Eigen-Spike Emergence and Quadratic Equivalents for Conjugate Kernels on Nonlinearly Separable Data
Published 28 May 2026 in stat.ML, cs.LG, math.PR, and math.ST | (2605.29669v1)
Abstract: Recent work in random matrix theory (RMT) has developed the notion of deterministic equivalents: typically linear surrogate models that approximate the spectral behavior of large nonlinear random matrices, such as nonlinear feature maps in neural networks (NNs). On the one hand, these deterministic equivalents make theoretical predictions tractable by reducing a complex model to a simpler model with properties that fall under the umbrella of classical RMT tools. However, this leaves open the question of whether this idealized linear equivalence remains meaningful when dealing with high-dimensional nonlinearly separable data, such as performing clssification on nonlinearly separable data. Motivated by this, we consider the conjugate kernel (CK), which is the nonlinear feature map of a feedforward NN, under a canonical nonlinearly separable dataset, the XOR problem; and we use the study of informative outlier eigenvalues in the CK and whether their corresponding eigenvectors asymptotically align with XOR labels as a proxy for nonlinear learnability. We develop a robust quadratic equivalent to the spiked CK matrix that enables a precise analysis of emergent informative spikes, as one modifies various knobs common in ML practice: sample complexity, signal-to-noise ratio (SNR), nonlinear activation choice, and pretrained features. In each of these scenarios, we derive a precise BBP-type phase transition in which linear classification via the CK eigenvectors becomes possible. Our analysis helps translate the power of deterministic equivalence tools in RMT to study problems of practical relevance in ML.
The paper introduces a quadratic equivalent framework to precisely characterize the emergence of informative spectral spikes in conjugate kernel matrices.
The study identifies BBP-type phase transitions where SNR and activation nonlinearity determine when kernel eigendirections align with XOR class labels.
The analysis demonstrates that weight structure, including spiked or pretrained weights, can induce an order-one spectral spike that enables effective linear classification.
Eigen-Spike Emergence and Quadratic Equivalents for Conjugate Kernels on Nonlinearly Separable Data
Introduction and Motivation
This paper presents a rigorous random matrix theory (RMT) analysis of the emergence and informativeness of spectral outlier eigenvalues (“spikes”) in the Conjugate Kernel (CK) matrices arising from random one-hidden-layer neural networks, focusing on the classical XOR problem as an archetype of nonlinearly separable data. Building upon recent advances in deterministic and polynomial equivalents for nonlinear random matrix models, the authors systematically investigate the conditions under which nonlinear structure in the dataset becomes spectrally accessible—meaning that outlier eigenvectors of the CK become aligned with the underlying nonlinear class labels, enabling linear classification in feature space.
A key technical contribution is the construction of a robust quadratic equivalent (QE) framework capable of precisely characterizing emergent informative spikes across a broad range of settings. This includes variations in sample complexity, signal-to-noise ratio (SNR), weight structure (e.g., pretrained weights), and nonlinear activation function. The analysis reveals distinct phase transitions—of BBP (Baik–Ben Arous–Péché) type—in which informative spikes appear or vanish, sharply delineating the regimes where kernel methods can succeed or necessarily fail on nonlinearly separable tasks.
Theoretical Framework and Model
The object of study is the CK matrix
K=Y⊤Y,Y=N1σ(WX)
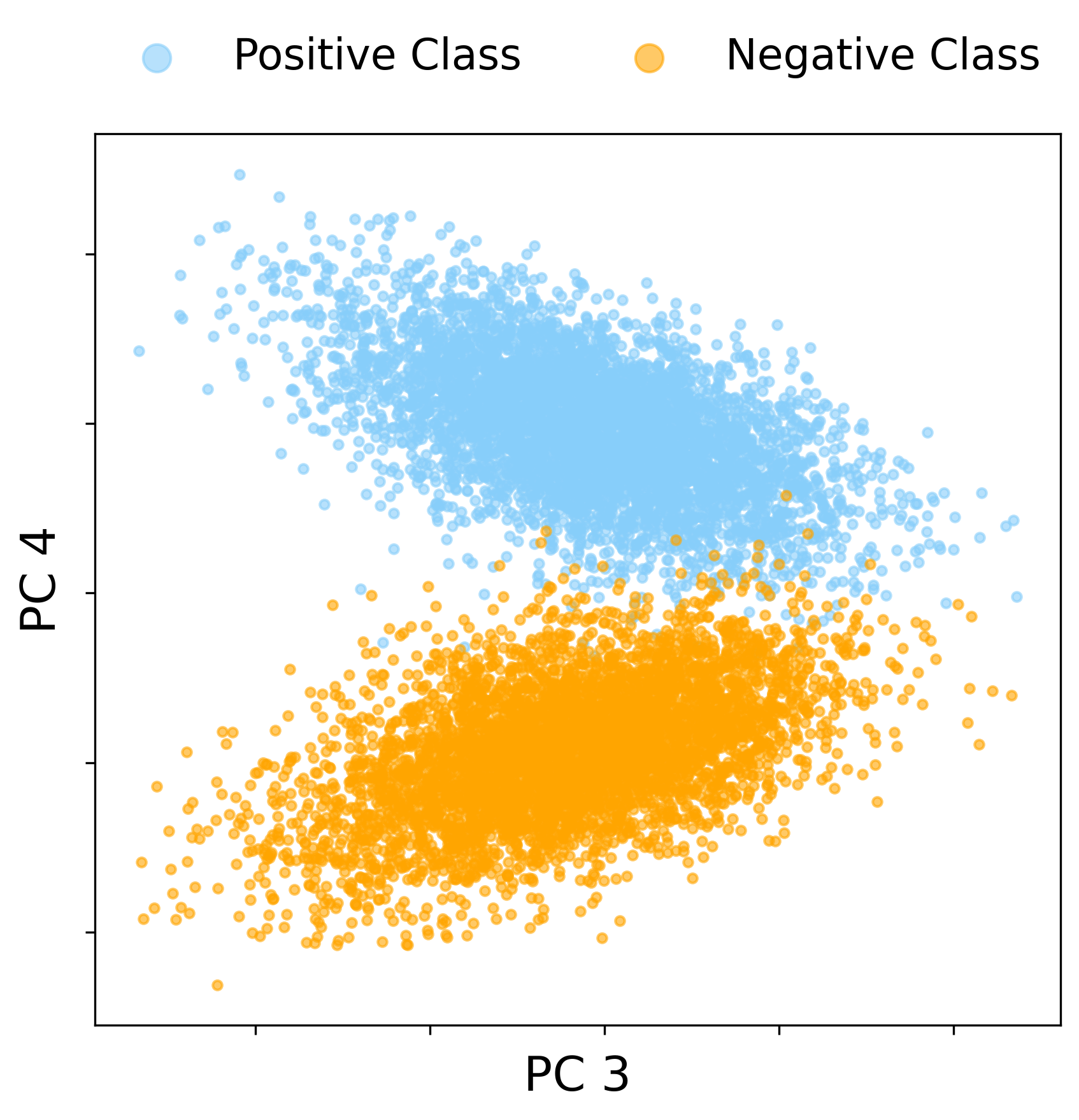
where σ is a nonlinear activation, W∈RN×d is a random weight matrix, and the data matrix X∈Rd×n encodes the high-dimensional XOR Gaussian mixture setting—two balanced classes with vanishing mean, linearly inseparable but quadratically separable structure.
The standard RMT approach (deterministic equivalent) typically linearizes nonlinear feature maps, but this fails in high-dimensional nonlinearly separable data, as the linearized kernel loses the necessary quadratic discriminative structure. The authors, therefore, develop a quadratic approximation to the kernel random matrix, tracking linear and quadratic spike strengths and their alignment to the label structure as all major “knobs” of the problem are varied.
