q0: Primitives for Hyper-Epoch Pretraining
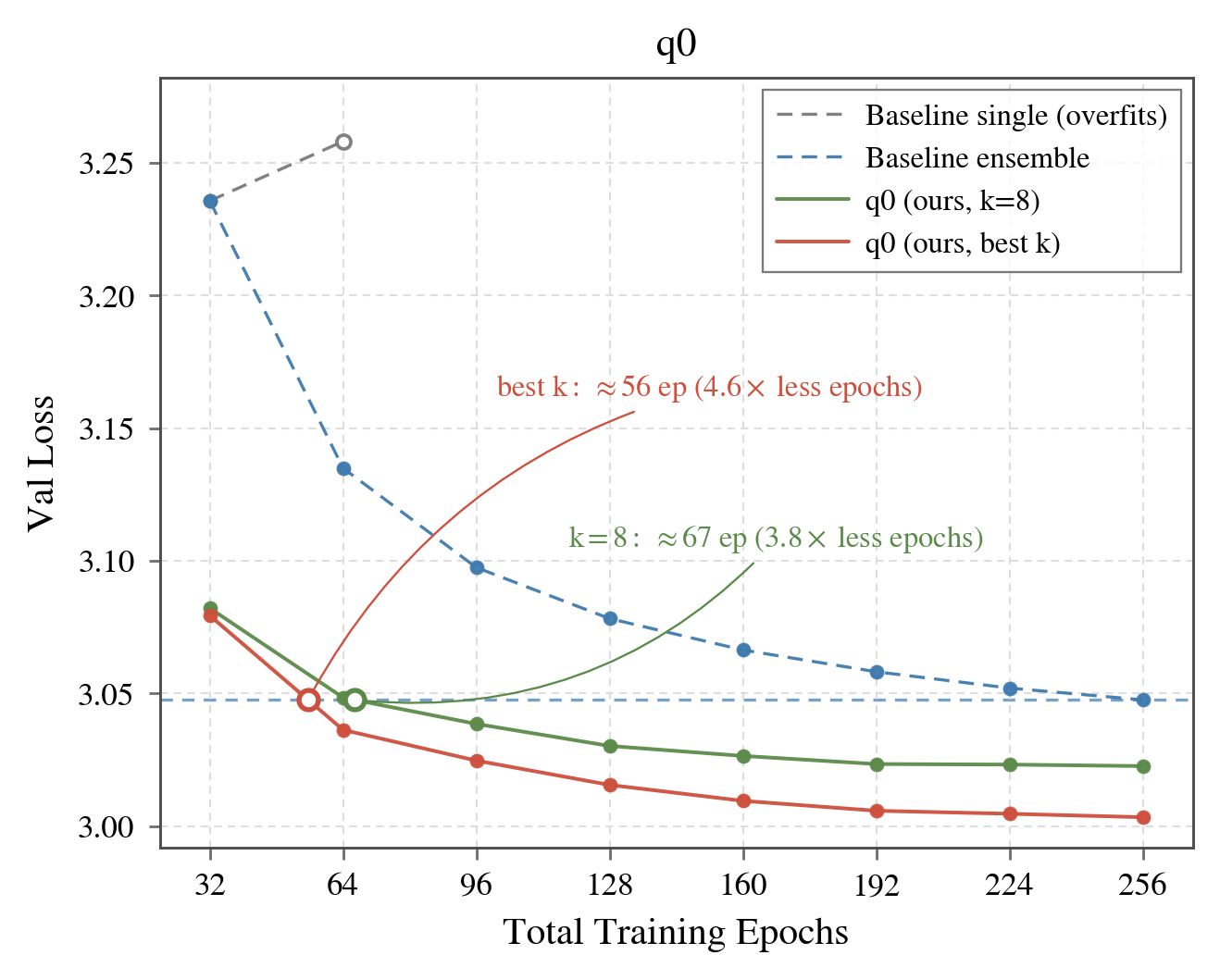
Abstract: Multi-epoch training is becoming the standard now that compute is growing faster than the supply of high-quality text. But pretraining a single model saturates within a few passes, long before the compute budget is exhausted. We argue this calls for a conceptual shift from training a single model toward exploring a population of models and aggregating their predictions. We introduce hyper-epoch pretraining (q0), which turns a multi-epoch budget into a population of diverse models whose combined predictions reach a lower validation loss than a single refined model. q0 reduces to three core primitives. A cyclic schedule with anti-correlated learning rate and weight decay collects diverse models from a few parallel trajectories. Chain distillation trains each model against its predecessor so that model quality compounds across the population. A learned prior, fit on a held out set, selects and weights members for any inference budget. On a 1.8B-parameter model trained on 100M FineWeb tokens, q0 matches a strong 256-epoch ensemble baseline using only ~56 epochs (~4.6x fewer), or ~67 epochs (~3.8x fewer) when matched to the baseline's ensemble size, and continues to improve beyond it. These gains reach cumulative ~12.9x data efficiency under the Slowrun setting and transfer to downstream benchmarks. Crucially, the optimal allocation shifts with the budget, so we give prescriptive recipes for how to spend a given epoch budget to maximize generalization, from a single epoch up to the largest budgets.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple question: if you have lots of computer power but only a limited amount of good text to learn from, what’s the smartest way to train a LLM? The authors suggest a shift in mindset: instead of spending many repeated passes (epochs) polishing one model on the same data, use that time to create a “team” of slightly different models and combine their answers. They call this approach hyper-epoch pretraining (q0).
