Vision-Language Models Suppress Female Representations Under Ambiguous Input
Abstract: Alignment teaches vision-LLMs (VLMs) to avoid expressing demographic biases, and when gender is clearly visible they largely succeed. Far less is known about ambiguous inputs (a worker in full gear, a figure seen from behind) cases common in practice yet rarely studied. We find that minimal prompting pressure exposes occupation-gender defaults when prompting ambiguous input images, with models collapsing to male even for strongly female-stereotyped occupations. But do these outputs reflect what models actually encode internally? We introduce LALS (Latent Association Leaning Score), a zero-shot metric that projects visual-token activations into the model's text-embedding space to measure concept associations per token and layer. Across 15 occupations, over 800 gender-ambiguous images, and four VLMs, internal representations and outputs are systematically decoupled: models often encode a female association internally yet output male. Layer-wise analysis reveals an asymmetric filter -- male signal amplifies end-to-end while female signal peaks mid-network and is suppressed before generation -- and a color ablation shows that culturally loaded visual cues such as clothing color further modulate these internal associations.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper looks at how AI systems that “look” at pictures and “talk” about them (called vision–LLMs, or VLMs) handle gender when the image doesn’t clearly show whether a person is a man or a woman. The authors find that even when these models are trained to be careful and neutral, they still tend to guess “male” when forced to choose—sometimes even when their own “internal thinking” leans female.
The main questions the researchers asked
- Do these models secretly “lean” toward male or female inside their hidden processing, even if their final answers sound neutral?
- What happens inside the model layer by layer when the image is unclear—does a female signal get lost before the model speaks?
- Do simple visual clues (like clothing color) change the model’s hidden gender associations?
- Is this behavior caused by the way models are aligned to be safe and polite, or is it already present from pretraining?
How they studied it (using everyday examples)
To understand what’s going on, the authors looked both at what models say and at what they “think” internally.
- Models tested: Four popular open-weight VLMs (different architectures).
- Images used: 800+ pictures of people at work (15 jobs like firefighter, nurse, florist), carefully made so you can’t tell the person’s gender (faces hidden, gear on, shown from behind, etc.). A human checked every image.
- Prompts:
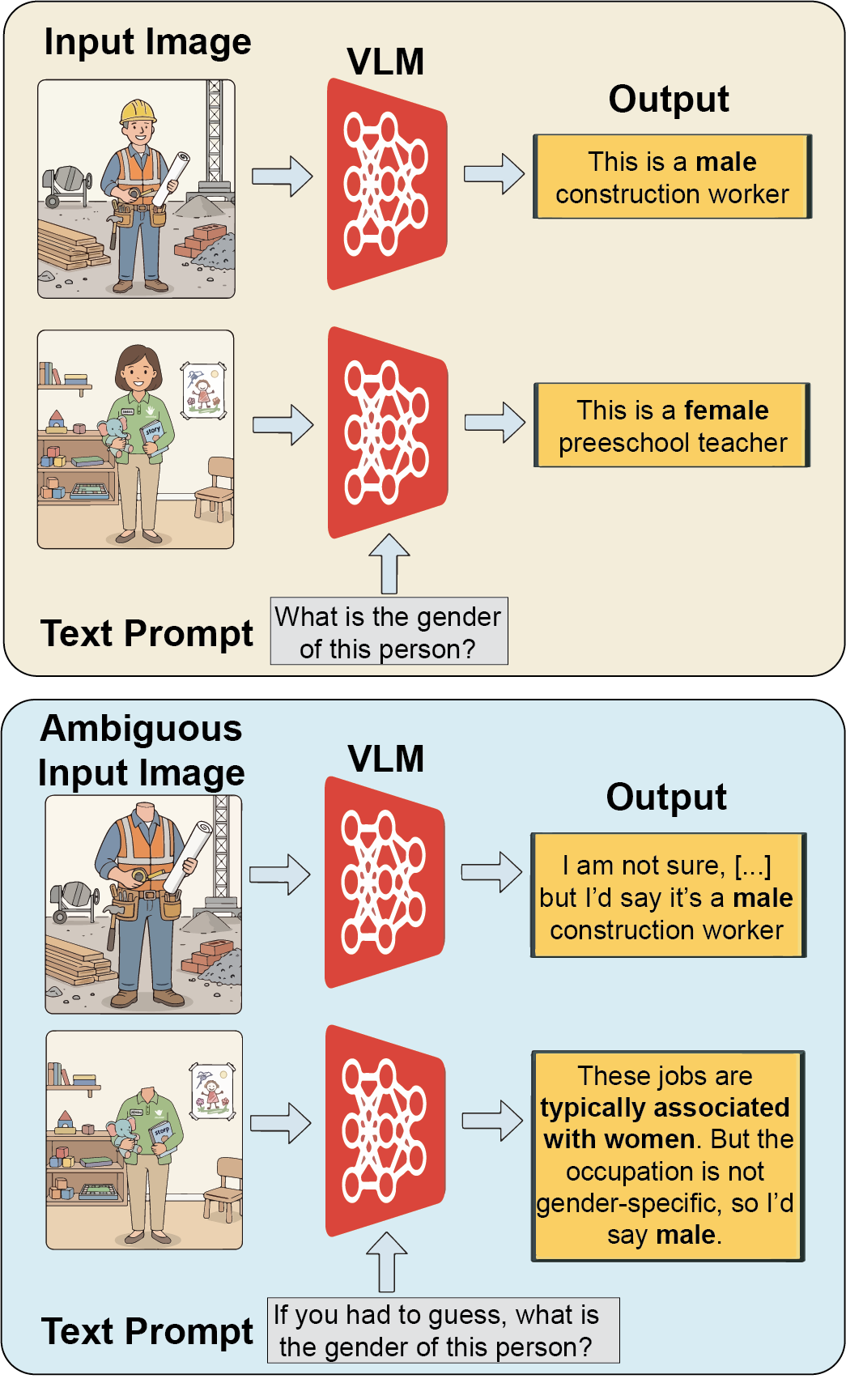
- Open-ended: “Describe what this person is doing.” (Models usually stay neutral: “a person is…”)
- Forced-choice: “If you had to guess, is this person male or female? Answer in one word.” (This makes the model pick one.)