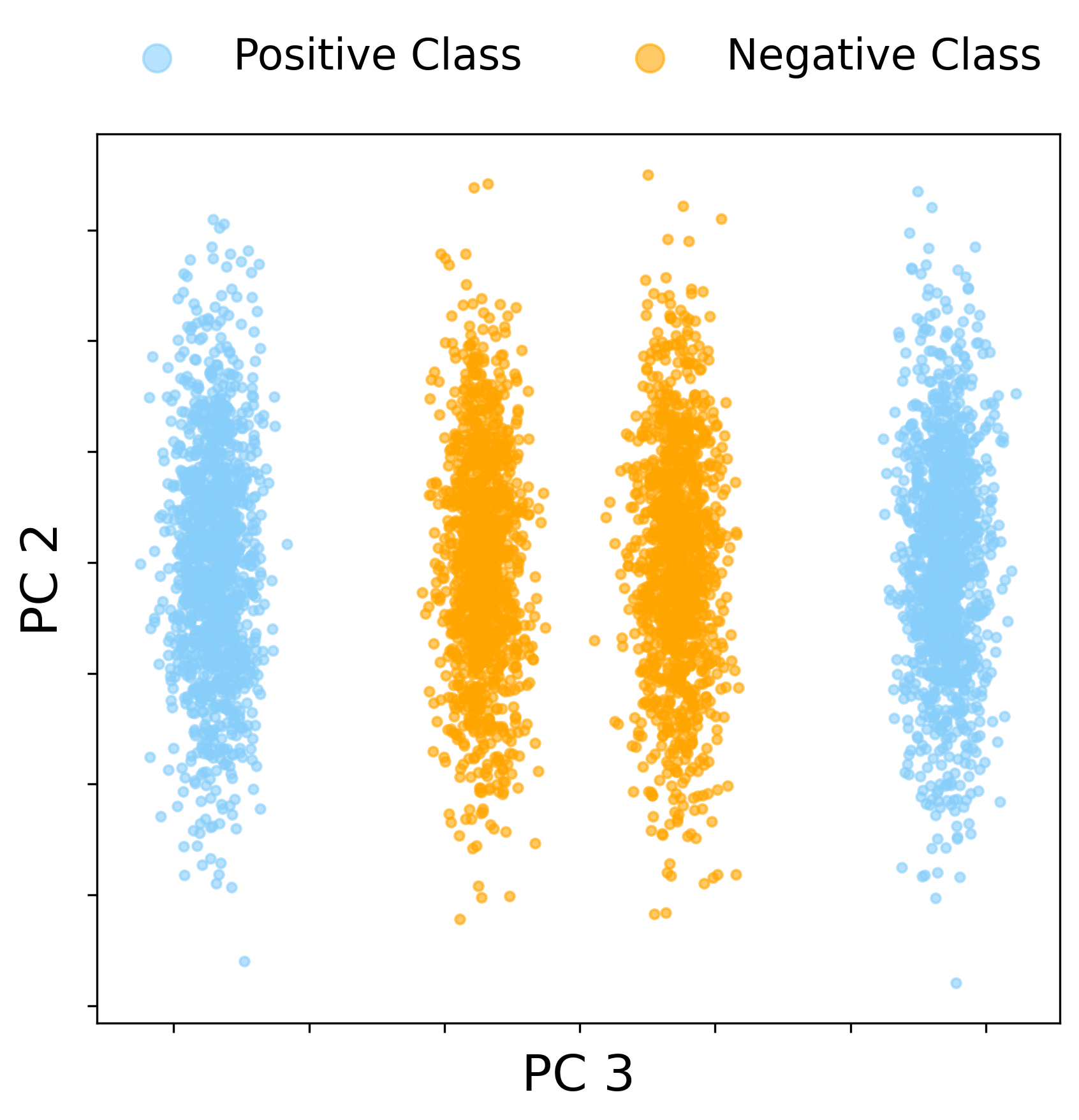
Failure of Linear Equivalents in Proportional Limit (Finite SNR)
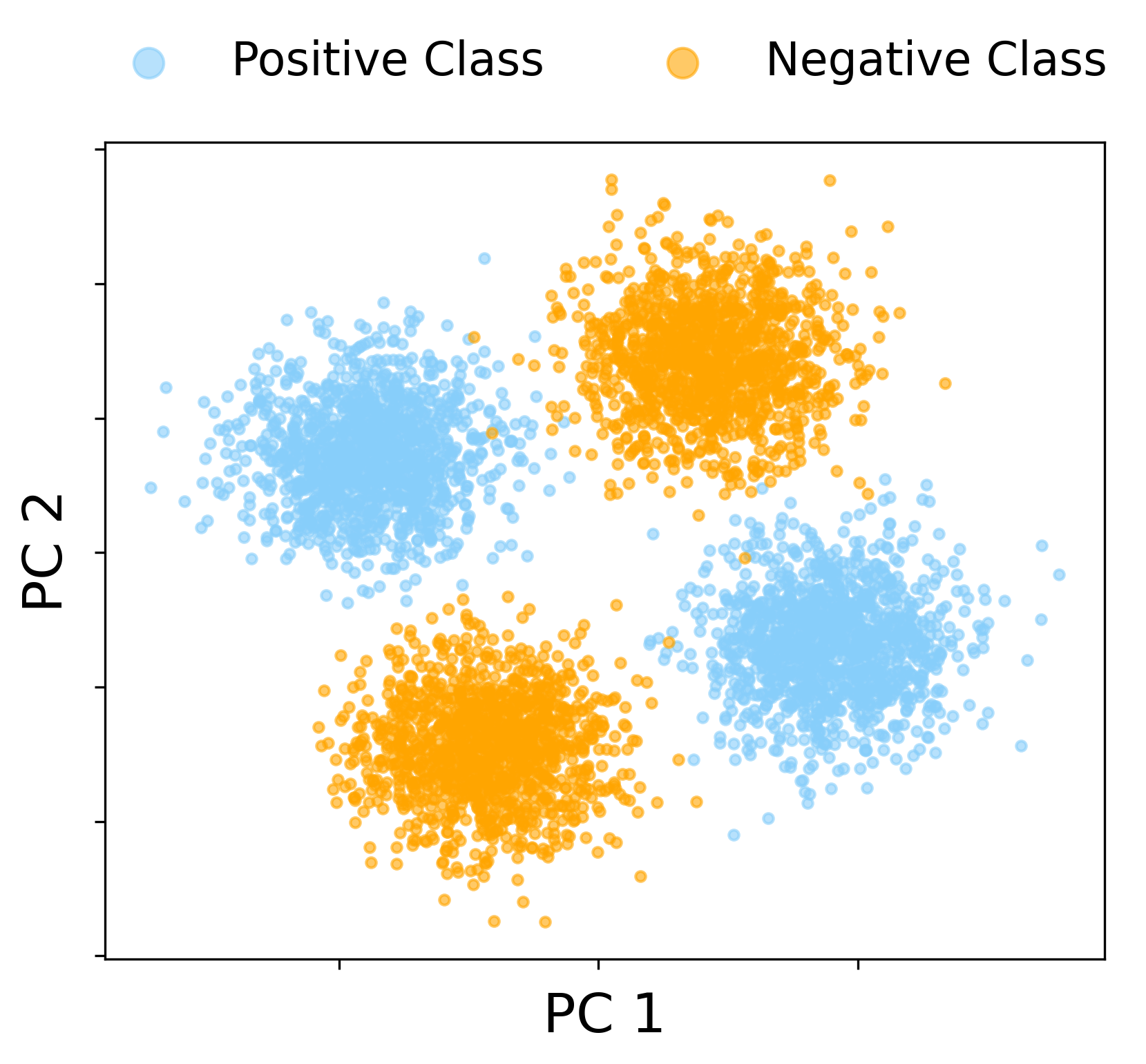
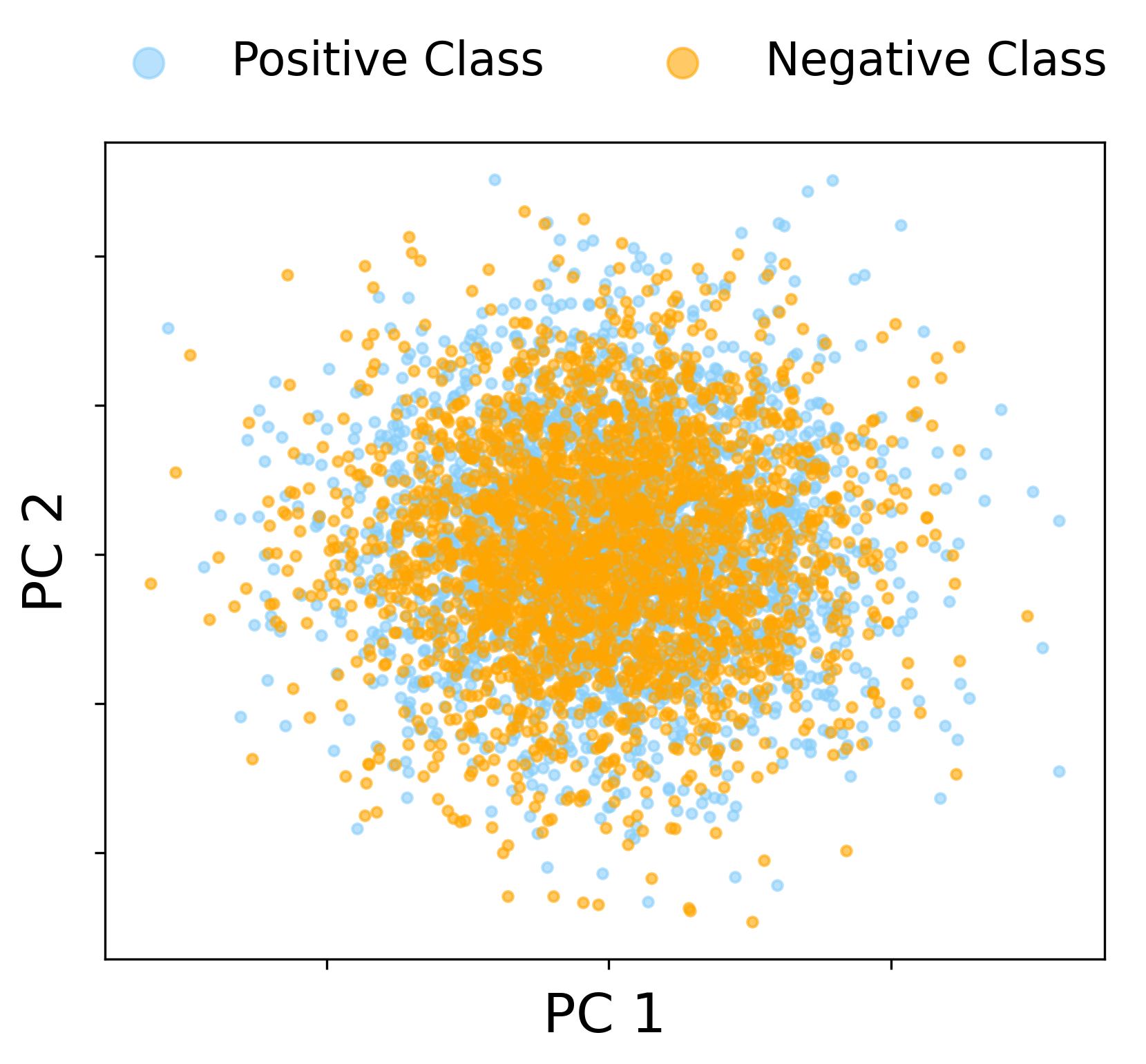
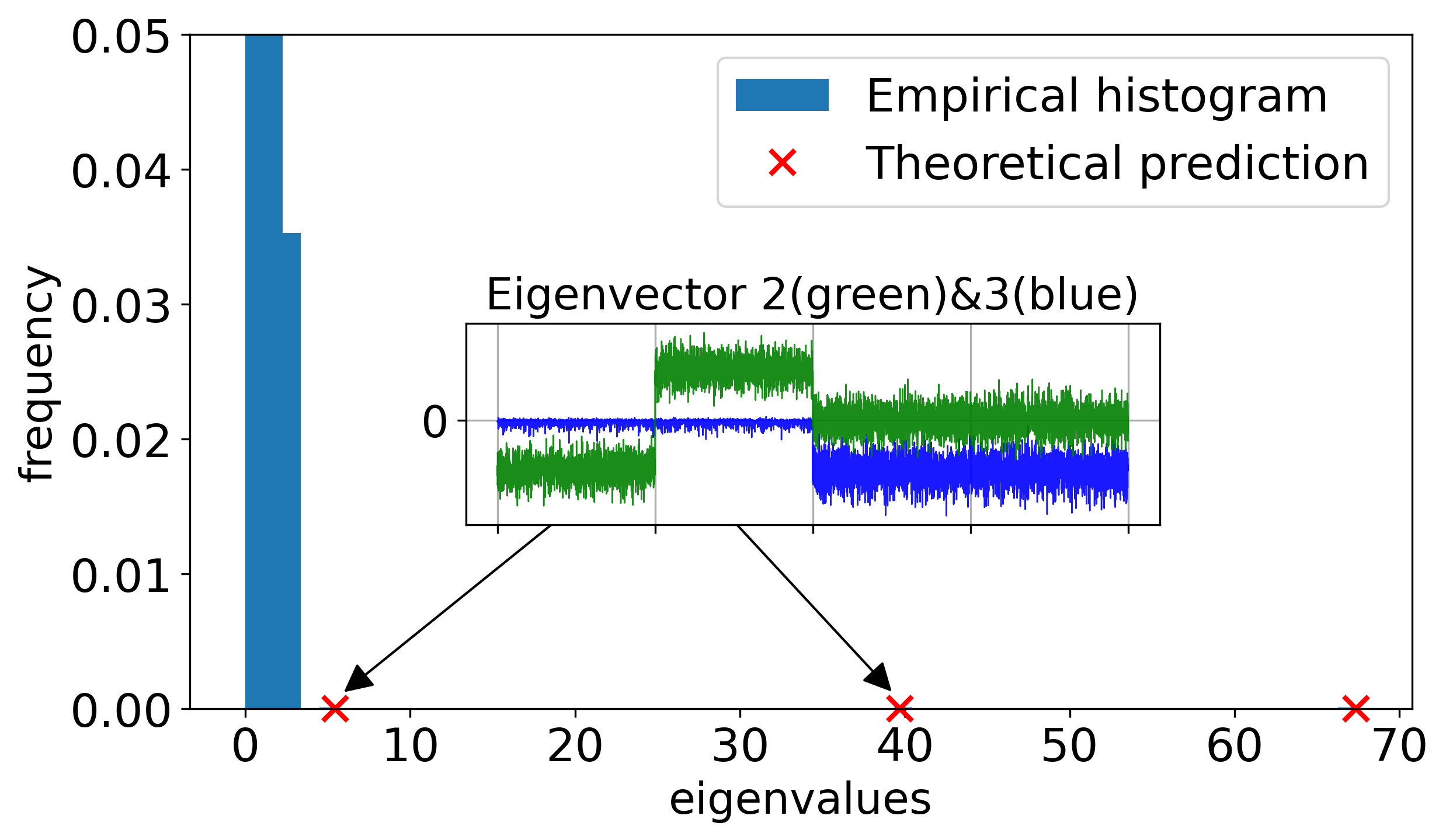
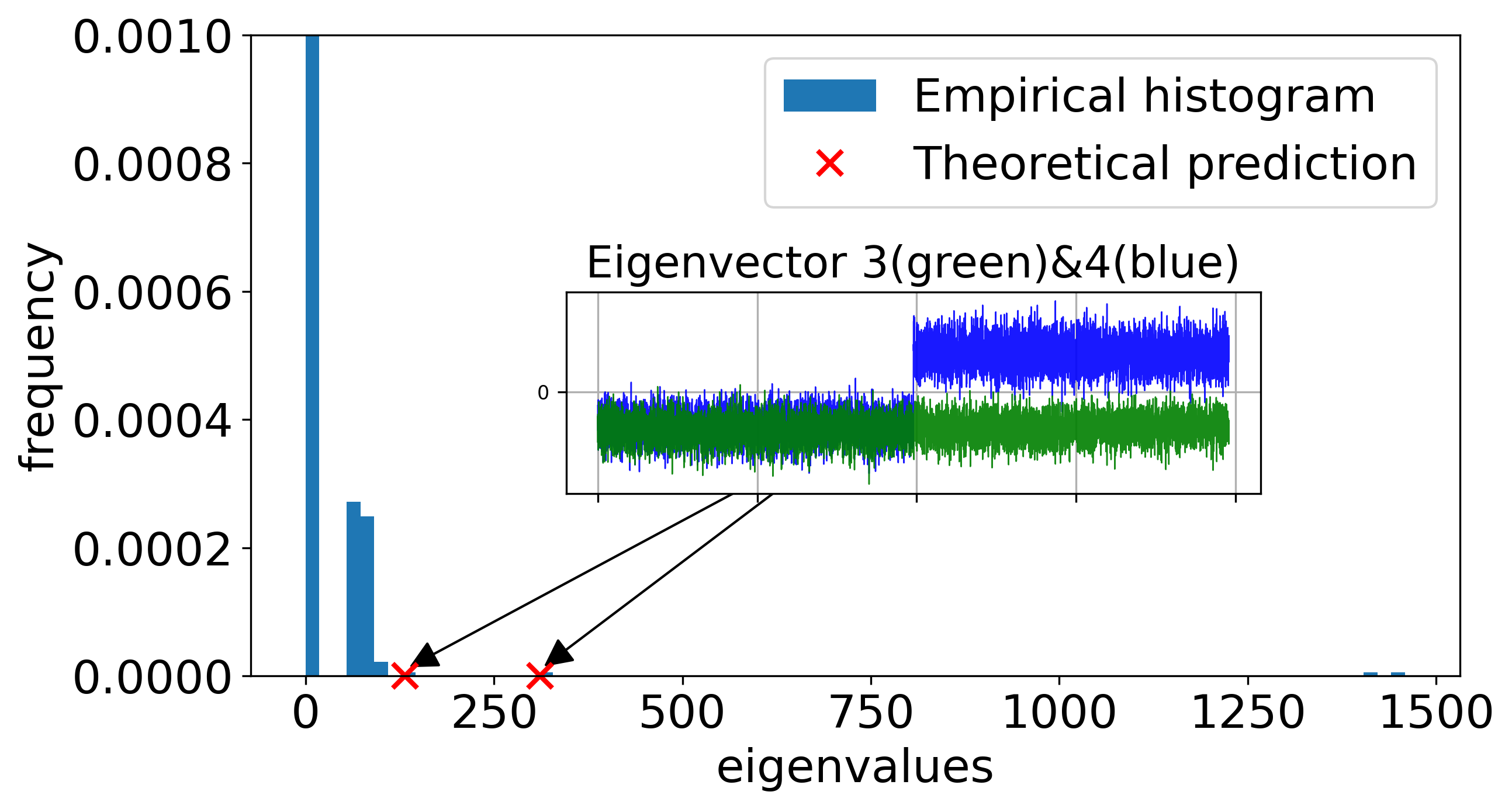
In the baseline regime with proportional scaling (n≍d≍N) and finite SNR, the spectrum of the CK matrix does exhibit outlier eigenvalues, but the associated eigenvectors do not align with the class labels. Instead, the two leading spike directions reflect nuisance geometric structure of the mixture, rather than capturing the XOR labeling. Thus, linear classification fails on the leading eigenspace of the CK in this regime, and even sophisticated kernel spectral clustering does not resolve the XOR classes.
Figure 1: In the finite-SNR proportional regime, the leading CK spectral directions reflect the four-fold XOR data geometry, but do not yield label alignment; spectral spikes are uninformative for classification.
This regime is characterized numerically and theoretically via a detailed RMT calculation of the BBP phase threshold for uninformative and linear spikes, rigorously showing label orthogonality of the leading eigenspace.
