- The paper presents a finite-width Bayesian DNN analysis using the Equivalent Wishart Ansatz to capture kernel fluctuations via scalar order parameters.
- The methodology leverages large deviation principles and Wishart random matrices to accurately predict training loss and generalization errors across various architectures.
- Results reveal smooth error accumulation with deeper networks and emergent metastability, highlighting the need for further theoretical refinement.
Kernel Renormalization in Bayesian Deep Neural Networks: The Equivalent Wishart Ansatz in the Proportional Regime
Introduction and Theoretical Motivation
This paper introduces a unifying, statistically grounded low-dimensional framework for analyzing finite-width Bayesian deep neural networks (DNNs) in the proportional regime, where both data sample size P and network width N scale proportionally. The focus is on the simultaneous presence of three critical features: finite width, nonlinear activation functions, and nontrivial network depth, bridging significant gaps left by previous work restricted to "lazy" infinite-width limits or shallow architectures.
The main results are built upon the Equivalent Wishart Ansatz (EWA), which leverages large deviation principles and properties of Wishart random matrix ensembles to approximate the empirical kernel fluctuations layer-wise in nonlinear DNNs. This framework substantially reduces the complexity of the otherwise high-dimensional posterior integration by mapping the stochastic dynamics of empirical kernels into a finite set of scalar order parameters, essentially retaining only the dominant (large deviations) fluctuations relevant for learning in the proportional limit.
Equivalent Wishart Ansatz: From Hierarchical Random Matrices to Low-dimensional Effective Theory
The foundational insight is that, due to the Gaussianity of weight priors, the empirical kernel at each layer—composed as the normalized outer product of post-activations—exhibits fluctuations well-approximated by a Wishart distribution in the proportional regime. Iteratively, this results in the hierarchical propagation of kernel fluctuations, but the critical realization is that for most directions relevant to the Bayesian integral, each contraction with a test vector is approximately χ2-distributed (generalizing to noncentrality for activations with nonzero mean, e.g., ReLU).
Consequently, instead of needing to track L high-dimensional P×P kernel matrices, the main body of macroscopic statistics relevant for learning is encoded in L scalar random variables. The resulting partition function and predictions for observables such as training loss and generalization error are thus reformulated in terms of a renormalized kernel. The new kernel is a data-dependent scaled version of the large-width Neural Network Gaussian Process (NNGP) kernel, where the scale is self-consistently set by these order parameters.
The strong agreement between theory and exact sampling can be seen in learning curves for both training and generalization errors, with the EWA matching empirical Bayesian results across multiple architectures, datasets, and activation functions over a broad range of depth and sample complexity.
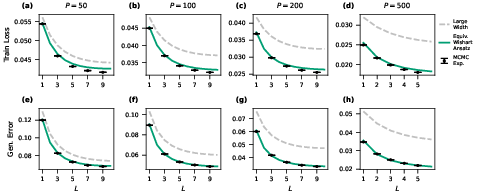
Figure 1: The EWA (green) provides precise predictions for both training loss and generalization error as a function of depth for zero-mean activation functions (Erf) on MNIST, clearly surpassing infinite-width approximations (gray).
Numerical Validation and Large Deviation Principle
A main technical ingredient and point of empirical validation is the large deviation principle (LDP) for the intensive variables qℓ=Qℓ/Nℓ associated with each layer's kernel contraction. Both empirical and theoretical rate functions for these variables are compared in a variety of settings (architectures, datasets, activation functions, scaling ratios), consistently supporting the validity of the EWA across depth and width and showing vanishing deviations as N,P→∞ at fixed α=P/N.
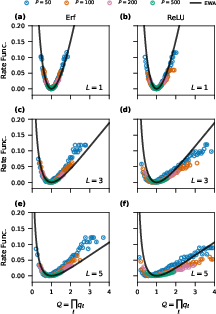
Figure 2: Empirical rate functions for the product random variable Q match the EWA prediction for both ReLU and Erf activations, supporting large deviation principle applicability.
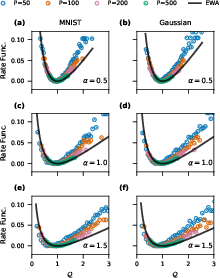
Figure 3: The empirical rate function matches theoretical predictions for various N0 and datasets, confirming the EWA’s universality in the proportional regime.
Extension to Convolutional Architectures and Output Dimensions
The analysis is further extended to multiple output DNNs and deep convolutional networks (CNNs). The kernel renormalization mechanism adapts by introducing hierarchical and spatially local order parameters mapped to patchwise correlations in CNNs. The stacked EWA derivation allows the effective kernel for CNNs to capture more structured, data-dependent renormalizations involving multi-patch order parameters, as opposed to scalar rescaling in fully-connected MLPs.
