three contributions. First, Chain-of-Evidence (CoE), a verifiability framework requiring every claim to be traceable to its evidence source. Second, ScientistOne, an end-to-end autonomous research system that maintains evidence chains by construction throughout literature review, solution discovery, and paper writing. Third, CoE Audit, a post-hoc audit whose four integrity checks -- score verification, specification violation, reference verification, and method-code alignment -- apply uniformly to all systems. Across 75 papers spanning five systems and five frontier research tasks, every baseline exhibits at least one systematic failure mode: hallucinated reference rates reach 21%, score verification passes in as few as 42% of papers, and method-code alignment ranges from 20% to 80%. ScientistOne achieves zero hallucinated references (0/337), perfect score verification (12/12), and the highest method-code alignment (14/15), while matching or exceeding human expert performance on all five tasks. ScientistOne further generalizes to six additional tasks spanning medical imaging, fine-grained recognition, 3D perception, and language modeling, achieving state-of-the-art on Parameter Golf and gold medals on MLE-Bench tasks where baselines fail entirely.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Towards Human-Level Autonomous Research via Chain-of-Evidence”
What this paper is about (big picture)
The paper looks at AI “research agents” that can read papers, run experiments, and write research manuscripts by themselves. These agents can produce work that looks professional, but sometimes the facts inside aren’t trustworthy—numbers don’t reproduce, references are made up, or the methods described don’t match the code. The authors’ main goal is to make AI‑written research verifiable and trustworthy by requiring a clear trail of evidence for every claim, like a detective linking each clue to a source.
What questions the authors asked
The paper focuses on three simple questions:
- How can we require that every claim in an AI‑written paper is backed by real, checkable evidence?
- Can we build an AI research system that keeps track of this evidence from start to finish?
- Can we design a fair “audit” that checks any AI research paper for common integrity problems?
How they approached it (methods in everyday language)
The authors introduce three pieces that work together:
- Chain‑of‑Evidence (CoE): a simple rule
- Idea: Every claim in a paper (like a number, a reference, a method, or a conclusion) must point to a real source—such as a log file, a piece of code, or a paper in a public database—so anyone can trace it back.
- Think of it like a science fair notebook where every result has the raw data attached, and every reference has a link you can actually click.
- A new AI research system built to preserve evidence
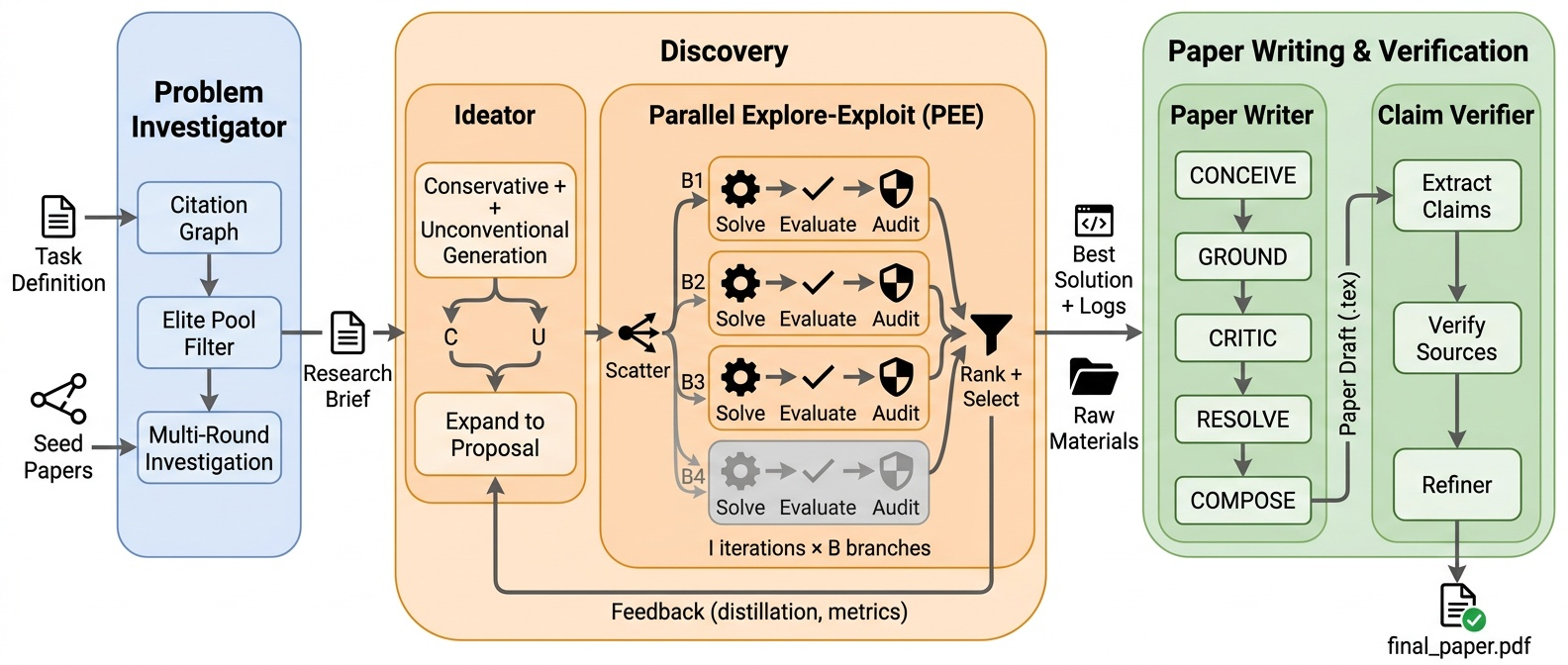
- Stage 1: Problem Investigator
- Reads up to 100 full papers from real scholarly databases.