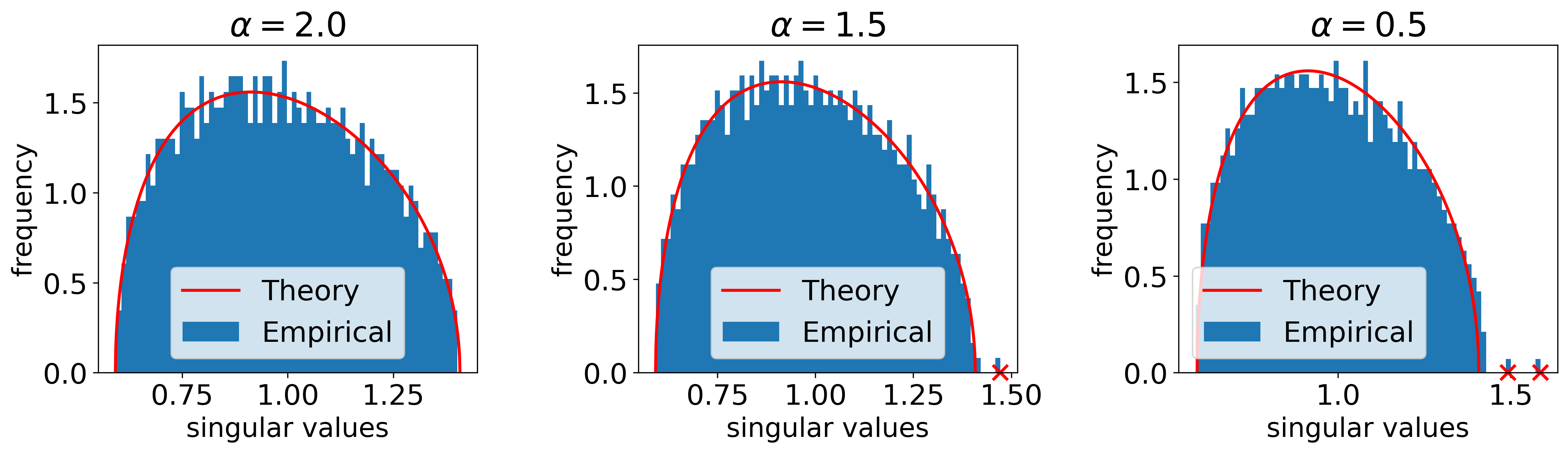
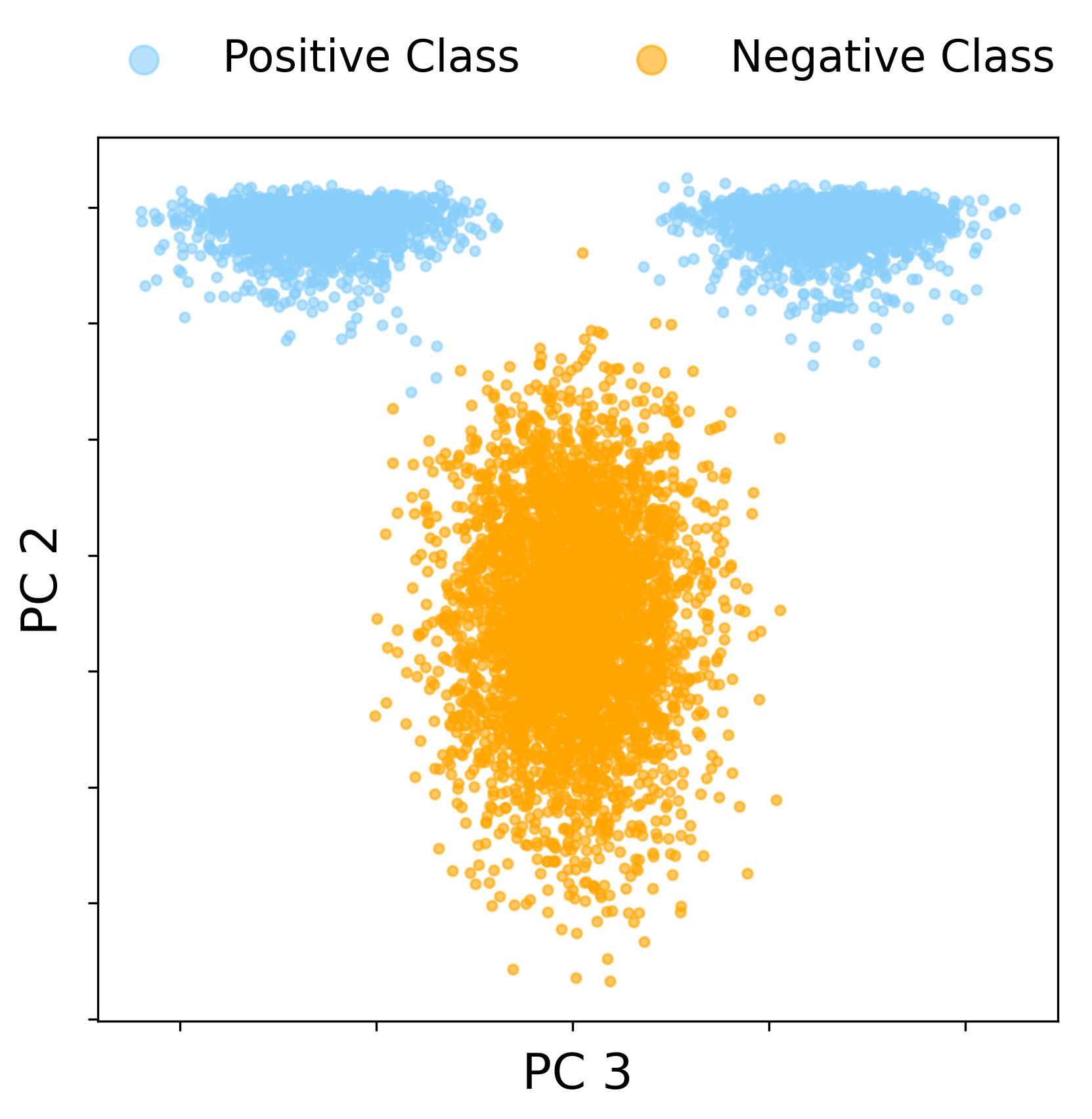
Spectral Phase Transition with SNR and Activation: Quadratic Informative Spikes
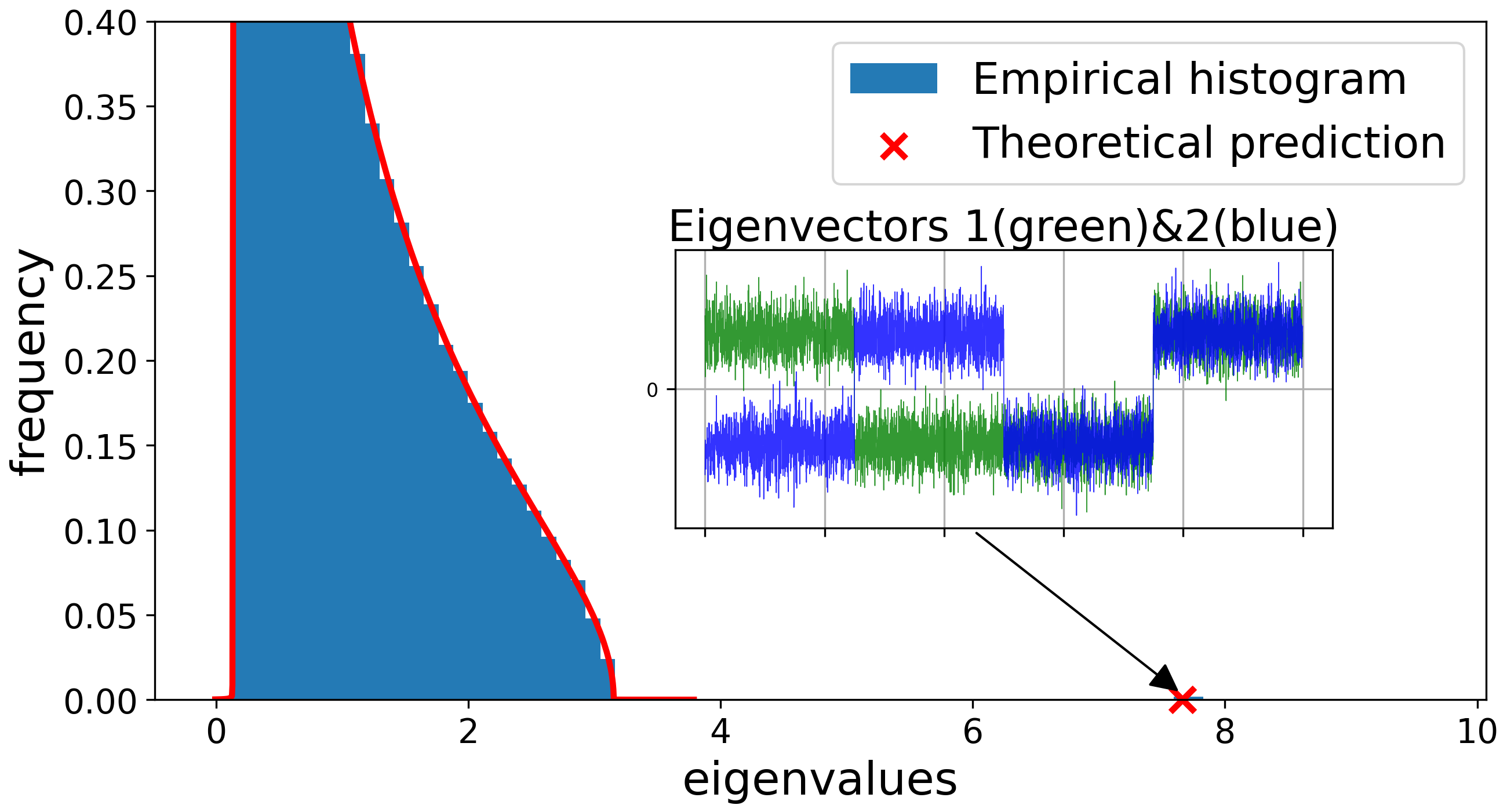
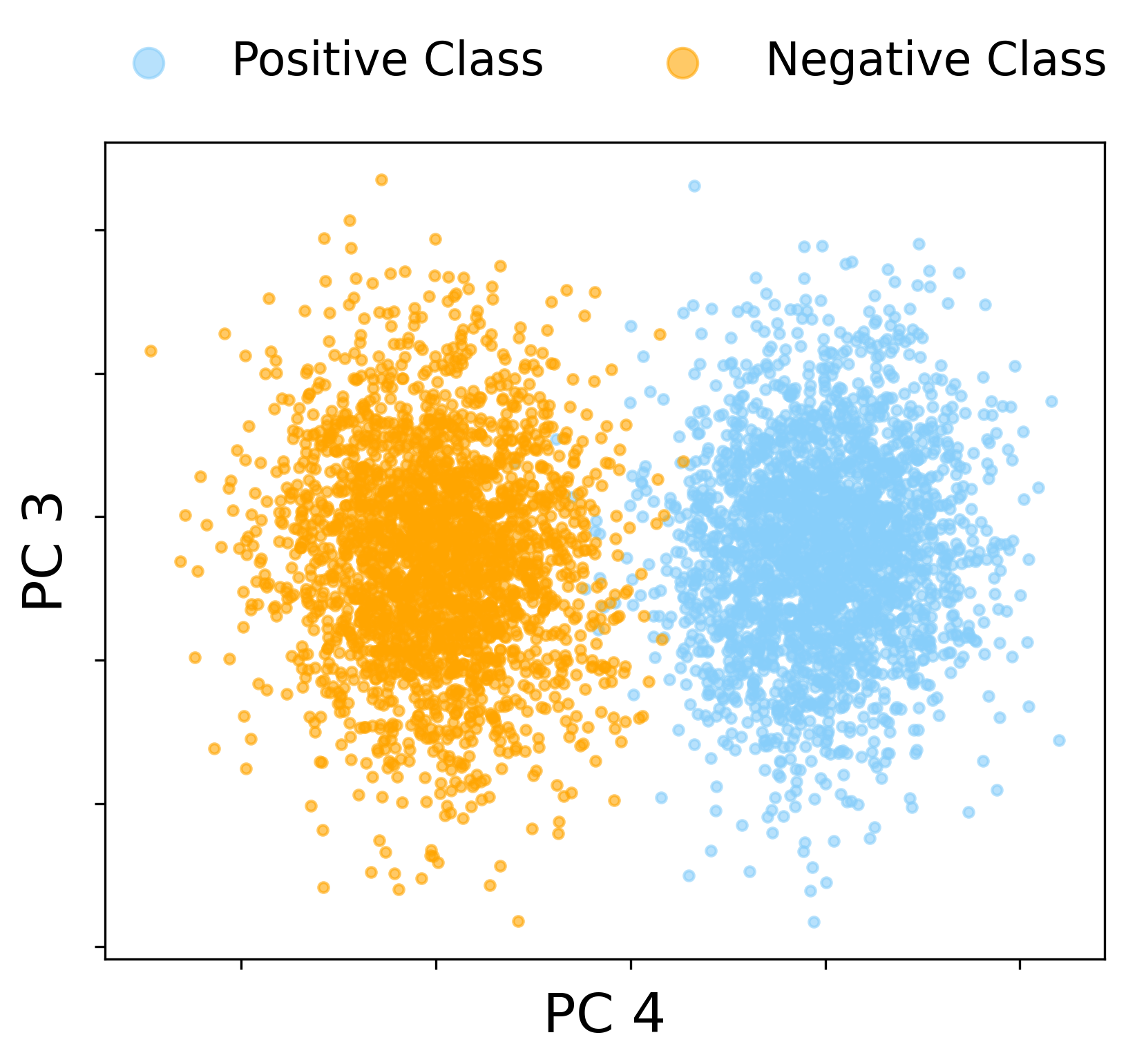
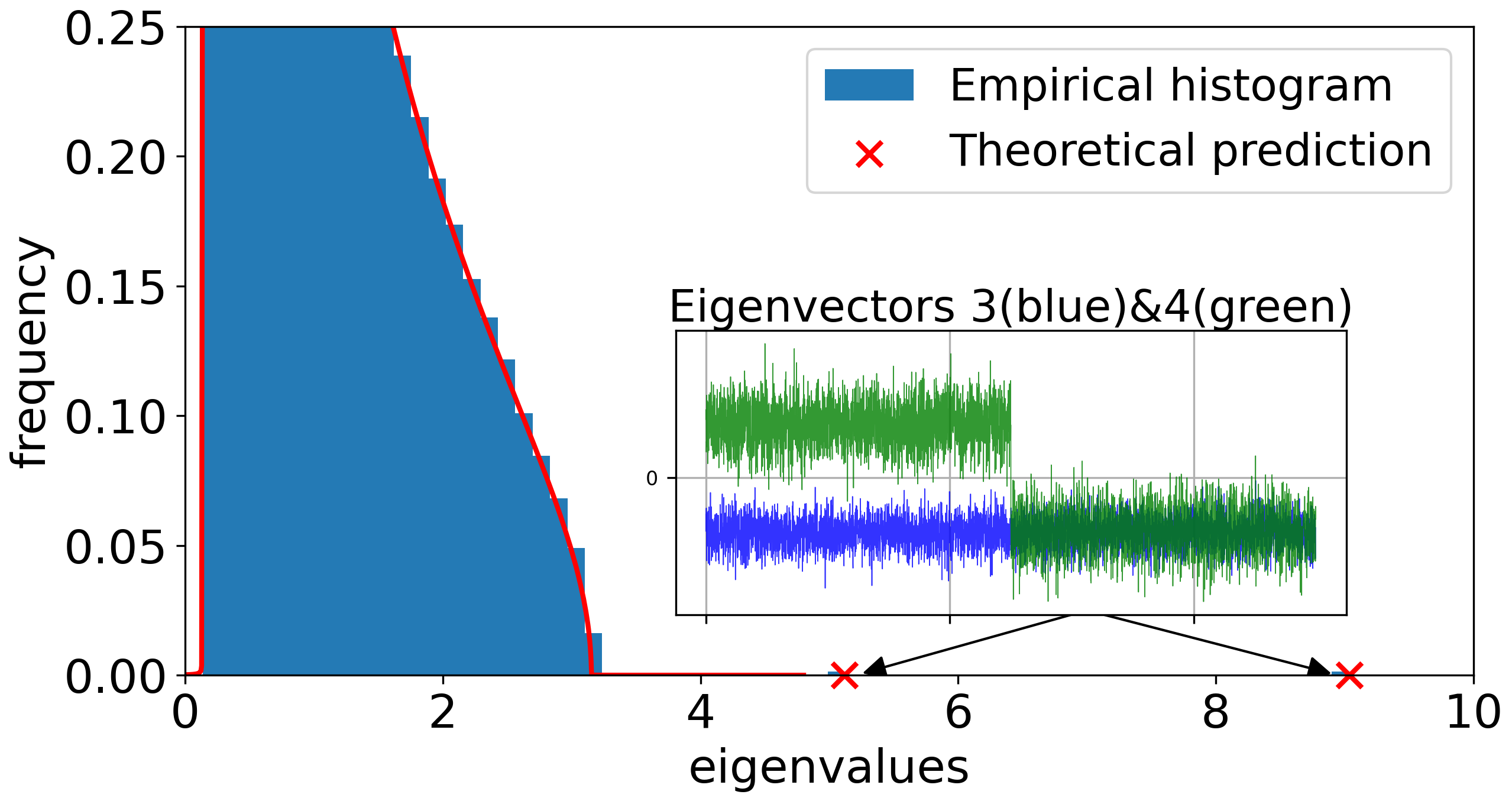