What questions does the paper try to answer?
- How should we use extra compute when the dataset is fixed and good new data is scarce?
- Can we turn a long multi-epoch budget (many passes over the same data) into a diverse set of models that, together, perform better than any single model?
- What simple building blocks (“primitives”) make that efficient and effective?
How did they do it? (Methods explained simply)
Think of training like practicing for a test using the same study guide over and over. After a few passes, you stop improving much. Instead of only drilling one student (one model), the authors propose training a group of students who study slightly differently and then vote together at test time. They use three main ideas:
- The “snapshot cycles” idea: Training happens in short cycles. At the end of each cycle, they save a “snapshot” of the model. Then they reset the “learning rate” (how big the model’s steps are when it learns) to a high value so it explores new solutions again, and lower it to settle into a good place before saving the next snapshot. They also set “weight decay” (a gentle pull that keeps the model’s numbers from getting too large) to be high when the learning rate is low, and low when the learning rate is high. Analogy: Imagine hiking in hills. Sometimes you take big, bold steps to explore (high learning rate, low pull-back), and then you slow down to carefully settle into a cozy valley (low learning rate, stronger pull-back). Each time you settle, you take a photo (snapshot). You repeat this a few times, ending up with several good but different “views” (models).
- Chain distillation (teacher–student within a run): After a warmup, each new snapshot learns not just from the true answers, but also from the previous snapshot’s full “confidence distribution” over answers. Analogy: A slightly older student tutors the next student. The tutor doesn’t just say what’s right; they share how confident they are in all options. That extra signal helps the next student learn patterns the labels alone don’t show (like which wrong answers are “close”). This makes each new snapshot a bit sharper than the last.