- Keeps the sources and metadata (where each paper came from) so references aren’t just “made up from memory.”
- Stage 2: Discovery Engine
- Tries different solution ideas in parallel and scores them with a “golden evaluator” (a standardized program that grades solutions fairly).
- Saves all logs, settings, and results, so later claims can point back to what actually ran.
- Stage 3: Paper Writer + Claim Verifier
- Writes the paper from the saved facts.
- Before finalizing, a Claim Verifier checks each sentence that makes a claim:
- Numbers must match the logs.
- References must match real papers.
- The described method must match the code.
- If a claim isn’t supported, it’s fixed or removed.
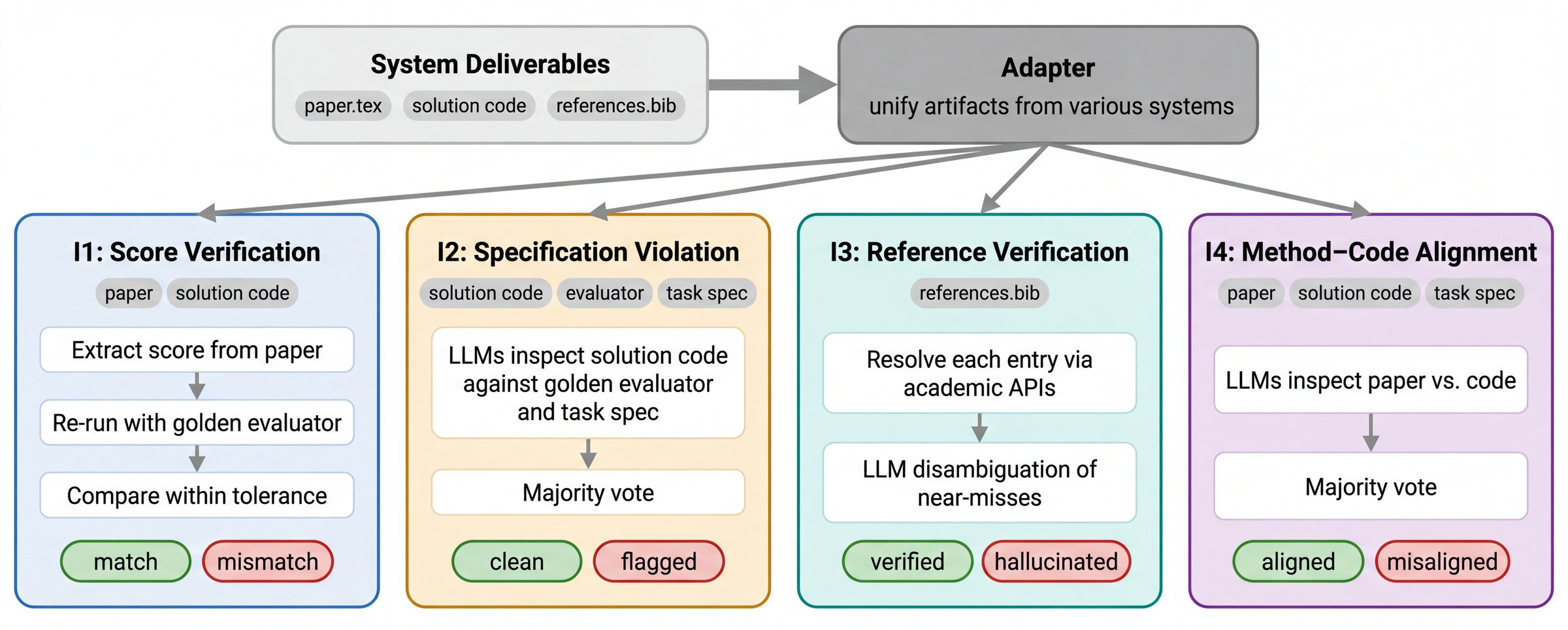
- CoE Integrity Audit: a universal “fairness check” for any system This is a post‑hoc audit that can check papers from any AI system (not just the authors’). It looks for four common problems:
- Score Verification
- Do the numbers in the paper match the numbers you get when you re‑run the code with the official evaluator?