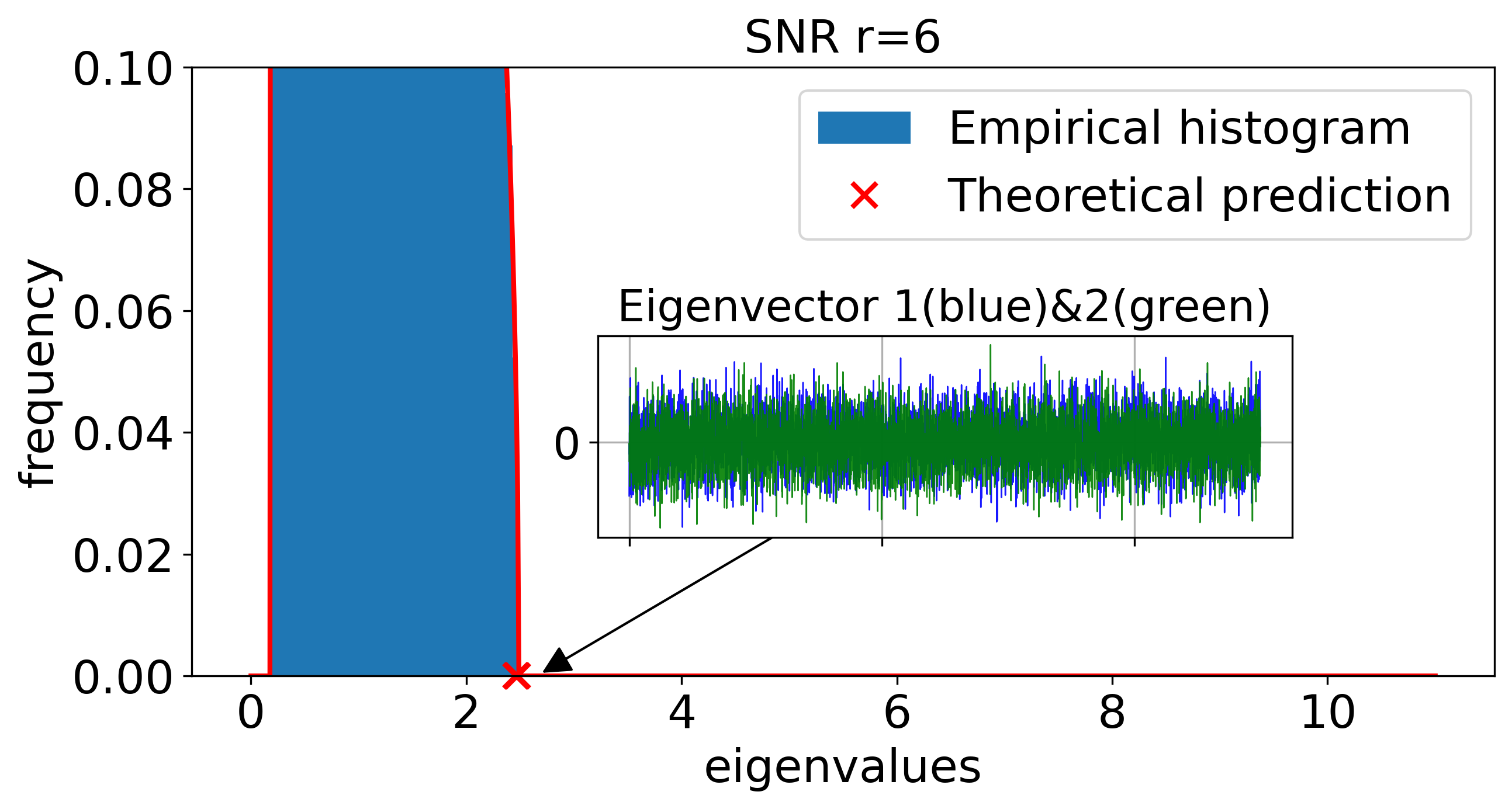
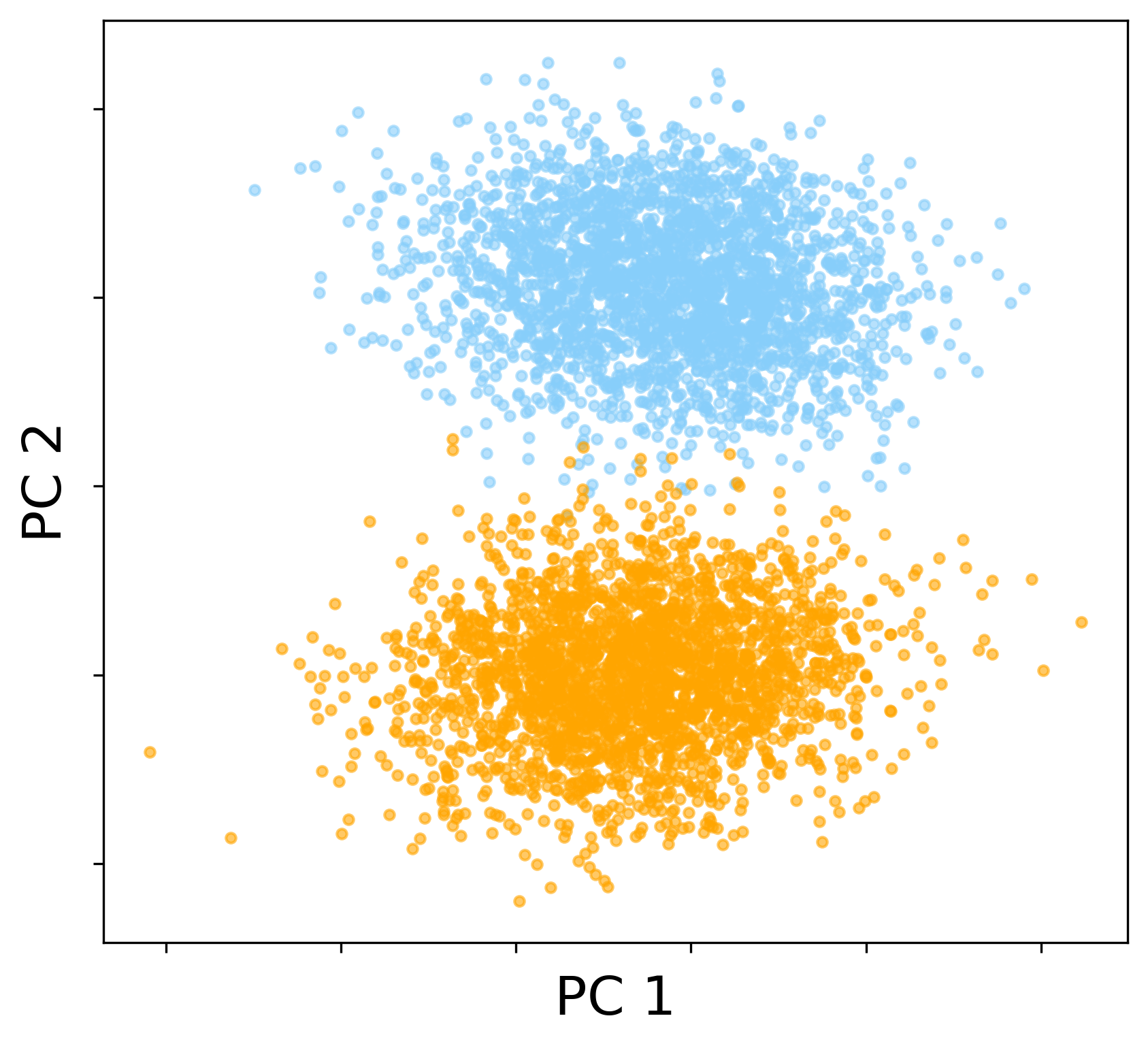
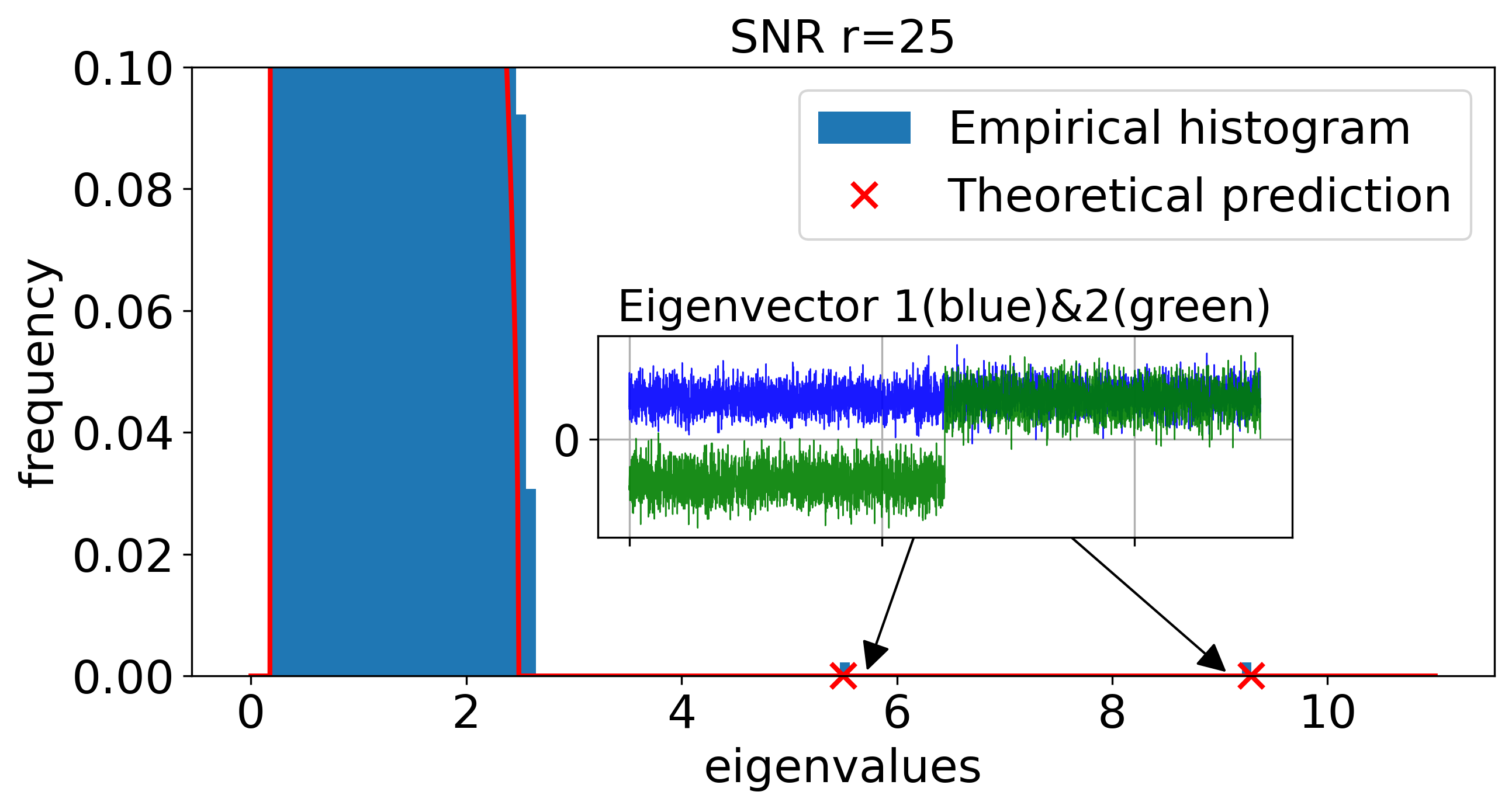
A primary result is the BBP-type phase transition in the large-SNR regime. As SNR is increased (e.g., r=r0n1/4), the quadratic term in the CK matrix’s Hermite expansion becomes non-negligible, and a pair of order-one quadratic outlier eigenvalues emerges, whose eigenvectors become asymptotically aligned with the XOR labels—enabling spectral linear classification in CK feature space.