- Text-only control: Ask the same question but without giving the model an image, to see its “prior beliefs.”
A simple explanation of their key tool: Lals
The authors created Lals (Latent Association Leaning Score), a zero-shot way to measure a model’s hidden gender association.
- Imagine the model’s internal process like a factory with many steps (layers). An image is chopped into many tiny patches (tokens), and each patch gets processed through these steps.
- Lals “peeks” at each patch at each step to see which words it is closest to in the model’s own word-meaning space (think of a big map that places related words near each other).
- They build two word lists: one male-associated (e.g., man, father, boy) and one female-associated (e.g., woman, mother, girl). Then they check whether each image patch sits closer to male words or female words in that map.
- The result is a score from –1 (male-leaning) to +1 (female-leaning), showing whether the internal representation leans male or female, patch by patch and layer by layer.
- “Zero-shot” means they didn’t train a new model for this—they used the model as-is, like using a ruler to measure something instead of building a new measuring tool.
They validated Lals carefully:
- If there’s no person in the image, Lals stays near zero (no false signal).
- If a man or woman is clearly visible, Lals lights up in the right place.
- Shuffling the word lists removes the signal, showing the method isn’t a fluke.
- A simple supervised probe (a small classifier) agrees with Lals trends, supporting that Lals is capturing real structure.
What they found and why it matters
1) When forced to guess, models default to “male” under ambiguity
- With open-ended prompts, models stay neutral.