- Specification Violation
- Did the code “cheat,” like reading the grader’s answer key or breaking the rules of the task?
- Reference Verification
- Are the citations real and correctly matched to actual papers (via services like Semantic Scholar, arXiv, CrossRef)?
- Method–Code Alignment
- Does the method described in the paper actually match what the code does (not just fancy words that don’t reflect the program)?
Key terms in plain words:
- Evaluator: a trusted program that scores solutions the same way every time—like a standardized test grader.
- Benchmark: a set of tasks and rules used to fairly compare different systems.
- Hallucinated reference: a fake or incorrect citation that looks real but isn’t.
- Provenance: a record of where information came from (the “receipt” for each claim).
What they found (main results and why they matter)
The authors tested five AI research systems on five tough tasks (75 papers total) and ran the CoE Integrity Audit. Here’s what they discovered:
- Common problems in other systems:
- Fake or incorrect references happened in up to 21% of bibliography entries.
- Only 42% to 92% of papers had numbers that reproduced when re‑run.
- Method descriptions and the actual code matched only 20% to 80% of the time.
- Their CoE‑built system did best on verifiability:
- 0 hallucinated references out of 337 entries (every citation was real).
- 12 out of 12 score checks passed (numbers reproduced exactly within allowed tolerance).
- 14 out of 15 papers had method descriptions that matched the code.
- Almost all numerical claims in their papers traced back to logs (about 99% after manual checks).
- It also worked well beyond the initial tests:
- The system generalized to new areas (like medical imaging, 3D perception, and constrained language modeling).
- It reached state‑of‑the‑art on some benchmarks and won gold medals on others where competing systems failed.
- Review quality improved:
- Using an automated review tool, their papers were accepted much more often than those from other systems.
- The key difference wasn’t flashier writing or dramatically better algorithms—it was that the claims were supported by evidence and didn’t contradict the data.
Why this matters (impact and implications)
- Trust and accountability: If AI is going to help write research, we need to trust what it says. Chain‑of‑Evidence makes it easy to check every claim.
- Better standards for science: The audit shows exactly where things go wrong (fake references, non‑reproducible numbers, mismatched methods), so systems can be fixed.
- Less “pretty but wrong”: Papers that look convincing but can’t be verified are a risk. This approach reduces that problem by requiring proof for every claim.
- Usable for humans and machines: While built for AI systems, the same idea—trace every claim to evidence—can help human-authored research too.
- A new baseline: The authors show that you don’t have to sacrifice performance to be honest and reproducible. You can match or beat human experts and still keep everything verifiable.
In short: The paper introduces a clear rule—every claim must have a traceable source—and shows how to build and check AI research systems to follow it. The result is research that’s not just impressive on the surface, but solid underneath.
Knowledge Gaps
Below is a concise, actionable list of the paper’s unresolved gaps, limitations, and open questions that future work could address.
- Claim coverage limits: CoE’s taxonomy and the Integrity Audit focus on four claim types and four checks, leaving qualitative claims (e.g., “near-optimal”), theoretical claims, novelty claims, and figure/table correctness largely unverified.
- Conclusion- and citation-attribution verification: The audit (I1–I4) does not verify whether conclusion-level claims logically follow from evidence, nor whether statements about cited work are faithful beyond existence; end-to-end citation attribution and entailment remain open.
- LLM-judgment reliability: I2 (specification violation) and I4 (method–code alignment) rely on majority-vote LLM judgments; observed near-misses show nontrivial noise. There is no systematic ground-truth study, inter-annotator agreement, or calibration analysis.
- Determinism and hardware dependence: Score Verification (I1) assumes access to a deterministic “golden” evaluator and comparable hardware; one task (EPLB) is excluded due to hardware variance. Generalizing to stochastic, non-deterministic, or proprietary evaluators is unresolved.
- Reference verification scope: I3 primarily checks existence via scholarly APIs and basic disambiguation. Handling misattributed citations, paywalled/non-indexed sources, metadata errors, or verifying that a citation actually supports the stated claim is not established.
- Provenance authenticity and tamper resistance: CoE links claims to logs but does not secure the chain (e.g., cryptographic signing, attested environments, reproducible builds). Ensuring logs and artifacts cannot be post-hoc edited remains an open requirement.
- Scalability and cost: The system reads up to 100 PDFs per topic and runs parallel explore–exploit search, yet time/compute costs, throughput, and trade-offs between verifiability and productivity are not reported.
- Baseline adaptation confounds: Baselines were heavily adapted (e.g., prompt rewrites, patched files) and all systems used a single proprietary LLM backbone. How conclusions hold under authors’ native configurations or with different LLMs is unclear.
- External validity beyond ADRS-like tasks: While additional tasks are mentioned, the audit’s assumptions (evaluator availability, determinism, code-based solutions) may not hold in wet-lab, robotics, long-running studies, or human-subjects research.