- A learned way to pick and weight the team at the end: At inference (when answering questions), using every snapshot costs time. So they learn which snapshots to keep and how much to trust each one using a small held-out “fitness” set from the same data. Analogy: A coach watches the team practice on a mini-test and then decides which players to put on the field and how much to rely on each, not just picking the individually “best-looking” players but the ones who play well together.
In short:
- Snapshot cycles quickly create many good, different checkpoints without training each model from scratch.
- Chain distillation makes each checkpoint better than the previous one.
- Learned weighting picks a smart subset and how to average their predictions for any time budget you have at inference.
Key terms in everyday language:
- Epoch: one full pass through the training data.
- Learning rate: how big the model’s learning steps are.
- Weight decay: a gentle rule that nudges the model’s numbers to stay small and stable.
- Distillation: letting a “teacher” model guide a “student” model, including how confident it is about all choices.
- Ensemble: combining multiple models’ predictions, like taking a vote or a weighted average.
What did they find, and why is it important?
Here are the headline results, explained simply:
- Faster and better with fewer training passes: Their method (q0) beat a strong baseline that trained 8 separate models for a total of 256 epochs. q0 matched that baseline using only about 56 epochs when it was allowed to choose the best subset and weights, and about 67 epochs when limited to using 8 models—around 4 to 5 times fewer epochs. With the full 256 epochs, q0 ended even lower (better) on validation loss.
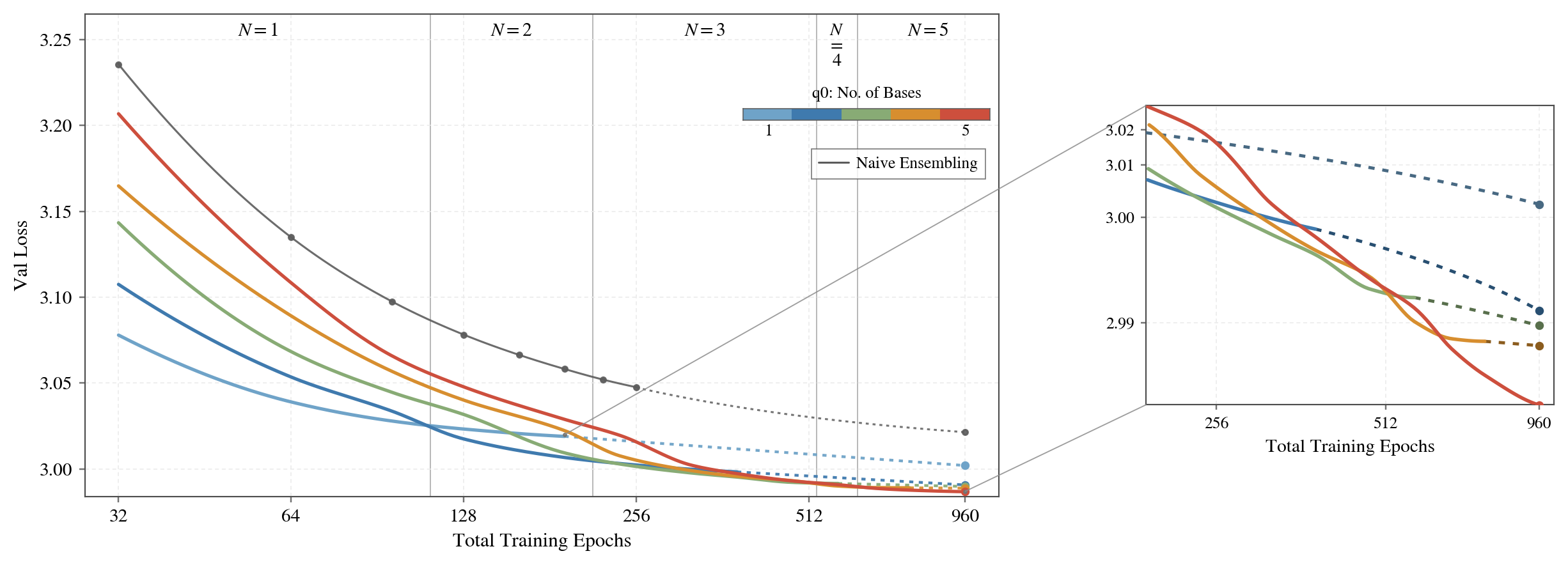
- Works across many budgets: Whether you can afford just 1 epoch or up to 960, q0 consistently does better. They also give practical recipes: with small training budgets, use one base model with many short cycles; as your budget grows, start more parallel base models (different random starts) to add diversity.
- Transfers to real tasks: Improvements on the training distribution carried over to standard benchmarks like ARC-Easy, PIQA, and SciQ. In a data-efficiency setting (called “Slowrun”), q0 reached up to about 12.9× data efficiency.
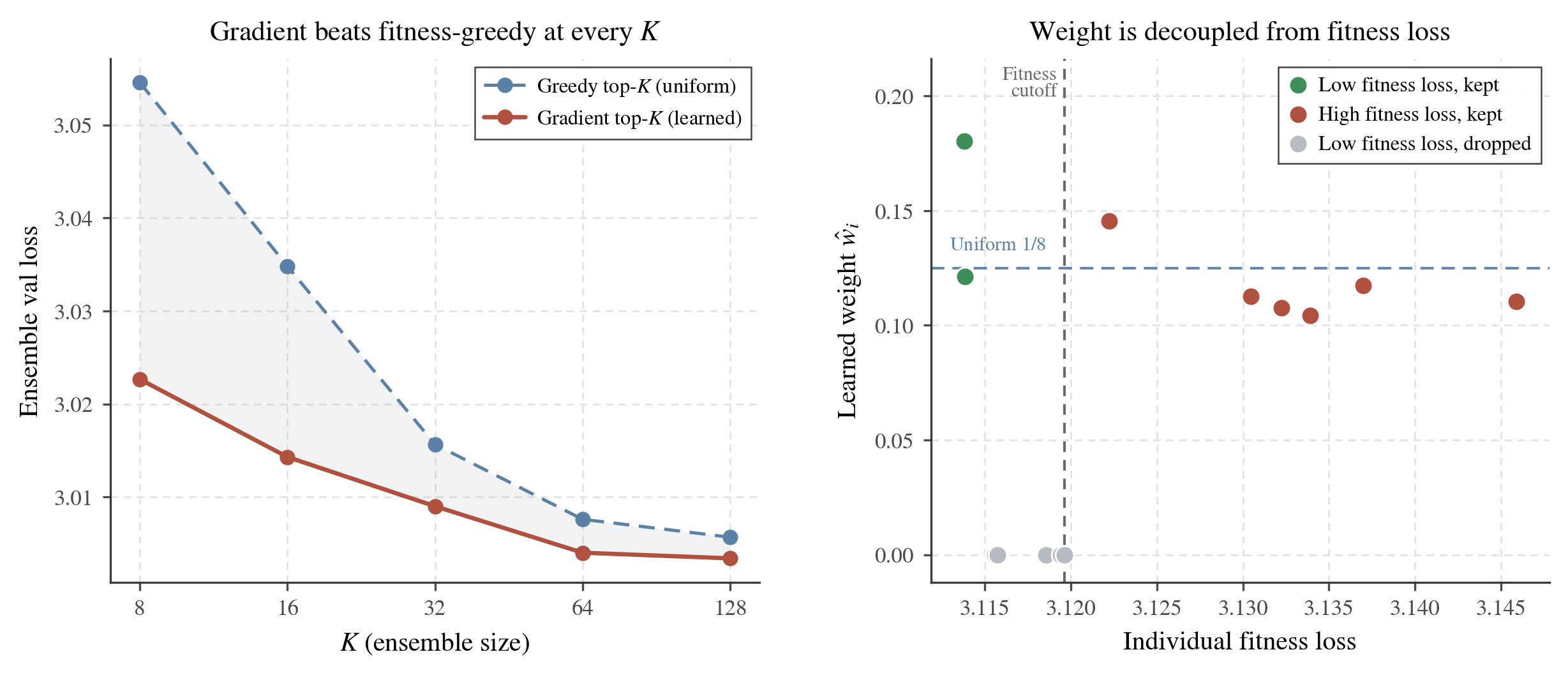
- Smart picking beats “just average the best”: Their learned weighting often selects some snapshots that aren’t the single best alone, but that complement others when combined. This especially helps when you can only afford to combine a few models at inference.