This transition is sharply controlled by the activation’s quadratic Hermite coefficient cσ, vanishing exactly when cσ=0 (e.g., odd activations like centered tanh). Theoretical predictions are robustly matched by simulations.
Figure 2: In the large-SNR regime, label-aligned quadratic spectral spikes emerge, rendering the XOR classes linearly separable in the CK eigenspace.
Figure 3: CK spectra under increasing SNR: quadratic spikes emerge from the bulk precisely when the BBP threshold is crossed, with corresponding eigenspace alignment to the class labels.
Activation Knob and Nonlinearity: Role of Hermite Coefficients
The emergence and informativeness of spectral spikes are finely controlled by the activation function. By varying activations within a parametric family maintaining bσ=0 but interpolating σ0, the CK’s spectrum exhibits a pure “unstructured” (non-label informed) spike when σ1 increases, but no informative spike appears unless the quadratic feature channel is open.
Figure 4: As σ2 increases, uninformative spikes develop in the CK spectrum, but label alignment only arises for suitable nonzero quadratic component.
Strikingly, with activations such as σ3 (centered), σ4, so no quadratic channel exists, and even at large SNR the CK’s outlier directions remain spectrally orthogonal to the label, as validated analytically and empirically.
Figure 5: For activations with vanishing σ5, e.g., centered σ6, separated CK spikes can arise but remain orthogonal to the XOR labels for all SNR.
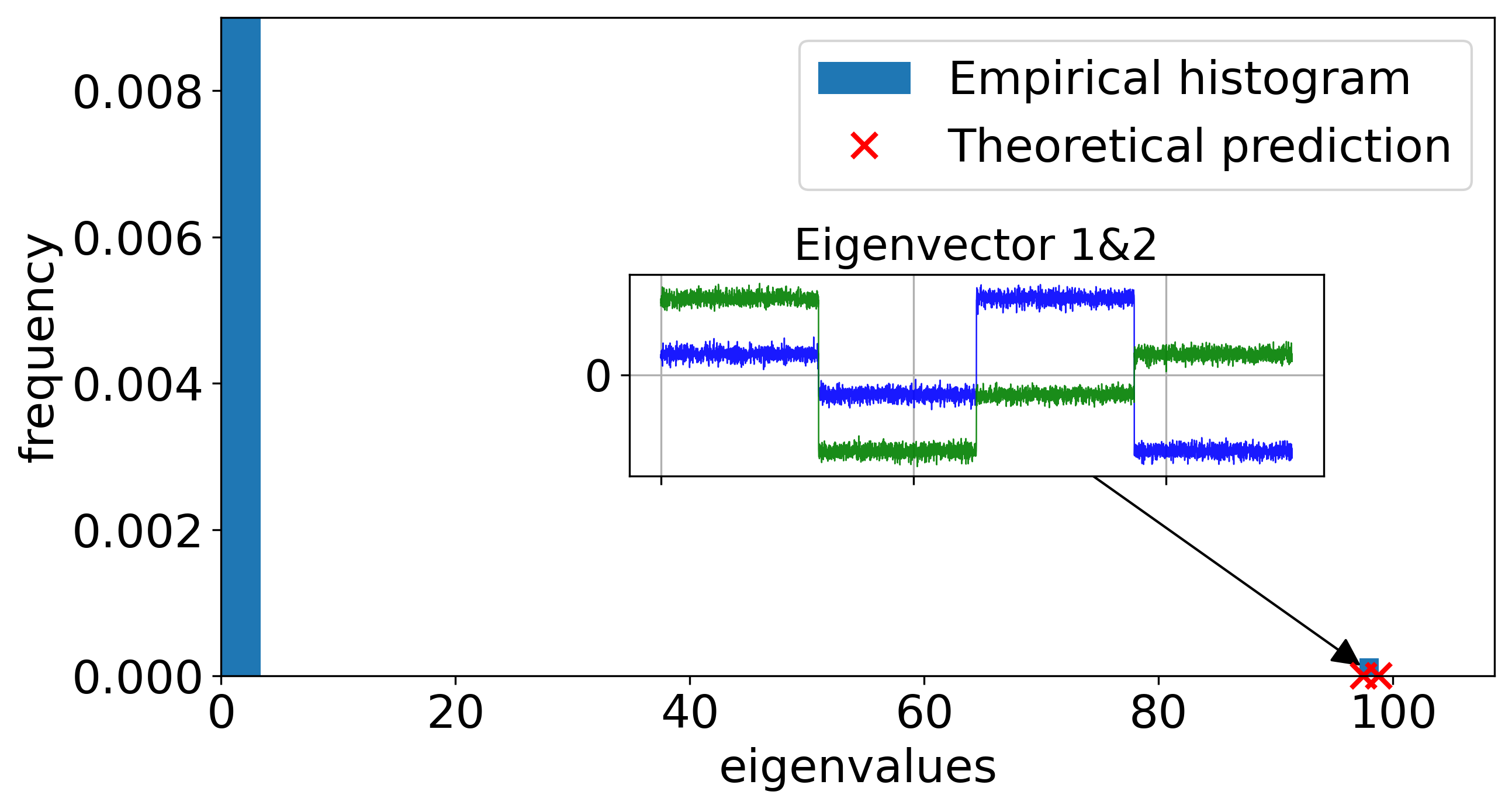
Learned or Spiked Weights: Emergence of Label-Aligned CK Spikes
A second axis of analysis concerns the effect of learned, structured weights. The authors analyze a rank-one “spiked” weight model and observe that the induced CK matrix develops a large spike, with a coexisting order-one spectral spike perfectly aligned with the XOR labels, even at moderate SNR. This is theoretically predicted and numerically confirmed.
Figure 6: In the spiked weight regime, a dominant weight-induced CK spike coexists with a subdominant informative spike aligned with the XOR labels, enabling linear separation even at baseline SNR.