- Human evaluation gap: Paper quality is judged by an automated reviewer; there is no human peer-review study or user evaluation assessing the perceived verifiability and scientific soundness of CoE-compliant papers.
- Method–code alignment granularity: I4 checks algorithm-class alignment but may miss partial mismatches (e.g., hidden heuristics, undocumented fallbacks), hyperparameter- or data-regime-specific behaviors; no static/dynamic program analysis is used.
- Specification-violation detection robustness: I2 can be evaded by obfuscation or evaluator-aware coding; it lacks sandboxing, dynamic instrumentation, or formal analyses to detect subtle evaluator gaming.
- Claim Verifier coverage gaps: Qualitative overclaims, units/rounding discrepancies, figure/table number extraction, and baseline fairness (e.g., comparable settings and hyperparameters) are not comprehensively audited.
- Reproducibility controls: Environment drift (e.g., env vars, unseeded randomness) affected outcomes; there is no standardized containerization, seed control, or artifact hashing strategy to guarantee exact reproducibility across runs/machines.
- Security and supply-chain risks: Literature ingestion (PDFs, web) and tool use introduce risks (prompt injection, malicious code/documents), but security hardening and attack resilience are not analyzed.
- Ethical/governance questions: Authorship, accountability, and disclosure practices for autonomous systems producing publishable manuscripts are not addressed.
- Novelty vs. grounding trade-offs: The effect of stringent evidence grounding on ideation breadth and algorithmic creativity is not measured; potential trade-offs remain unexplored.
- Component ablations: There is no ablation isolating the contributions of the Problem Investigator, Explore–Exploit orchestration, and Claim Verifier to integrity and performance gains.
- Benchmarking infrastructure: There is no released, standardized benchmark of audited papers with ground-truth labels for I1–I4 (and beyond) to foster reproducible progress on verifiability.
- Multilingual and domain coverage: Handling of non-English literature and domain-specific repositories (with sparse API coverage) is not discussed.
- Benchmark drift and temporality: The framework does not address changing evaluators, dataset revisions, or evolving benchmarks; how CoE maintains validity over time is unclear.
- Data leakage detection: Distinguishing retrieval-grounded evidence from latent model memory (and detecting leakage) is not systematically handled.
- Real-time vs. post-hoc verification: While mentioned, live verification during generation is out of scope; the design and efficacy of real-time CoE enforcement remain open.
- Threshold and tolerance choices: Adaptive tolerances in I1 and the 5% numerical CPR threshold lack sensitivity analyses; how results change with different thresholds is not studied.
Practical Applications
Overview
The paper introduces a verifiability standard (Chain-of-Evidence, CoE), an autonomous research system that maintains evidence chains by construction, and a post‑hoc CoE Integrity Audit with four checks: score verification (I1), specification violation detection (I2), reference verification (I3), and method–code alignment (I4). Below are practical applications derived from these contributions across industry, academia, policy, and daily life. Each item names potential tools/workflows and notes assumptions that affect feasibility.
Immediate Applications
- Research Artifact Verifier in CI/CD (industry, academia; software/ML tools)
- What: A GitHub/GitLab/Bitbucket action that runs the CoE Integrity Audit (I1–I4) on pull requests or release candidates containing code, evaluators, and manuscripts. Blocks merges when scores don’t reproduce, references don’t resolve, or code and methods diverge.
- Tools/workflows: “CoE Audit CI” action; containerized evaluator runner; LLM-based code–doc alignment checker; integration with MLflow/Weights & Biases for log provenance.
- Dependencies/assumptions: Access to a “golden” evaluator or a faithfully packaged evaluator; deterministic or variance‑bounded metrics; safe sandboxing for code execution; API access (Semantic Scholar, arXiv, CrossRef, OpenAlex).
- Journal and Conference Pre‑Submission Checker (academia, publishing)
- What: An automated gate for submissions that runs I1–I4 and generates a reproducibility/traceability report for editors and reviewers.
- Tools/workflows: Overleaf/TeX plugin to export artifacts; editorial dashboards; reviewer‑facing forensic report with pass/fail on I1–I4.
- Dependencies/assumptions: Author willingness to share code/evaluators; compute to re‑run experiments; policy updates allowing artifact checks at submission time.
- Leaderboard/Competition Submission Guardrails (academia, industry; benchmark platforms)
- What: Hosts (e.g., Kaggle‑style platforms, open research leaderboards) automatically re‑run submissions (I1) and check for spec violations (I2) before posting scores.
- Tools/workflows: “LeaderboardShield” harness wrappers; majority‑vote LLM spec‑violation checkers; audit badges on leaderboard entries.
- Dependencies/assumptions: Containerized evaluators; resource quotas for re‑runs; clear task specifications to judge violations.
- Provenance‑First Paper Writing (industry R&D, academia; software)
- What: Adopt the paper’s “Paper Writer + Claim Verifier” workflow to draft reports/manuscripts where every quantitative claim is linked to logs and every citation resolves to retrieved PDFs.