Why it matters:
- When high-quality text is limited, you can’t just keep scaling data forever. q0 shows you can still get big wins by rethinking how you spend compute—explore, save, tutor, and combine—rather than over-polishing one model.
What does this mean going forward? (Implications)
- For training strategy: If you’re stuck with a fixed dataset, don’t pour all compute into one model after it plateaus. Use it to collect a family of models via cycles, make each one better with chain distillation, and then combine them smartly. This turns “extra epochs” into extra diversity and quality.
- For practical deployment: Combining multiple models costs more at inference (you run several models instead of one). But you can get most of the gain with just a few snapshots. Later, you can “distill” the ensemble back into a single model to keep the speed while preserving much of the accuracy boost.
- For research: The paper provides simple, prescriptive recipes for different training budgets and suggests that searching over a population of models—rather than perfecting one—can unlock more progress in data-limited settings. It invites more work on efficient ways to create, improve, and select diverse models.
In one sentence: When data is limited but compute is plentiful, q0’s three-part recipe—cycled snapshots, chain distillation, and learned weighting—turns many passes over the same data into a strong, well-coordinated team of models that outperforms a single over-trained model.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- External validity across data scales and domains: Results are limited to a 1.8B-parameter decoder on 100M FineWeb tokens. It remains unknown how q0 scales with:
- Larger/smaller datasets and different data qualities (e.g., multilingual, code, noisy corpora).
- Larger or smaller model sizes and different architectures (e.g., encoders, multimodal models).
- Fair compute accounting and wall-clock efficiency: Comparisons are reported in “epochs,” not end-to-end FLOPs or wall-clock time including teacher passes, snapshot caching, and fitness-set optimization. Quantifying real training and inference cost parity is missing.
- Robustness to distribution shift: The learned prior is fit on a held-out split from the same distribution. It is unclear how:
- Snapshot selection/weights generalize to OOD test sets and tasks.
- Global, static weights perform under domain shift versus adaptive or per-input weighting.
- Depth of baseline comparisons: No head-to-head against established cheap-ensemble alternatives with matched compute (e.g., FGE, Snapshot Ensembles with standard schedules, SWA/model soups, MC dropout, Laplace approximations, low-rank adapters as ensemble members). The incremental value of each q0 primitive versus these baselines remains unquantified.
- Diversity characterization: The paper asserts diversity from cyclic schedules and parallel trajectories but does not quantify:
- Error correlation, representation similarity, or mode connectivity across snapshots/trajectories.
- How chain distillation alters diversity-quality trade-offs over time.
- Cyclic LR/WD design ablations: The anti-correlation of learning rate and weight decay is motivated but not systematically ablated against:
- Constant WD, in-phase LR–WD cycling, different amplitudes/frequencies, and optimizer-state resets per cycle.
- Alternative restart schemes (e.g., momentum resets, partial state resets).
- Chain distillation hyperparameters and mechanisms: Limited analysis of the distillation term leaves open:
- Sensitivity to temperature T, mixing weight α, and warmup c_start.
- Value of multi-teacher or cross-trajectory teachers versus single predecessor within-trajectory.
- Whether periodic or lagged teachers (e.g., EMA of several snapshots) are better than the immediate predecessor.
- Learned prior overfitting and data requirements: The fitness set size/composition and re-use policy are under-specified. Open issues:
- How large the fitness set must be to avoid overfitting member weights.
- Whether re-fitting per domain/task or cross-validation improves robustness.
- Regularization (e.g., L1/entropy) for sparsity and stability of weights.
- Per-input or task-conditional weighting: The prior uses one global weight vector. Unexplored:
- Input-conditional gating (stacked generalization with features) or task-conditional weights.
- Mixture-of-experts style routing versus static top-K.
- Truncation suboptimality at budget K: The paper trims the globally learned weights to top-K for any K. It remains unknown if:
- Re-optimizing weights per K or performing subset selection (e.g., greedy forward selection) yields better performance at small K.
- Allowing negative or unconstrained linear weights (with calibration safeguards) helps.
- Calibration and uncertainty: No evaluation of calibration (ECE, Brier score), selective prediction, or uncertainty quality. Whether q0 ensembles (and the learned prior) improve calibration over baselines is unknown.
- Distillation of the ensemble to a single student: Proposed as future work but not attempted. Open questions:
- How much of the q0 gain survives ensemble-to-student distillation.
- Whether single-student distillation preserves OOD robustness, calibration, and small-K advantages.