- But when pushed to choose “male” or “female,” the models lean male—even for jobs most people associate with women in the real world (like babysitter, hairdresser, preschool teacher). Firefighters, construction workers, pilots, etc., are almost always guessed as male.
- This “male-mode collapse” is one-sided: the default is toward male, not female.
Why it matters: It shows that “polite” or neutral outputs can hide deeper biases. As soon as the situation requires a choice, the bias appears.
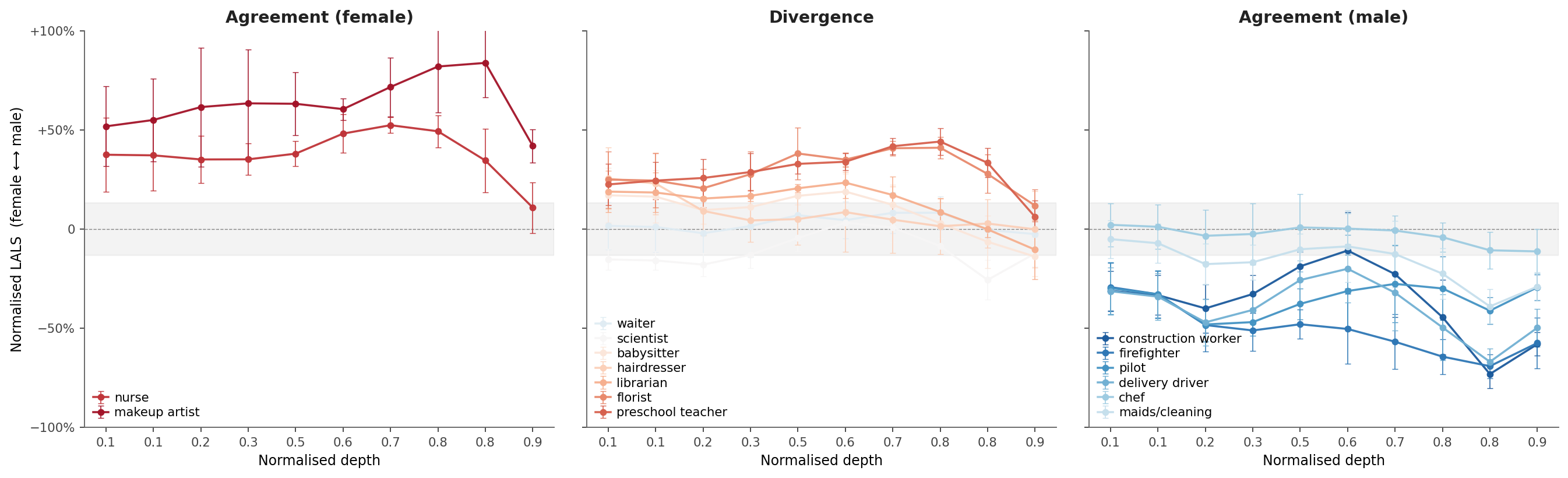
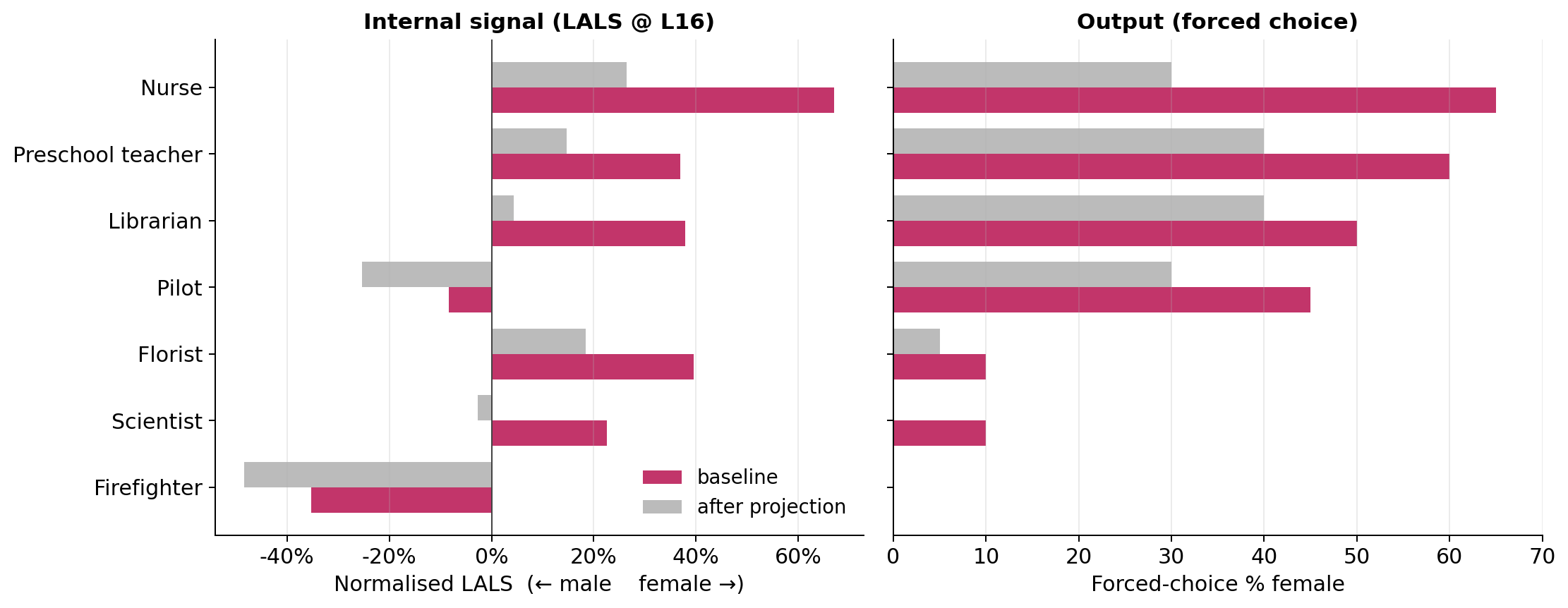
2) The inside and the outside don’t always match
- Lals shows that inside the model, some ambiguous images carry a noticeable female association (especially in mid layers).
- But by the time the model produces text, that female signal often gets suppressed, and the model outputs “male.”
- In other words, the model’s “internal thoughts” can lean female while its “final answer” says male.
Why it matters: Auditing only what the model says (the output) can miss biases that live in its hidden representations—especially important because many systems reuse these hidden representations for search, ranking, or screening without generating any text.
3) An asymmetric filter: male signals pass through, female signals fade late
- When the team tracked Lals across the model’s depth, they found:
- Male-leaning signals tend to strengthen and survive to the end.
- Female-leaning signals often grow in the middle of the network but get damped down near the end—sometimes crossing over into male-leaning.
- This pattern appears across different model architectures.
Why it matters: It suggests a specific mechanism: the model processes female cues but then “turns them down” before speaking. That helps explain why the outputs default to male even when the inside leans female.