- Tools/workflows: “Provenance-First Writer” that tags claims with sources; “Claim Verifier SDK” for numerical/citation/method checks; iterative Ground–Critic–Resolve loop.
- Dependencies/assumptions: Structured experiment logs; access to full‑text literature (via institutional access or open sources); LLM reliability for alignment checks.
- Reference Hygiene for Authors and Students (academia, education, daily life writing)
- What: Standalone “CiteCheck” utility or browser/LaTeX/VS Code/Overleaf plugin to validate bibliographies via multiple scholarly APIs; flags fabricated or mismatched entries (I3).
- Tools/workflows: One‑click verification in editors; batch DOI/arXiv/title reconciliation.
- Dependencies/assumptions: API availability/rate limits; disambiguation for near‑duplicate titles.
- Code–Doc Alignment Linter (software engineering; dev tools)
- What: Static analysis that compares README/method sections to code behavior (I4) to catch overly ambitious docs or out‑of‑date descriptions.
- Tools/workflows: “CodeDocAlign” pre‑commit hook; CI job with majority‑vote LLM judgments and human‑in‑the‑loop triage.
- Dependencies/assumptions: Stable codebase; sufficient code comments/tests to aid LLM understanding.
- Procurement and Vendor Deliverable Audits (policy, enterprise governance)
- What: Buyers of AI systems request CoE audit reports to validate claims and detect reward‑hacking/spec violations (I2).
- Tools/workflows: RFP requirements mandating I1–I4 pass/fail summaries; red‑team audits for evaluator gaming.
- Dependencies/assumptions: Contractual access to artifacts; secure compute environments for re‑runs.
- Healthcare AI Report Verification (healthcare; compliance)
- What: Verify that reported metrics in clinical AI studies trace to logs (I1/CPR) and that citations to medical evidence are real (I3), supporting regulatory filings and internal QA.
- Tools/workflows: Secure “CoE for PHI” sandbox; provenance‑tagged experiment trackers; audit trails for FDA/EMA submissions.
- Dependencies/assumptions: PHI‑safe compute; domain‑specific evaluators; human oversight for clinical interpretation.
- Internal Data Science Benchmark Integrity (industry; analytics/ML platforms)
- What: Detect “metric gaming” in internal benchmarks via I2 and ensure reproducibility via I1 before publishing dashboards/OKRs.
- Tools/workflows: Auto‑rerun on metric publication; alerts on spec‑violating patterns (e.g., caching test cases).
- Dependencies/assumptions: Clear benchmark specs; versioned evaluators; access to raw code and data slices.
- Teaching Scientific Writing with Evidence Tags (education)
- What: Require students to submit labs/reports with inline evidence annotations; run automated checks for CPR and citation validity.
- Tools/workflows: LMS plugins; rubric extensions for provenance and reproducibility.
- Dependencies/assumptions: Curated datasets/evaluators for coursework; institutional API keys for literature services.
- Marketing/Analyst Whitepaper Verification (industry; finance/consulting)
- What: Ensure AI‑assisted whitepapers and analyst notes use verifiable citations and reproduce reported metrics from notebooks/pipelines.
- Tools/workflows: “Evidence‑backed whitepaper” workflow with I3 and CPR checks; executive‑friendly audit appendix.
- Dependencies/assumptions: Access to proprietary data/logs; willingness to disclose verification details (even if results are anonymized).
Long‑Term Applications
- CoE as a Community Standard for Research Verifiability (academia, policy, publishing)
- What: Formalize CoE (analogous to ACID) as a requirement in journals, conferences, and funding calls; claim‑level provenance becomes part of the artifact record.
- Tools/workflows: Standardized “claim graphs” embedded in PDFs/DOIs; CrossRef/OpenAlex extensions to store evidence links; verifiability badges.
- Dependencies/assumptions: Broad stakeholder agreement; tooling maturity; incentives for compliance.
- Evidence‑Native Research OS (software; industry/academia)
- What: Deep integration of CoE into IDEs, notebooks, experiment trackers, and paper editors so evidence tags are created automatically throughout the workflow.
- Tools/workflows: MLflow/Weights & Biases plugins that emit claim anchors; Overleaf/LaTeX extensions that resolve tags; unified provenance stores.
- Dependencies/assumptions: Vendor ecosystem cooperation; standardized schemas; performance overhead management.
- Autonomous Research Labs with CoE Guardrails (software, robotics, healthcare, materials)
- What: End‑to‑end agents execute complex studies (e.g., wet‑lab robotics, hardware design) while maintaining claim‑level provenance and passing domain‑specific I1–I4 variants.
- Tools/workflows: Lab APIs for automated logging; domain evaluators (e.g., assay validity); hardware‑in‑the‑loop verification.