- Memory/IO and scalability of snapshot caching: Fitness-set probability caching scales with M and |F|. The memory, IO, and latency costs for larger M/K, larger models, or longer sequences are not quantified.
- Compute allocation theory: The “staircase” rule-of-thumb for optimal N lacks a theoretical model and broad empirical validation. Open:
- Predictive theory for regime transitions as a function of model/data scale, optimizer, and regularization.
- Whether the staircase persists under different corpora and architectures.
- Small-budget regime generality: End-of-training snapshotting helps at E ≤ 4 in this setup, but the approach is not systematically tested across seeds, datasets, and models to establish robustness.
- Interaction with heavy regularization: The baseline and q0 rely on heavy regularization; it is unclear:
- How the cyclic WD schedule interacts with AdamW’s decoupled decay.
- Whether different regularization recipes (dropout rates, data augmentation) change the gains or optimal schedules.
- Mode connectivity and basin analysis: The claim that cycles exit minima and explore new basins is not validated via:
- Linear mode connectivity or low-loss path analyses between snapshots.
- Hessian-based or sharpness measures to confirm “low-norm basins.”
- Snapshot frequency and cycle length: τ=2 epochs/cycle is fixed by observation; no exploration of:
- Adaptive cycle length based on convergence signals.
- Nonuniform snapshot placements within cycles (beyond end-of-cycle).
- Interaction with synthetic data: Since data is constrained, an important open question is how q0 interacts with synthetic augmentation, self-generated corpora, or DPO/RLHF-pretrained stages.
- Downstream breadth and evaluation depth: Only three small benchmarks (zero-shot) are reported. Missing:
- Few-shot, CoT, long-context, and reasoning tasks.
- Task-specific finetuning transfer, and instruction-following performance.
- Statistical confidence and variance: Val-loss curves and downstream scores lack confidence intervals and multiple seeds. The significance and run-to-run variance of reported gains remain uncertain.
- Safety and failure modes of self-training: While the paper cites evidence against recursive collapse, it does not:
- Empirically probe failure modes (e.g., confirmation bias, collapse under long chains, degraded rare-token performance).
- Analyze token-frequency strata or tail performance under chain distillation.
- Dynamic teacher refresh and caching: Authors hypothesize caching teacher predictions across cycles with slower refresh; not tested. The accuracy–efficiency trade-off remains open.
- Practical deployment constraints: There is no study of:
- Throughput and latency under multi-snapshot inference in real systems.
- Early-exit or anytime inference strategies to bound cost per token adaptively.
- Alternative objectives and modalities: Generality of q0 to masked LMs, sequence-to-sequence tasks, speech/vision models, or multi-task pretraining remains unexplored.
Practical Applications
Immediate Applications
The paper proposes “q0: Hyper-epoch pretraining,” a practical recipe for training on fixed datasets by creating a population of models via cyclic snapshotting, chain distillation, and a learned ensemble prior. The following use cases can be deployed with current tooling (e.g., PyTorch/DeepSpeed/Hugging Face, common LR/WD schedulers, standard distillation losses, and lightweight meta-optimization for the learned prior on a held-out fitness set):
- Enterprise/domain LLM continued pretraining on limited proprietary corpora
- Sector: Software, healthcare, finance, legal, customer support
- What to do: Replace repeated-epoch fine-tuning of a single model on a small corpus with q0: run N parallel trajectories, C short cycles per trajectory with anti-correlated LR/WD, chain-distill within each trajectory after warmup, and learn a top-K ensemble prior on a held-out fitness set.
- Tools/workflows:
- Training: Add cyclic LR with WD anti-correlated to LR; snapshot at cycle ends; enable within-trajectory chain distillation (KL loss with temperature T and weight α) after c_start cycles; cache teacher logits per cycle for efficiency.
- Inference: Use learned softmax weights over snapshots; truncate to top-K for a given latency budget; optionally distill the ensemble to a single model for production.
- Assumptions/dependencies: Data is fixed and representative; a small fitness set is available and not used in training; acceptable (or bounded) inference cost for K>1 forward passes; storage for snapshots/logits.
- Faster, cheaper model refreshes with fixed corpora
- Sector: Any enterprise AI; public sector with restricted data
- What to do: Use q0 to reach target validation loss/accuracy with 3.8–4.6× fewer epochs versus strong ensemble baselines, reducing training time and cloud costs for routine model updates on the same data.
- Tools/workflows: Integrate q0 into CI/CD for ML to accelerate “nightly” continued-pretraining jobs; adopt the paper’s small-budget recipes (e.g., end-of-training snapshots when E≤4).
- Assumptions/dependencies: Same architecture/hyperparameters can benefit from cyclic snapshotting; scheduler overhead is amortized over multiple cycles.
- Better-calibrated predictions via small-K weighted ensembles
- Sector: Healthcare NLP (clinical note summarization), finance (risk tagging), customer support (intent classification)
- What to do: At inference, combine a small number of snapshots (e.g., K=4–8) with learned weights to improve accuracy and robustness on in-distribution tasks without retraining.
- Tools/workflows: Cache and serve K checkpoints; add a “router” that selects top-K and normalizes learned weights; expose knobs for latency budgets.