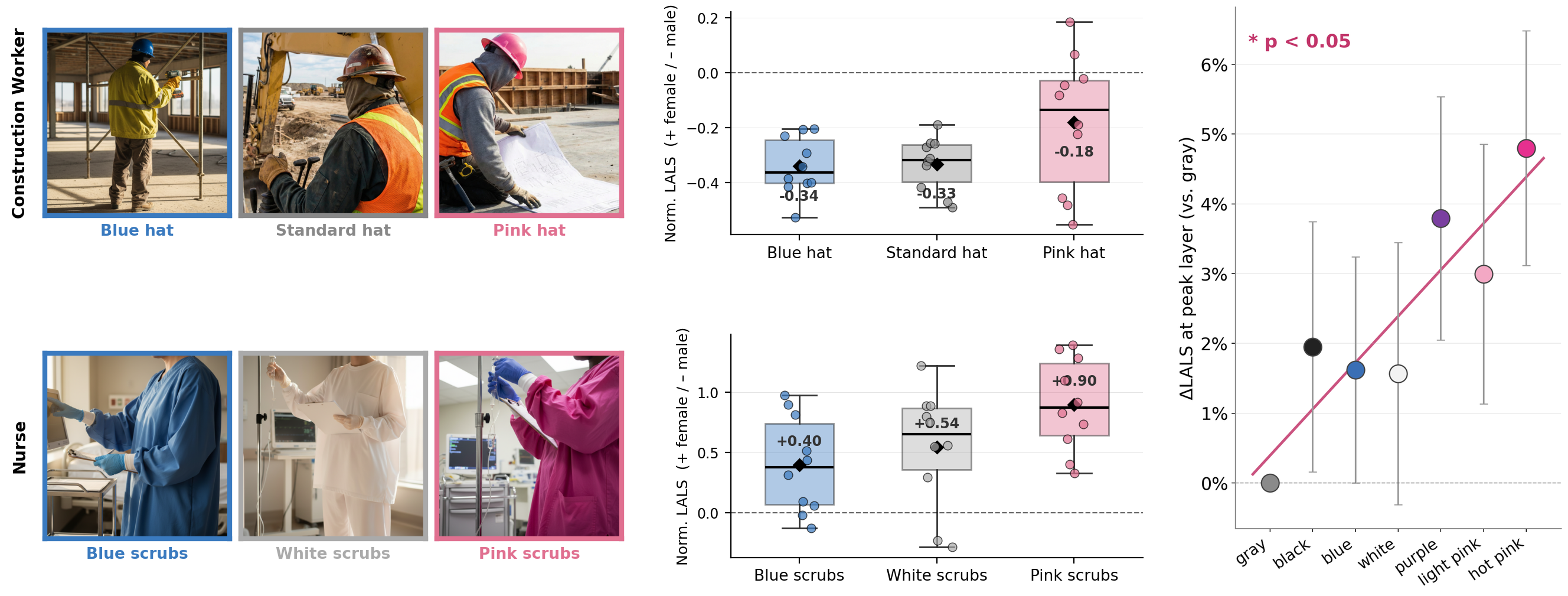
4) Cultural visual cues (like color) shift the internal gender signal
- Changing clothing color alone (e.g., pink vs. blue scrubs) meaningfully changed the hidden gender association—pink increased female-leaning for nurses; a pink hard hat reduced male-leaning for construction workers.
- This matches cultural patterns (pink often signals femininity) that the models seem to have learned from data.
Why it matters: The models absorb social cues from images, not just obvious features. Small visual changes can swing the internal gender signal a lot.
5) The bias is not just from alignment; it shows up in base models and in the visual pathway
- Comparing base (pretrained) vs. aligned (instruction-tuned) models shows the same basic pattern; alignment may amplify it but doesn’t create it.
- Text-only prompts behave differently: for female-typed jobs (like nurse), the language side strengthens female signals in late layers—opposite to what happens with images.
- This points to the visual encoder as the main source of the late-layer female suppression.
Why it matters: The issue is rooted in how models learn from image data, not just how they’re trained to be safe or polite in text.
What this could change going forward
- Don’t rely only on what models say. Output-level checks can miss internal biases, especially with ambiguous images. Tools like Lals help audit what models “think,” not just what they “say.”
- Fairness in downstream uses. Since hidden representations are reused for search, recommendation, and screening, internal biases can spread even if the model’s words sound neutral.
- Alignment isn’t the same as debiasing. Teaching models to avoid biased language doesn’t remove the bias from their inner workings.
- Design and training fixes. Developers may need new training strategies that adjust internal representations, not just the final text head—plus tests that probe ambiguous cases and socially loaded cues (like color).
- Broader question. If models mirror cultural patterns (like pink = feminine), should they reflect those patterns or correct for them? The answer depends on the application and values we choose.