- Dependencies/assumptions: Reliable real‑world evaluators; safety oversight; data governance and calibration for non‑deterministic domains.
- Regulatory Certification for AI‑Generated Research (policy, healthcare, finance)
- What: Agencies adopt CoE‑based certifications for AI‑authored studies and disclosures (e.g., SaMD validation, model risk in finance); procurement mandates auditability.
- Tools/workflows: Standard audit templates; accredited third‑party verifiers; legal recognition of claim provenance artifacts.
- Dependencies/assumptions: Regulatory frameworks updated to accept automated audits; liability and audit‑trail standards.
- Reviewer‑Assist and Reproducibility Badges at Scale (academia, publishing)
- What: Automated pre‑review panels run I1–I4 and CPR, freeing human reviewers to focus on novelty and implications; reproducibility badges become default.
- Tools/workflows: Editorial pipelines with artifact sandboxes; structured rebuttals that address specific audit flags.
- Dependencies/assumptions: Secure artifact handling; compute budgets across publishers; norms for artifact sharing.
- Evidence‑Backed Scientific Search and QA (software; education, daily life)
- What: Search engines and assistants that answer questions with explicit evidence chains (paper → code/log → evaluator), not just citations; users can drill down to raw results.
- Tools/workflows: “Claim graph” retrieval and visualization; APIs for stepwise evidence inspection.
- Dependencies/assumptions: Sufficiently large corpus with claim‑level metadata; privacy constraints on logs.
- Benchmark Ecosystems Requiring CoE Compliance (software/ML community)
- What: New and existing benchmarks (e.g., MLE‑Bench, MLPerf) require submissions to pass I1–I4; marketplaces emerge for “verified” solutions.
- Tools/workflows: Submission portals with auto‑audit; reputational scoring tied to pass rates; longitudinal integrity metrics.
- Dependencies/assumptions: Community buy‑in; handling of non‑deterministic tasks with robust tolerances.
- Agent Oversight and AI Safety Tooling (cross‑industry)
- What: Generalize I2/I4 to detect reward hacking and goal drift in autonomous agents beyond research (e.g., operations, robotics, finance trading bots).
- Tools/workflows: Runtime monitors for spec adherence; offline post‑hoc alignment audits; escalation policies.
- Dependencies/assumptions: Formalized task specs; access to agent logs/actions; handling adversarial agents.
- Education at Scale: Claim‑Grounded Writing Assistants (education, daily life)
- What: Widespread assistants that enforce evidence tagging for claims in essays, reports, and theses; immediate feedback on citation validity and quant accuracy.
- Tools/workflows: LMS‑integrated writing aids; institution‑wide API gateways to literature databases.
- Dependencies/assumptions: Equity of access to tools; academic policy alignment on AI use.
- Evidence‑Aware Corporate Analytics and Governance (industry; finance/operations)
- What: Management relies on AI analytics accompanied by verifiable evidence chains; audit committees review CoE dashboards for key metrics before decisions.
- Tools/workflows: Enterprise data platforms with claim provenance; SOX‑style internal controls for AI‑generated KPIs.
- Dependencies/assumptions: Integration with data warehouses; change‑management and training; privacy/security controls.
- Knowledge Graphs of Claims and Evidence (software; research infrastructure)
- What: Public or consortial graphs linking claims to sources, code, and logs, enabling meta‑analysis and rapid detection of unsupported claims across literature.
- Tools/workflows: Open schemas and APIs; linkers between publications, repositories, and experiment registries.
- Dependencies/assumptions: Persistent identifiers for artifacts; community contribution and curation.
These applications leverage the paper’s core insight: make every claim traceable to its evidence and audit artifacts with system‑agnostic checks. In the near term, lightweight tooling (CI, plugins, submission gates) can materially reduce hallucinations, misreporting, and reward hacking. Longer term, CoE can underpin standards, platforms, and policies that raise the integrity baseline for AI‑enabled research and AI‑generated analyses across sectors.
Glossary
- ACID: A set of properties (atomicity, consistency, isolation, durability) ensuring reliable database transactions. Example: "Just as ACID\footnote{Atomicity, consistency, isolation, durability.}~\citep{haerder1983principles} defines what ``reliable'' means for a database transaction"
- ablation studies: Controlled experiments that remove or vary components to assess their impact on performance. Example: "a 4-stage experiment manager (preliminary investigation, hyperparameter tuning, research agenda execution, ablation studies)"
- adaptive tolerance: A variable acceptance threshold that adjusts to measurement or evaluator noise. Example: "within an adaptive tolerance that accounts for evaluator noise."
- ADRS (Automated Design of Research Systems): A benchmark suite of real research problems for evaluating autonomous research agents. Example: "We evaluate on the Automated Design of Research Systems (ADRS) benchmark"
- arXiv: An online repository of electronic preprints for scholarly papers. Example: "OpenAlex, Semantic Scholar, arXiv, Google Scholar"
- best-first tree search (BFTS): A search strategy that expands the most promising node first according to a heuristic. Example: "best-first tree search (BFTS) over experimental branches"
- Chain-of-Evidence (CoE): A verifiability framework requiring each claim to be traceable to its supporting evidence. Example: "We address this with Chain-of-Evidence (CoE), a verifiability framework for AI-driven research."