- Assumptions/dependencies: Fitness set reflects deployment distribution; latency constraints allow K>1; model storage budget fits K checkpoints.
- Data-efficient model development under regulatory constraints
- Sector: Healthcare, finance, government
- What to do: Use q0 to lift performance without acquiring more sensitive data, improving “data minimization” compliance while meeting capability targets.
- Tools/workflows: Document the held-out fitness set and its governance; track compute and data efficiency metrics for audits; incorporate snapshot provenance into model cards.
- Assumptions/dependencies: Regulators accept fitness-set-based model selection; data governance processes can ensure held-out separation.
- Domain-specific code models trained on small repos
- Sector: Software engineering (internal codebases), cybersecurity (rules/signatures)
- What to do: Apply q0 to continued pretraining of code LMs on proprietary code, where clean tokens are scarce, improving capability without scraping external data.
- Tools/workflows: Incorporate cyclic snapshotting into existing SFT/continued-pretraining pipelines; small-K ensembles for IDE-integrated inferences; optional distillation.
- Assumptions/dependencies: Sufficient tokenization and task alignment; inference latency constraints acceptable.
- Forecasting and time-series models when historic data is capped
- Sector: Energy (demand forecasting), finance (market microstructure), logistics (supply-demand)
- What to do: For transformer-based forecasters trained on limited histories, use q0’s cyclic snapshotting and learned mixing on a held-out fit window to improve generalization.
- Tools/workflows: Adapt chain distillation/logit caching to regression/likelihood heads; learned weights minimize held-out NLL.
- Assumptions/dependencies: Stationarity (or careful rolling fitness-set design); model supports probability outputs.
- Academic baselines for data-constrained scaling studies
- Sector: Academia
- What to do: Use q0 to benchmark data efficiency in compute-rich, data-limited regimes; replicate the paper’s N,C,τ recipes across sizes and modalities.
- Tools/workflows: Open-source training scripts for cyclic LR/WD, chain distillation, and a small “fitness optimizer”; report per-epoch trade-offs and top-K curves.
- Assumptions/dependencies: Reproducible seeds and logging; stable compute allocations for parallel trajectories.
- Small-budget training optimization (E≤4–8 epochs)
- Sector: Startups, small labs, edge/embedded
- What to do: Prefer “end-of-training snapshotting” (many closely spaced checkpoints in the last ~1 epoch) over full cycles; switch to 2 ep/cycle when budgets reach ~8 epochs.
- Tools/workflows: Lightweight checkpointing and greedy learned weighting; simple top-K selection.
- Assumptions/dependencies: Snapshot overhead minimal; data/compute strictly limited.
- Improved MLOps checkpoint selection
- Sector: MLOps/Platform teams
- What to do: Replace “pick last/best checkpoint” with a learned mixture over snapshots on a fitness set; serve top-K per latency tier.
- Tools/workflows: A service that trains β logits (softmax) over cached p(gt) per snapshot; exports weights and K-slices for inference tiers (mobile/server).
- Assumptions/dependencies: Fitness set maintenance; snapshot prediction caching pipeline.
- Safety & reliability through complementary member selection
- Sector: Safety-critical AI (triage, compliance review, code review)
- What to do: Use the learned prior to include complementary-but-not-individually-best snapshots, improving error coverage and ensemble robustness.
- Tools/workflows: Track overlap with “fitness-greedy” selections; monitor ensemble diversity/error-ambiguity metrics; optionally flag disagreements for human review.
- Assumptions/dependencies: Fitness set captures critical failure modes; monitoring infrastructure in place.
- Carbon and cost accounting improvements
- Sector: Sustainability/FinOps
- What to do: Translate the 3.8–4.6× epoch reduction at matched performance into energy/cost savings dashboards.
- Tools/workflows: Tie trainer to cost/CO2 meters (cloud provider billing + power models); report marginal cost per 0.01 loss or per accuracy point.
- Assumptions/dependencies: Savings persist at your model scale; cost-per-epoch roughly linear.
- Legal/contract NLP on constrained datasets
- Sector: Legal tech
- What to do: Use q0 for continued pretraining on limited contractual corpora to improve clause extraction, summarization, and Q&A accuracy without expanding datasets.
- Tools/workflows: Same as enterprise LLM use; top-K ensembles for back-office tools, distilled single model for client-facing apps.
- Assumptions/dependencies: Fitness set curated across contract types; latency constraints modest for internal tools.
Long-Term Applications
These opportunities require further research, scaling, or engineering (e.g., validation on larger models/datasets, new tooling for orchestration, or additional distillation work):
- Ensemble-to-single distillation at scale for low-latency deployment
- Sector: All production AI
- Idea: Distill the learned top-K snapshot ensemble into a single student to eliminate K× inference cost while retaining q0 gains.
- Dependencies: Robust, scalable distillation recipes for large LMs; evaluation of distribution shift and calibration retention.
- Auto-allocation planners for hyper-epoch budgets
- Sector: MLOps/AutoML
- Idea: A “compute allocation planner” that learns N*, C, τ policies as a function of total epoch/compute budget and observed learning curves, extending the paper’s staircase heuristic.