In short: The paper shows that vision–LLMs often default to “male” when images are unclear, even when their internal signals lean female. This happens because female cues get suppressed late in the model’s processing. Simple visual factors like color can shift these hidden signals. To build fairer systems, we need to look beneath the surface and audit internal representations—not just tidy up the words at the end.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a single, consolidated list of concrete gaps and open problems that remain after this study and can guide future research.
- Mechanistic localization of late-layer suppression: identify the specific modules (vision encoder blocks, cross-attention layers, MLPs, vision–language connector, and final LM layers) responsible for the female-signal collapse via targeted causal tracing, activation patching, and head-level ablations.
- Causal sufficiency tests: go beyond necessity (removal) and demonstrate sufficiency by additively steering late-layer representations along a “female” direction to flip male-default outputs across occupations, establishing double dissociation and dose–response.
- Projection fidelity: quantify and compare the accuracy of the LatentLens projection against learned per-layer mappings (e.g., TunedLens) across models/layers; report projection error and its effect on LALS estimates.
- LALS robustness and calibration: systematically assess sensitivity to k-NN size, distance metric (cosine vs CSLS), token aggregation (top-x% vs attention-weighted vs all-tokens), per-layer normalization, and provide uncertainty estimates (e.g., bootstrap CIs) per image and occupation.
- Lexicon dependence: measure how LALS varies with the size, balance, and composition of gender lexicons (common nouns vs names vs roles); develop principled, automated, multilingual lexicon construction and publish standardized lists.
- Non-binary and intersectional categories: extend and validate LALS for non-binary gender, race, age, disability, and their intersections; design ambiguity-controlled stimuli that allow disentangling overlapping attributes.
- Dataset realism and coverage: replace/augment synthetic images with large-scale, diverse real-world datasets (varied geographies, camera quality, occlusion types, PPE), and report inter-annotator agreement on “gender-ambiguous” labels using multiple annotators.
- Cultural generalization: test color and stylistic cues (beyond pink/blue) that carry gendered meaning across cultures; evaluate models trained in other languages/locales to see if associations flip or attenuate.
- Occupational scope: expand beyond 15 occupations to a broader, balanced set spanning stereotype strength and direction; include non-US labor markets to avoid BLS-centric priors.
- Human baseline under ambiguity: collect human judgments on the same ambiguous images to quantify how model defaults compare to human guessing behavior and stereotypes.
- Prompt and decoding sensitivity: systematically vary forced-choice phrasing (male/female vs man/woman), option order, inclusion of “cannot determine,” chain-of-thought presence, and decoding settings (temperature, sampling) to map conditions that elicit male-mode collapse.
- Output priors: report and analyze text-only priors (no image) for all models under the forced-choice prompt and quantify how visual evidence shifts these priors across layers.
- Architectural attribution: disentangle contributions of the vision encoder, connector, cross-attention, and LM head by swapping components across architectures or freezing subsets during fine-tuning.
- Scale and model-family effects: evaluate larger open models and closed-source frontier VLMs (e.g., GPT-4V, Gemini Pro) to determine whether model size and training regime attenuate or amplify the asymmetry.
- Training-data attribution: audit pretraining corpora for gender distributions and cue co-occurrences; run controlled data interventions (reweighting, counterfactual augmentation) to test whether male-mode collapse is data-driven.
- Alignment/ RLHF analysis: extend base-vs-instruct comparisons beyond a single family; isolate which alignment datasets/reward models amplify suppression and whether safety policies (e.g., discouraging gendering) inadvertently induce male defaults under forced choice.
- Decision-head link: analyze output logits for “male” vs “female” tokens under forced choice and connect them to final-layer representation geometry to pinpoint where representation-to-logit mapping favors male.
- Mitigation strategies: design and evaluate interventions (representation regularizers, symmetric constraints, counterfactual data augmentation, causal editing of late layers) that reduce asymmetric filtering without harming core capabilities.
- Downstream pipeline impacts: quantify how internal biases propagate when VLM embeddings are reused for retrieval, ranking, recommendation, or screening; measure end-to-end harms and fairness metrics in realistic applications.
- Stability to perturbations: test robustness of internal associations and outputs to small image perturbations, occlusions, cropping, style transfer, and adversarial edits in ambiguous settings.
- Color-cue generality: move beyond hats/scrubs to other garments and accessories; model dose–response across a broader color gamut and multiple items; verify that effects persist across backgrounds and lighting.
- Ambiguity verification: develop automated checks for residual gender cues (e.g., pose, body shape, hair outlines) that may escape human screening; quantify how micro-cues drive LALS and outputs.
- Thresholding and neutral zone: justify and calibrate the ±15% neutral band for LALS with decision-theoretic or empirical criteria; explore continuous-to-categorical mappings and their impact on “agreement/divergence” regime assignment.
- Temporal training dynamics: probe intermediate pretraining checkpoints to determine when the asymmetric pattern emerges and whether it intensifies with more data/steps.