- Claim Provenance Rate (CPR): The fraction of quantitative claims in a paper that can be traced to matching experimental logs. Example: "numerical Claim Provenance Rate (CPR)"
- citation gaming: Manipulating citation details to make fabricated or misleading references appear legitimate. Example: "citation gaming (e.g., a real DOI attached to a fabricated description)"
- citation graph: A network of publications connected by their citation relationships, often used for literature exploration. Example: "builds a citation graph via scholarly database queries"
- CoE Integrity Audit: A post-hoc verification procedure checking whether paper claims are supported by underlying artifacts. Example: "CoE Integrity Audit is a post-hoc audit that checks whether claims in a completed paper are supported by the underlying artifacts"
- CrossRef: A scholarly infrastructure service providing DOI registration and metadata for publications. Example: "Semantic Scholar, arXiv, OpenAlex, CrossRef"
- directed Steiner tree: A minimum-cost network connecting a root to specified terminals in a directed graph. Example: "a minimum-weight directed Steiner tree"
- DOI: A persistent digital identifier for scholarly objects like papers. Example: "using arXiv ID, DOI, and title."
- Edmonds' arborescence: An optimal directed spanning tree (branching) structure in graphs, computed by Edmonds' algorithm. Example: "beam search with Edmonds' arborescence vs.\ greedy edge penalization"
- egress fees: Costs charged by cloud providers for data leaving their networks. Example: "ensure that shared path prefixes minimize egress fees."
- evidence chain: A recorded, step-by-step linkage from a claim back to its grounding source materials. Example: "trace, through a recorded evidence chain, to a grounding source."
- evidence tag: An inline annotation binding a specific claim in text to its supporting artifact or source. Example: "every factual claim carries an inline evidence tag"
- evaluator variance: Inherent randomness or variability in benchmark evaluators that affects measured scores. Example: "to account for inherent evaluator variance."
- EPLB (expert-parallel load balancing): A task concerned with balancing workload across experts in MoE models. Example: "EPLB (expert-parallel load balancing for MoE models)"
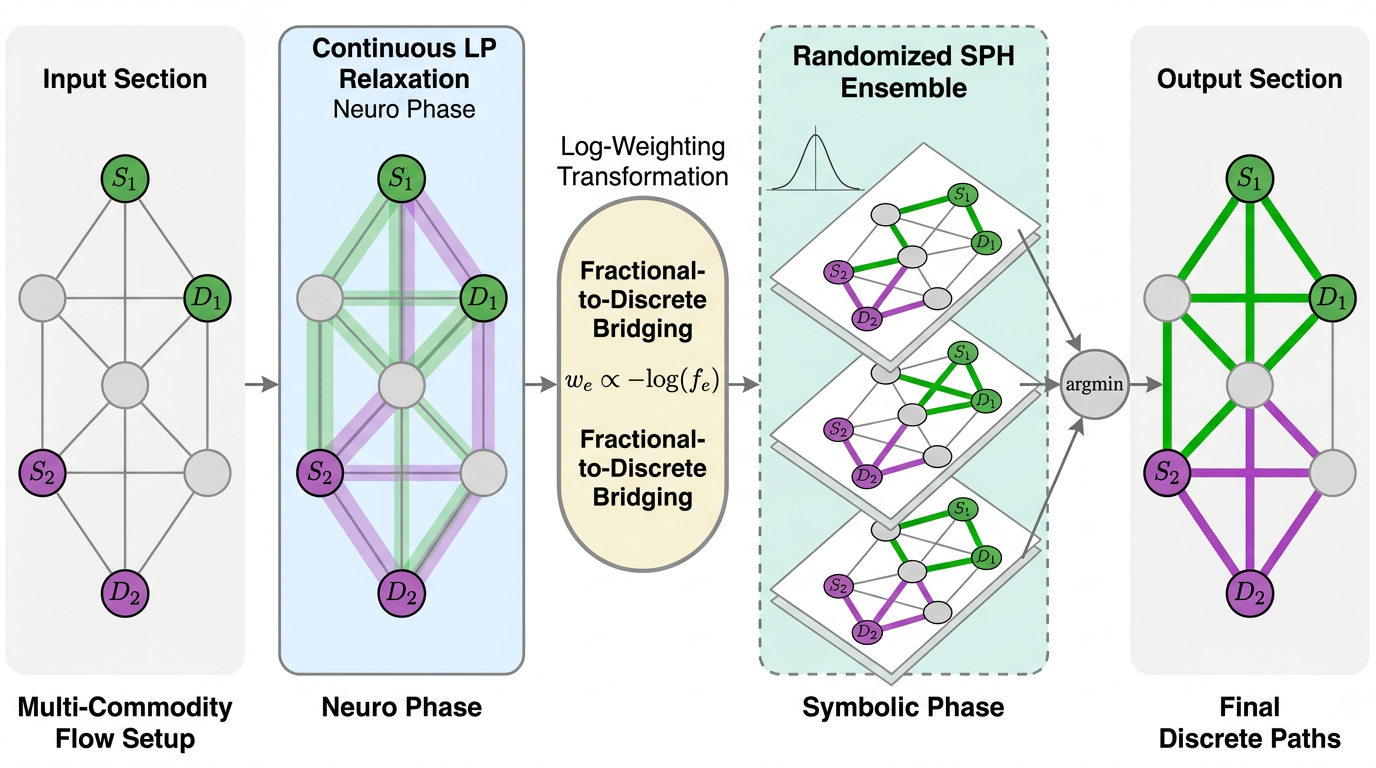
- Fractional Multi-Commodity Flow LP relaxation: A linear-programming relaxation allowing fractional flows for multiple commodities to approximate discrete routing. Example: "Fractional Multi-Commodity Flow LP relaxation"
- golden evaluator: The canonical, trusted evaluator used as ground truth for scoring solutions. Example: "re-running the submitted solution on the golden evaluator"
- hallucinated references: Bibliography entries that do not correspond to any real, verifiable publication. Example: "Entries matching no record are classified as hallucinated references."