- Dependencies: Meta-optimization infrastructure; generalization across tasks and scales.
- Cross-modality q0 (vision, speech, RL policies)
- Sector: Robotics, autonomous driving, speech assistants, medical imaging
- Idea: Apply cyclic snapshotting + chain distillation + learned prior to fixed, high-quality datasets in other modalities (e.g., limited driving logs, curated image sets).
- Dependencies: Adaptation of distillation targets (e.g., continuous outputs), evaluation of ensemble gains under non-text losses.
- Dynamic “ensemble router” services
- Sector: Cloud AI platforms
- Idea: A service that serves learned-weight ensembles, auto-tunes K per request SLA, and updates weights online with fresh fitness telemetry.
- Dependencies: Real-time telemetry pipelines; robust prevention of feedback loops and data leakage into the fitness process.
- Population-based pretraining libraries and snapshot banks
- Sector: Open-source/model hubs
- Idea: Publish not just final checkpoints but snapshot populations and their learned priors, enabling downstream users to pick K for their budget.
- Dependencies: Storage/metadata standards; reproducibility of learned weights across hardware/software stacks.
- Uncertainty-aware systems leveraging complementary snapshots
- Sector: Healthcare diagnostics, financial decisioning
- Idea: Use disagreement-aware selection/weighting to improve calibrated uncertainty and outlier detection; escalate high-uncertainty cases to humans.
- Dependencies: Prospective validation; integration with human-in-the-loop workflows; regulatory acceptance.
- Federated or privacy-preserving q0 variants
- Sector: Mobile, healthcare, finance
- Idea: Local devices/sites train trajectories and share snapshot summaries or priors; aggregate learned weights centrally without raw data transfer.
- Dependencies: Secure aggregation; differential privacy for snapshot/weight sharing; standardization of fitness set definitions.
- Integration with MoE and routing architectures
- Sector: Large-scale LLMs
- Idea: Treat snapshots as static “experts” with learned gating; blend with MoE layers for dynamic, budget-aware routing.
- Dependencies: Training stability, memory/latency trade-offs, new compilers/schedulers.
- Policy and standards for fitness-set-based model selection
- Sector: Policy/Regulation
- Idea: Guidelines for held-out fitness set design, use, and disclosure in model evaluation and selection; reporting of ensemble weighting and compute usage.
- Dependencies: Multi-stakeholder consensus; reproducibility frameworks; auditability tooling.
- Sustainability benchmarks for data-constrained training
- Sector: ESG reporting, public sector
- Idea: Standardized metrics that reflect “loss/accuracy per kWh or $” under fixed data; q0-like methods as reference techniques.
- Dependencies: Agreement on protocols; third-party measurement.
- On-device/personalization with snapshot caching
- Sector: Consumer devices, privacy-first apps
- Idea: Periodic local training produces lightweight snapshot populations; device selects top-2/3 snapshots for fast ensemble inference; optional overnight distillation.
- Dependencies: Efficient training on-device; storage/energy constraints; robust fitness set definition for personal data.
- Automated diversity-aware curriculum and teacher refresh
- Sector: AutoML/Research
- Idea: Optimize teacher refresh cadence and snapshot selection to maximize complementary generalization while maintaining per-model quality; extend beyond fixed c_start.
- Dependencies: Additional theory/empirics; integration with adaptive curricula and data weighting.
Key Cross-Cutting Assumptions and Dependencies
- The fitness set must be representative of deployment data and strictly held out from training; leakage undermines the learned prior.
- Inference budget K>1 is acceptable, or high-quality distillation can recoup latency while preserving gains.
- Storage and serving infrastructure can handle multiple snapshots and associated metadata/logit caches.
- Reported gains were demonstrated at 1.8B params on 100M tokens; effectiveness should be revalidated across larger/smaller scales, domains, and modalities.
- Anti-correlated LR/WD cycles and chain distillation hyperparameters (α, T, c_start) may require tuning per task.
- Benefits rely on both accuracy and diversity; extreme chain distillation may over-couple snapshots in some settings and reduce diversity if not tuned.
- Domain shift can degrade the learned prior; periodic re-fitting on refreshed fitness data may be necessary.
Glossary
- AdamW: An Adam optimizer variant with decoupled weight decay that improves convergence and generalization in deep networks. "AdamW step"
- anti-correlated learning rate and weight decay: A schedule where learning rate and weight decay move in opposite directions across a cycle to alternate exploration and regularization phases. "A cyclic schedule with anti-correlated learning rate and weight decay collects diverse models"
- ARC-Easy: A multiple-choice reasoning benchmark derived from grade-school science questions, used for evaluating LLMs. "zero-shot accuracy on ARC-Easy"
- Bayesian model averaging: A method that combines models by weighting each according to its posterior probability under the data. "Bayesian model averaging by posterior plausibility"
- born again networks (BANs): A procedure where a sequence of students is trained using the outputs of their predecessors, often surpassing the teacher. "born again networks (BANs)"
- chain distillation: A self-distillation approach where each snapshot is trained using its immediate predecessor’s softened outputs to compound quality across a trajectory. "Chain distillation trains each model against its predecessor so that model quality compounds across the population."