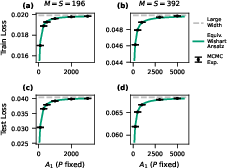
Figure 4: EWA-based kernel renormalization accurately traces the finite-width generalization behavior of shallow CNNs, highlighting the validity of local patch-by-patch renormalization.
The agreement between EWA and numerically exact sampling methods (MCMC/Langevin/Hamiltonian algorithms) is documented for both zero-mean (Erf) and nonzero-mean (ReLU) activations and across datasets (MNIST, CIFAR-10, random Gaussian data), for depth up to N1 and sample sizes N2. EWA accurately predicts both training and generalization error, with deviations from infinite-width (NNGP) theory increasing with layer depth and N3.
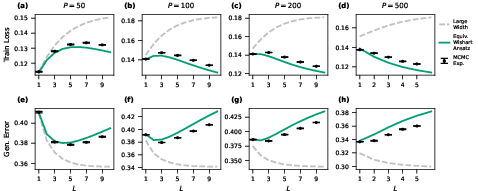
Figure 5: EWA learns curves closely match Bayesian sampling for zero-mean activations on CIFAR-10, even beyond large-width approximations.
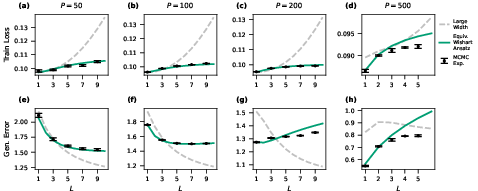
Figure 6: Finite-width effects (here for nonzero-mean activation on Gaussian data) are captured nonperturbatively by the EWA; the NNGP limit fails for increasing depth.
An important observation is the identification of two kinds of systematic deviations appearing for sufficiently large depth (N4) and large load (N5):
- Smooth errors accumulation: A progressive breakdown of EWA accuracy as N6 grows, attributed to cumulative layer-wise approximation errors.
- Metastability and transitions: Abrupt performance improvements linked to an emergent metastable regime, not explained by either large-width NNGP theory or EWA, and robust to choice of sampling algorithm.
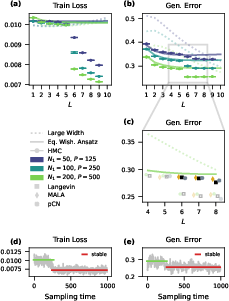
Figure 7: Emergent metastability at large depth and load (N7) is observed in numerical sampling, not accounted for by kernel renormalization theory.
Standard vs. Mean Field Parametrization and Adaptive Kernel Comparisons
By analyzing both standard (SP) and mean-field (N8P) parametrizations, the work demonstrates that, in the proportional regime, improvements in generalization seen in rich learning scenarios are primarily attributed to variance suppression of the predictor, with little change in bias. Crucially, the EWA captures these macroscopic effects without needing high-dimensional vector-valued order parameters or adaptive kernel self-consistency equations, providing a tractable baseline for further adaptive kernel theories.
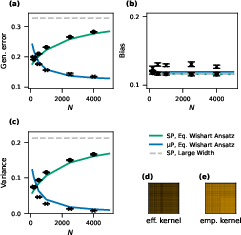
Figure 8: SP and N9P (mean-field) parametrizations display distinct generalization characteristics; EWA captures the effect, showing variance as the main source of improvements in χ20P.
Practical and Theoretical Implications
Practically, the EWA offers a computationally tractable, physically interpretable, and broadly predictive baseline theory for finite-width Bayesian DNN performance in the proportional regime. Theoretically, it represents a significant dimensional reduction from adaptive kernel frameworks constrained by χ21 matrix equations, to χ22 scalar order parameters, while still accounting nonperturbatively for finite-χ23 corrections.
This result suggests that, for many real-world scenarios (large but not infinite χ24, χ25), generalization can be understood largely through this low-dimensional random matrix structure, with more intricate feature adaptation or explicit high-dimensional kernel learning manifesting only outside the proportional regime (e.g., χ26).
Future Directions
Any observed discrepancies in regimes of high depth and load—most notably the abrupt metastable transitions—indicate that further theory refinements and the development of new combinatorial or dynamical phenomena are needed for a complete description. Extensions to other architectures (e.g., max-pooling, transformers), larger datasets, and more intricate forms of feature adaptation remain as rich avenues for exploration, with the EWA as a baseline reference.
Conclusion
The Equivalent Wishart Ansatz forms a rigorously motivated, empirically validated, and computationally efficient core for the analysis of generalization in Bayesian deep (and convolutional) neural networks in the proportional regime. By reducing kernel adaptation to a handful of self-consistent scalar order parameters, it organizes much of finite-width DNN learning into a tractable and predictive statistical framework, and is vital for distinguishing genuinely high-dimensional adaptive feature learning from macroscopic finite-size effects. The theory offers immediate implications for interpreting overparameterized scaling laws in practical AI, provides baseline results against which more complex adaptive kernel theories can be compared, and clarifies the role of scaling, depth, width, and data complexity in modern deep learning.