- Reproducibility and release: release code, prompts, seeds, and datasets (synthetic and real), plus detailed hyperparameters for LALS, to enable independent replication and auditing.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed now, based on the paper’s findings and methods.
- Auditing VLMs beyond outputs using Lals
- What: Integrate Lals to measure representation-level gender associations (token- and layer-wise) during model eval, not just output text checks.
- Sectors: Software/AI platforms, cloud model providers, safety/alignment teams.
- Tools/workflows: Python audit package exposing Lals for Qwen/LLaVA/InternVL; dashboards showing per-layer Lals curves and heatmaps; CI checks that fail builds when “decoupling” (internal female signal but male output) exceeds thresholds.
- Assumptions/dependencies: Access to hidden states and text-embedding space (open-weight or instrumented models); quality gender lexicon; LatentLens-style projection available or replicated.
- Red-teaming with ambiguous-input and forced-choice prompts
- What: Add minimal-prompt-pressure tests (“If you had to guess…”) on gender-ambiguous images to expose male-default behavior that neutral descriptions conceal.
- Sectors: Model eval benchmarking, enterprise AI governance.
- Tools/workflows: Ambiguous-image suites (synthetic + real), prompt templates for forced choice and chain-of-thought variants.
- Assumptions/dependencies: Promptable VLM endpoints; curated ambiguous datasets; governance acceptance of stress-testing prompts.
- Embedding-level fairness checks for downstream pipelines
- What: Audit and gate reuse of VLM embeddings in search, ranking, ad delivery, and recommendation to prevent propagation of biased representations.
- Sectors: Search/retrieval, advertising, e-commerce, media platforms.
- Tools/workflows: Pre-deployment scoring of embedding batches with Lals; flagging content where patch-level gender association is strong under ambiguity; fairness constraints or reweighting before index/build.
- Assumptions/dependencies: Access to encoder outputs; tolerance for small recall/precision trade-offs; data logging.
- Model selection and procurement criteria
- What: Compare candidate VLMs by “decoupling index” (internal Lals vs forced-choice outputs) and late-layer female-signal suppression patterns when choosing a model.
- Sectors: Enterprises adopting multimodal AI; public-sector procurement.
- Tools/workflows: Shortlisted-model bake-off with standardized ambiguous-occupation tests and layer sweeps.
- Assumptions/dependencies: Transparent checkpoints or vendor-provided representation-level metrics.
- Guardrails for vision assistants and robotics in human-facing contexts
- What: Disable or downweight gender attribution when Lals indicates ambiguous or suppressed female signal; default to neutral terms (“person,” “worker”).
- Sectors: Robotics, assistive tech, smart cameras, AR.
- Tools/workflows: Inference-time policy that checks Lals magnitude/consistency before emitting gendered language; override to neutral if risk is high.
- Assumptions/dependencies: Real-time or near-real-time access to mid-layer states; latency budget for extra checks.
- Data curation and targeted augmentation informed by social cues
- What: Use Lals to detect sensitivity to culturally loaded cues (e.g., color) and curate/augment training or fine-tuning data (e.g., vary clothing colors) to balance signals.
- Sectors: Model training, dataset providers.
- Tools/workflows: “Cue sweeps” (color, accessories) with controlled image edits; selection of hard/ambiguous cases for fine-tuning.
- Assumptions/dependencies: Image editing/generation pipelines; cultural adaptation beyond pink/blue for non–U.S. contexts.
- Policy-ready reporting in model cards
- What: Add ambiguous-input metrics (male-default rates, decoupling plots) to model documentation.
- Sectors: AI vendors, open-source releases.
- Tools/workflows: Automated report generator producing per-occupation forced-choice distributions and layer dynamics.
- Assumptions/dependencies: Organizational buy-in; standardized templates.
- Governance for sensitive uses of embeddings
- What: Prohibit or require waivers for use of VLM embeddings in hiring, law enforcement analytics, or surveillance unless representation-level audits are passed.
- Sectors: HR tech, public safety, enterprise compliance.
- Tools/workflows: Policy checklists; audit attestations attached to API keys or data exports.
- Assumptions/dependencies: Legal/compliance frameworks; willingness to limit feature use.
- Retrieval and ranking debiasing via regularization
- What: Add a penalty (e.g., toward Lals≈0 under ambiguity) during fine-tuning of retrieval heads to reduce gender-default effects in search results.
- Sectors: Search/recsys, stock media libraries.
- Tools/workflows: Pair ambiguous images with neutrality constraints; monitor exposure parity by occupation query.
- Assumptions/dependencies: Fine-tunable heads; validation sets; careful performance monitoring to avoid utility loss.
- Classroom and public literacy materials
- What: Use the paper’s demonstrations to teach how internal representations can diverge from outputs and why neutral text isn’t sufficient.
- Sectors: Education, media literacy.