- complexity prior: A prior favoring simpler hypotheses (short description length) when weighting explanations of data, inspired by Solomonoff’s framework. "weight them according to a complexity prior"
- cosine schedule: A learning-rate schedule that follows a cosine decay (often with restarts) over training. "single-cycle cosine reference"
- cross-entropy: A standard loss function measuring the divergence between predicted and true distributions, commonly used for classification and language modeling. "cross-entropy can extract"
- cyclic LR/WD schedule: A training schedule that cycles the learning rate and weight decay within each training cycle to traverse multiple basins. "cyclic LR/WD schedule"
- dark knowledge: Information contained in a teacher’s full probability distribution over classes (including incorrect classes), providing richer training signals than one-hot labels. "a dark knowledge signal"
- data efficiency: The amount of performance obtained per unit of data; higher values indicate better use of limited data. "data efficiency to "
- Deep ensembles: Collections of independently trained neural networks whose diverse errors improve aggregate performance when combined. "Deep ensembles obtain diversity"
- EMA weight averaging: Exponential Moving Average of parameters to stabilize training and often improve generalization. "EMA weight averaging"
- error--ambiguity decomposition: A framework decomposing ensemble error into average member error and their diversity (ambiguity). "The error--ambiguity decomposition of \citet{krogh1995neural} formalizes this."
- Fast Geometric Ensembling (FGE): An ensembling technique that samples models along low-loss paths connecting minima to build cheap, diverse ensembles. "Fast Geometric Ensembling (FGE)"
- fitness set: A small held-out slice of the training distribution used to learn ensemble weights without contaminating training. "held out fitness set"
- frozen teacher: A teacher model whose parameters are kept fixed while supervising a student during a training phase. "as a frozen teacher"
- hyper-epoch pretraining (q0): A compute-allocation framework that converts multi-epoch budgets into a diverse population of models combined at inference. "hyper-epoch pretraining (q0)"
- importance weighting: Adjusting example contributions based on teacher confidence or other criteria to emphasize more informative samples. "an implicit importance weighting"
- inference budget: The maximum number of models or forward passes allowed for ensemble prediction. "For any inference budget "
- Kolmogorov complexity: The length of the shortest program that produces a given object; used conceptually as a compressibility-based prior. "we cannot compute Kolmogorov complexity"
- learned generalization prior: A data-driven weighting over ensemble members, fitted on a fitness set to maximize held-out likelihood. "The learned generalization prior beats a fitness greedy baseline"
- loss landscape: The high-dimensional surface of the objective with respect to parameters, containing basins and minima that training explores. "region of the loss landscape"
- low-norm basin: A region in parameter space with small parameter norms, often associated with better generalization. "a low-norm basin"
- model soups: Simple parameter-space averages of multiple fine-tuned models to improve performance. "model soups"
- negative log-likelihood: The training or evaluation objective corresponding to the negative log probability assigned to the ground-truth data. "minimize the ensemble's mean negative log-likelihood"
- non-separable mixture loss: An objective where ensemble weights are optimized jointly inside the log-probability, coupling members’ contributions. "the non-separable mixture loss"
- posterior plausibility: The posterior probability that a model is correct given data, used to weight models in Bayesian model averaging. "posterior plausibility"
- pre-softmax logits: The raw, unnormalized scores output by a model before applying the softmax function. "pre-softmax logits"
- self-distillation: Training a model using its own (or a previous version’s) predictions as soft targets to improve performance. "self-distillation more broadly shows the same effect"
- Snapshot Distillation: A method that uses snapshots within a training run as teachers to regularize later snapshots. "Snapshot Distillation"
- snapshot ensembles: Ensembles built from multiple checkpoints (snapshots) taken along a single training run, often with cyclic schedules. "snapshot ensembles"
- Solomonoff induction: A theoretical framework for prediction and generalization that averages over all computable hypotheses weighted by simplicity. "Solomonoff induction"
- Stacked generalization: Learning a meta-combiner that integrates predictions from multiple models using held-out data. "Stacked generalization"
- Stochastic Weight Averaging: Averaging weights along a training trajectory to land in flatter, better-generalizing regions. "Stochastic Weight Averaging"
- temperature: A scaling factor applied to logits to soften or sharpen probability distributions in distillation. "T the temperature"
- uniform softmax averaging: Combining ensemble members by equally averaging their predicted probabilities. "uniform softmax averaging"
- validation loss: The loss measured on held-out validation data used to assess generalization. "a lower validation loss"
- warm restart: Resetting the learning rate to a high value during training cycles to escape local minima. "Warm restart"
- weight decay: L2-style regularization that penalizes large weights to promote generalization. "weight decay"
- zero-shot accuracy: Performance on tasks without task-specific fine-tuning or examples at inference time. "zero-shot accuracy"
Collections
Sign up for free to add this paper to one or more collections.