- hyperparameter tuning: Systematic search over non-learned configuration parameters to optimize performance. Example: "hyperparameter tuning"
- LLM prefix cache: A mechanism caching token prefix computations to accelerate LLM inference. Example: "LLM-SQL (tabular data layout for LLM prefix cache reuse)"
- LLM-judged abstract entailment: Using a LLM to determine whether a paper’s abstract supports a cited claim. Example: "with LLM-judged abstract entailment"
- makespan minimization: Reducing the total completion time of a set of tasks in scheduling problems. Example: "TXN (transaction scheduling for makespan minimization)"
- MCP tool servers: External tool services integrated with agents to provide execution, memory, or artifact management capabilities. Example: "using MCP tool servers for execution, memory, and artifacts."
- Method--Code Alignment (I4): An integrity check judging whether the paper’s method description matches the submitted code. Example: "Method--Code Alignment (I4)."
- Mixture-of-Experts (MoE) models: Architectures that route inputs to specialized subnetworks (“experts”) for efficiency and performance. Example: "MoE models"
- MLE-Bench: A benchmark evaluating machine learning engineering tasks for autonomous agents. Example: "gold medals on MLE-Bench tasks"
- neuro-symbolic solver: A system combining neural learning with symbolic reasoning or algorithms. Example: "hybrid neuro-symbolic solver"
- OpenAlex: An open index of scholarly papers, authors, venues, and institutions. Example: "Semantic Scholar, arXiv, OpenAlex, CrossRef"
- Parallel Explore-Exploit (PEE): An orchestrator running multiple solution branches in parallel, balancing exploration and exploitation. Example: "Parallel Explore-Exploit (PEE) orchestrator"
- Parameter Golf: A benchmark evaluating performance under strict parameter-count constraints. Example: "state-of-the-art on Parameter Golf"
- parameter-constrained language modeling: Language modeling under limits on model size or parameter budget. Example: "parameter-constrained language modeling"
- post-hoc audit: An analysis performed after system output is produced, rather than during generation. Example: "a post-hoc audit"
- prefix-cache hit metric: A performance metric measuring effectiveness of prefix caching (e.g., in LLM serving). Example: "prefix-cache hit metric."
- provenance metadata: Recorded information about the origin and processing history of data or claims. Example: "recorded with provenance metadata."
- Randomized Shortest Path Heuristic (SPH): A heuristic that introduces randomness into shortest-path computations to diversify solutions. Example: "Randomized Shortest Path Heuristics (SPH)"
- Reference Verification (I3): An integrity check verifying that bibliography entries correspond to real publications and correct metadata. Example: "Reference Verification (I3)."
- review-aware reporting: Writing strategies that anticipate reviewer expectations and feedback. Example: "review-aware reporting"
- Score Verification (I1): An integrity check that re-runs code to confirm reported results match evaluator outputs. Example: "Score Verification (I1)."
- score cherry-picking: Selecting the most favorable among multiple results rather than the appropriate or reproducible one. Example: "cross-stage score cherry-picking"
- Semantic Scholar: A scholarly search engine and corpus used for literature retrieval and metadata. Example: "Semantic Scholar"
- Specification Violation (I2): An integrity check detecting code that breaks task rules or exploits the evaluator. Example: "Specification Violation (I2)."
- state-of-the-art: The best performance achieved to date on a task or benchmark. Example: "state-of-the-art on Parameter Golf"
Collections
Sign up for free to add this paper to one or more collections.