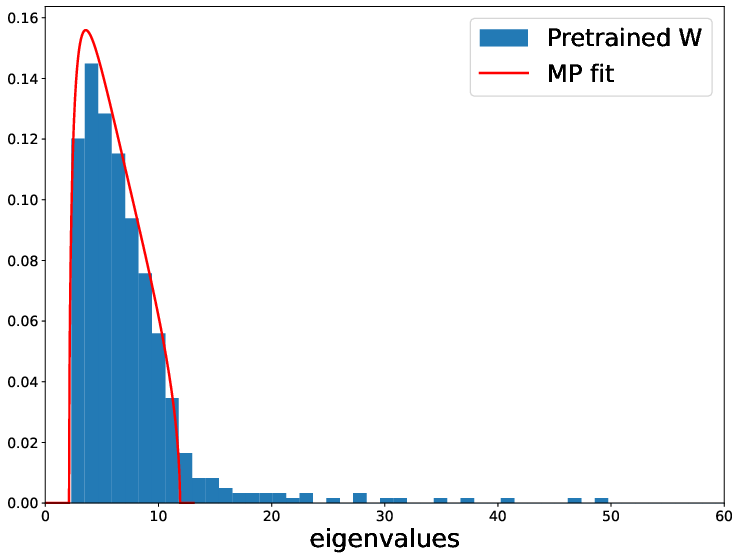
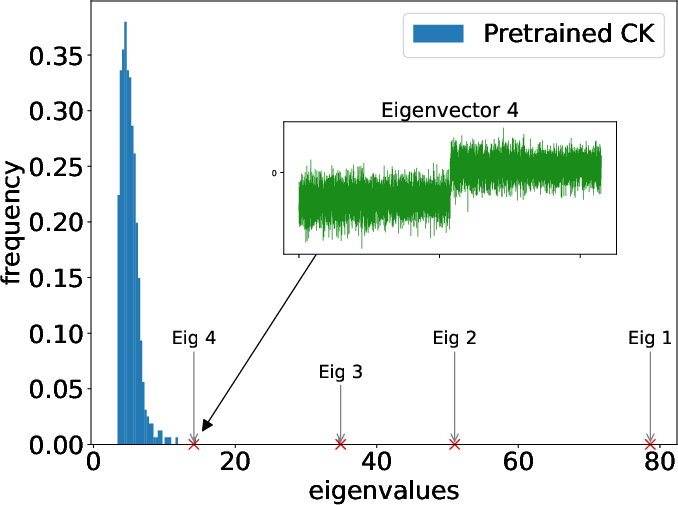
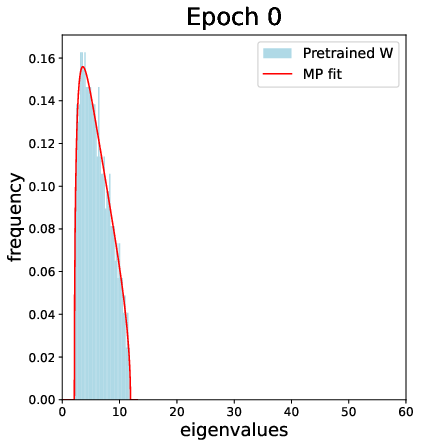
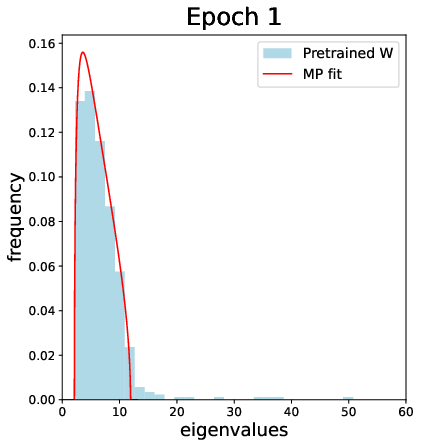
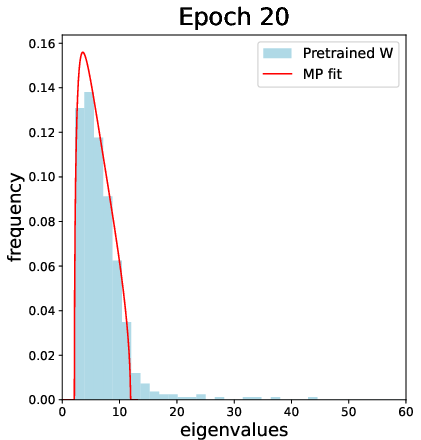
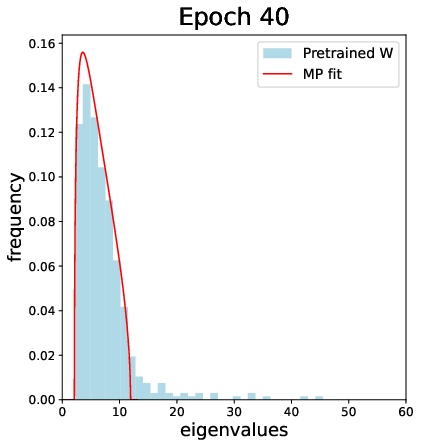
The empirical section further studies truly pretrained weights (e.g., from a CIFAR-2 network), showing the emergence and label alignment of CK spikes as a function of training, documenting the spectral transition and highlighting the practical implications for transferability and deep feature learning.
Figure 7: For pretrained weights from a deep network, the CK spectrum exhibits outlier spikes with strong label alignment, observed after sufficient training epochs.
Sample Complexity “Knob”: Quadratic Sample-Size Regime and Polynomial Equivalents
In the σ7 regime (“quadratic scaling”), a different polynomial equivalent kicks in, and the CK is well-approximated by a quadratic polynomial kernel. Even at finite SNR, informative quadratic spikes appear and are label-aligned, confirming recent theoretical predictions about the polynomial regime and quadratic equivalence.
Figure 8: In the quadratic sample-size regime, the CK spectrum reveals label-aligned spikes beyond the leading directions, with linear class separation available from these spectral coordinates.
Empirical Dynamics: Training and Spectral Phase Transitions
Additional simulations track the spectral evolution of both weights and CK matrices over training on realistic data, illustrating the emergence and phase transition of informative spikes, and nontrivial alignment of leading CK eigenvectors to synthetic XOR labels after sufficient training and “bleed-out” of the bulk spectrum.
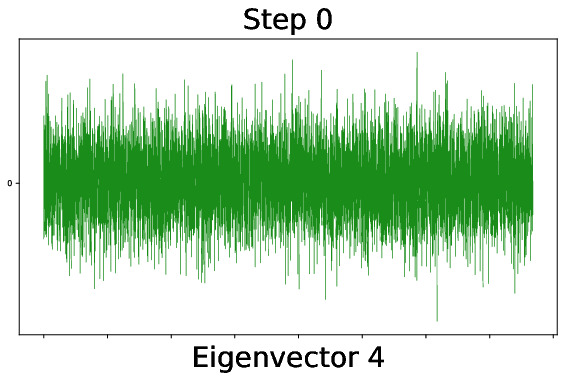
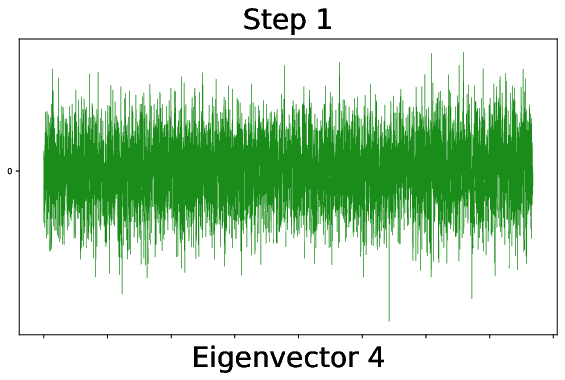
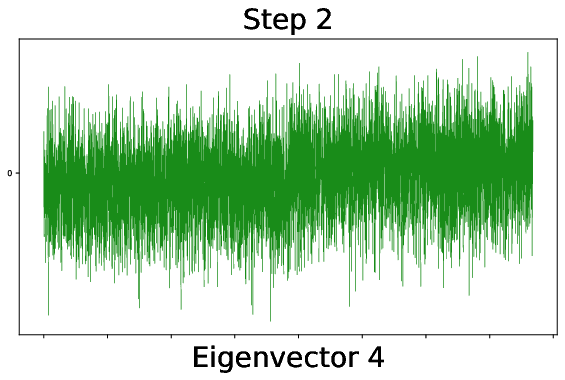
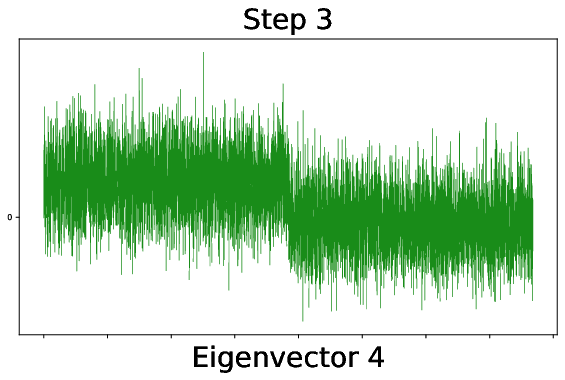
Figure 9: During training, outlier spikes bleed out from the bulk of the weight spectrum, indicating the onset of useful feature learning in finite networks.
Figure 10: Alignment of the fourth leading CK eigenvector to the XOR labels rapidly increases after a critical training threshold, signaling the onset of quadratic feature informativeness.
Implications, Theoretical and Algorithmic Consequences
The reported results definitively clarify when and how nonlinear, nontrivial structure can be amplified and made accessible by kernel methods constructed from random or learned features. The explicit characterization of BBP-like thresholds and quadratic equivalents delineates the regimes in which kernel PCA and linear classifiers in feature space are fundamentally limited, and when feature learning or increasing sample complexity can “unlock” nonlinear learnability.
Practically, the strong sensitivity to activation nonlinearity (as quantified by Hermite coefficients), SNR, weight structure, and sample size scaling, informs both neural architecture design and the interpretation of empirical generalization phenomena in deep learning. The connection to recent work on feature learning, phase transitions, and universality regimes in kernel and random feature models is direct and robust.
Conclusion
This work provides an authoritative RMT analysis of the spectral conditions for nonlinear learnability in kernelized neural architectures, exposing the crucial interplay of data structure, nonlinearity, SNR, weight initialization and feature learning. The quadratic equivalent framework not only accurately predicts the emergence of informative spikes—which correspond to recoverable label structure—but also elucidates the obstacles facing kernel methods on classic nonlinear tasks in high dimensions, quantifies spectral phase transitions, and lays a foundation for principled kernel and architecture selection in deep learning.
Reference: "Eigen-Spike Emergence and Quadratic Equivalents for Conjugate Kernels on Nonlinearly Separable Data" (2605.29669)