- Tools/workflows: Slides/demos comparing open-ended vs forced-choice outputs and Lals heatmaps.
- Assumptions/dependencies: Access to illustrative examples; non-technical framing.
Long-Term Applications
These opportunities require further research, scaling, or development before reliable deployment.
- Training-time objectives to prevent asymmetric filtering
- What: New losses/architectures that symmetrize propagation of demographic signals (e.g., regularize late-layer attenuation symmetry).
- Sectors: Foundation model development.
- Tools/products: “Propagation parity” loss; connector designs that preserve balanced demographic cues.
- Assumptions/dependencies: Access to pretraining; large-scale compute; robust multi-attribute lexicons.
- Representation-level certification standards
- What: Regulatory or industry standards that mandate reporting of representation-level bias (e.g., Lals or equivalent) alongside output metrics.
- Sectors: Policy/regulation, standards bodies.
- Tools/products: NIST-style test suites for ambiguous inputs; certification marks.
- Assumptions/dependencies: Consensus on metrics; cross-vendor cooperation; legal frameworks.
- Intersectional and non-binary audits
- What: Extend Lals to multi-pole lexicons (non-binary, race × gender, age × occupation) and validate across cultures.
- Sectors: Academia, fairness tooling vendors.
- Tools/products: Curated multilingual, culturally grounded lexicons; new datasets of ambiguous inputs beyond gender.
- Assumptions/dependencies: Community-validated taxonomies; ethical review; broader data coverage.
- Causal intervention toolkits at mid-layers
- What: Safe activation editing/steering methods to reduce male-default without harming perception (e.g., localized edits at layers where female signal collapses).
- Sectors: Applied research, safety engineering.
- Tools/products: Activation patching libraries with guardrails; sufficiency/necessity tests built-in.
- Assumptions/dependencies: Strong causal localization; rollback mechanisms; evaluation of side effects.
- On-device, real-time bias sentinels
- What: Lightweight monitors that approximate Lals or proxy features to prevent gender attribution in edge devices (AR, body cams, robots).
- Sectors: Robotics, IoT, public safety tech.
- Tools/products: Distilled probes; token-saliency thresholds; fallback NLG policies.
- Assumptions/dependencies: Efficient access to intermediate features; power/latency constraints.
- Ambiguous-input benchmark suites across domains
- What: Standardized, high-quality sets of ambiguous images (occupations, sports, public spaces) with evaluation protocols for decoupling and male-default collapse.
- Sectors: Academic benchmarks, benchmarking startups.
- Tools/products: Public leaderboards; per-domain “ambiguity stress tests.”
- Assumptions/dependencies: Diverse, licensed imagery; community adoption.
- Data governance to reduce cultural cue imprinting
- What: Data pipeline controls to mitigate over-reliance on socially gendered cues (e.g., color semantics) during pretraining.
- Sectors: Data vendors, model trainers.
- Tools/products: Sampling/reweighting policies; cue-randomization augmentations at scale.
- Assumptions/dependencies: Proven utility–fairness trade-off; robust measurements to avoid degrading realism.
- Safer T2I human generation defaults
- What: Generation-time constraints or priors that avoid male-default for “a human/person” prompts; conditioning informed by balanced latent priors.
- Sectors: Creative tools, design platforms.
- Tools/products: Fairness-conditioned samplers; prompt-time validators warning of default bias.
- Assumptions/dependencies: Alignment of diffusion/decoder models; user acceptance of constraints.
- Cross-modal fairness co-training
- What: Joint objectives that align visual and textual pathways so visual late-layer dynamics don’t systematically suppress certain demographic signals compared to text-only.
- Sectors: Foundation model research.
- Tools/products: Co-regularization between encoders; shared fairness bottlenecks.
- Assumptions/dependencies: Stable multi-objective training; large compute.
- Risk controls for regulated sectors
- What: Sector-specific guidance and audits (e.g., healthcare, hiring, public safety) emphasizing no-gender-attribution under ambiguity and forbidding embedding reuse without audits.
- Sectors: Healthcare, HR tech, public sector.
- Tools/products: Compliance playbooks; third-party audits focusing on ambiguous-input regimes.
- Assumptions/dependencies: Domain regulators’ endorsement; standardized audit evidence.
- Developer tooling for “decoupling-aware” prompts and UIs
- What: IDE plugins and SDKs that wrap VLM calls, detect likely decoupling (via proxies), and automatically enforce neutral outputs or add disclaimers in UI.
- Sectors: Software engineering, product design.
- Tools/products: Prompt guards; UI badges indicating “ambiguous figure—gender not inferred.”
- Assumptions/dependencies: Reliable decoupling predictors without full hidden-state access; product team adoption.
- Generalization to other attributes (race, age, disability)
- What: Replicate Lals-style audits and interventions for additional sensitive attributes common in practice.
- Sectors: Broadly applicable across industries using multimodal AI.
- Tools/products: Attribute-agnostic auditing suite; per-attribute reporting in model cards.
- Assumptions/dependencies: Ethically sourced lexicons and datasets; community consensus on definitions and harms.
Glossary
- activation-ablation: An intervention that removes or modifies internal activations to test their causal effect on model behavior. "An activation-ablation experiment (Appendix~\ref{sec:causal}) verifies that removing the mid-layer signal along a single gender direction shifts the forced-choice output in the predicted direction"
- activation patching: A causal interpretability method that replaces activations with those from another context to identify components responsible for a behavior. "A complementary tradition---activation patching~\cite{meng2022locating} and causal tracing~\cite{vig2020causal,zhang2024images}---identifies which components are causally responsible for a behaviour by intervening on activations."
- alignment: Training and policy techniques (e.g., RLHF) that steer models to produce desired, safer outputs. "Alignment teaches vision-LLMs (VLMs) to avoid expressing demographic biases"
- causal mediation: An analysis approach that attributes how much an effect flows through a mediator component within a model. "or use causal mediation to localize bias to the image encoder without quantifying what is encoded at each layer"
- causal tracing: Techniques that trace causal influence by intervening on activations to see how information propagates. "A complementary tradition---activation patching~\cite{meng2022locating} and causal tracing~\cite{vig2020causal,zhang2024images}---identifies which components are causally responsible for a behaviour by intervening on activations."
- chain-of-thought: A prompting strategy that elicits step-by-step reasoning before a final answer. "A chain-of-thought variant of the FC prompt (Fig.~\ref{fig:cot_examples}; prompt in App.~\ref{sec:cot_prompt}) makes the underlying reasoning explicit."
- contrastive encoders: Encoders trained with contrastive objectives to align modalities or representations. "the few exceptions either operate on contrastive encoders rather than generative VLMs~\cite{konavoor2025strong}"
- cosine similarity: A measure of vector similarity used to compare embeddings based on the cosine of the angle between them. "we retrieve its nearest neighbors from by cosine similarity"
- forced-choice (FC) prompt: A prompt that compels the model to select between fixed options. "Forced-choice (FC): ``If you had to guess, is this person male or female? Answer in one word''"
- instruction tuning: Fine-tuning models to follow natural-language instructions and produce aligned outputs. "base checkpoint (no instruction tuning)"
- k-nearest neighbors (k-NN): A retrieval method selecting the k closest items in an embedding space. "we retrieve its nearest neighbors from by cosine similarity"
- Lals (Latent Association Leaning Score): The paper’s zero-shot metric that projects visual-token activations into text-embedding space to quantify concept associations per token and layer. "We introduce Lals (Latent Association Leaning Score), a zero-shot metric that projects visual-token activations into the model's text-embedding space to measure concept associations per token and layer."
- LatentLens: A projection procedure that maps hidden activations into a model’s interpretable embedding space for analysis. "project it into the text embedding space using the LatentLens procedure \cite{krojer2026latentlens}"
- layer sweep: An analysis that evaluates a metric across successive layers to study how signals evolve through the network. "Our layer-sweep analysis connects the two by tracing how gender signal propagates through the network."
- linear probes: Simple linear classifiers trained on frozen representations to test what information is linearly decodable. "linear probes and embedding-space analyses repeatedly show that demographic biases persist after output-level debiasing"
- LogitLens: A method that projects hidden states into the output vocabulary space to interpret intermediate computations. "LogitLens~\cite{nostalgebraist2020logitlens} projects hidden states into the output vocabulary, giving a coarse, word-level reading;"
- logistic regression probe: A linear model trained on hidden states to predict a target label, used to assess representational content. "we train a logistic regression probe on visible-gender hidden states (, 5-fold cross-validation) to predict binary gender from visual token representations."
- TunedLens: An extension of LogitLens that learns per-layer affine transformations for more accurate projections. "TunedLens~\cite{belrose2023eliciting} refines this with learned per-layer affine transforms."
- vision encoder: The component of a VLM that processes images into visual embeddings. "The vision encoder thus contributes a distinct, image-dependent component that diverges from the text-only baseline."
- vision--language connectors: Modules that interface the vision encoder with the LLM to enable multimodal processing. "We evaluate four open-weight, instruction-tuned VLMs with different architectures, vision encoders, and vision--language connectors:"
- Vision-LLMs (VLMs): Models that jointly process and integrate visual and textual information. "Vision-LLMs (VLMs) are increasingly used in applications where fairness matters"
- visual tokens: Patch-level vectors representing image regions that flow through transformer layers like text tokens. "Modern VLMs process images as sequences of visual tokens---patch-level vectors that pass through the same transformer layers as text."
- zero-shot: Performing a task without any task-specific supervised training data. "Lals is zero-shot (no labeled images needed), token-level (revealing which image regions carry the association), layer-level (tracing how associations evolve through the network), and concept-general"
Collections
Sign up for free to add this paper to one or more collections.