DynaMoE: Smarter Expert Allocation in Neural Networks
This presentation explores DynaMoE, a breakthrough framework that challenges fundamental assumptions in Mixture-of-Experts neural networks. By introducing dynamic token-level expert activation and layer-wise adaptive capacity allocation, DynaMoE achieves substantial improvements in parameter efficiency and performance across vision and language tasks. The talk reveals how matching computational resources to input complexity and layer-specific representational demands yields task-dependent optimal strategies, fundamentally advancing our understanding of adaptive neural architecture design.Script
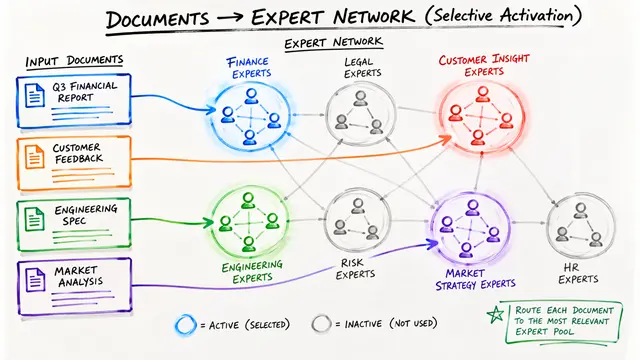
Standard Mixture-of-Experts networks make two rigid assumptions: every token activates exactly the same number of experts, and every layer gets exactly the same expert capacity. DynaMoE shatters both assumptions, and the results are striking.
The framework introduces percentile-thresholded gating that lets each token activate between 1 and nearly all available experts, governed by its complexity. Simultaneously, different layers receive different expert budgets through predefined schedules like descending, ascending, pyramid, and wave patterns. On CIFAR-10, descending schedules deliver over 5 percent accuracy improvement while converging faster than uniform baselines.
The architecture elegantly combines these two mechanisms into a unified framework.
Expert scheduling strategies shape the computational budget across network depth. Descending schedules concentrate maximum capacity in early layers where input diversity is highest, then taper toward the output. Ascending does the reverse, building capacity as representations deepen. Pyramid peaks at middle layers, while uniform maintains constant allocation. The key insight: these aren't arbitrary choices, they're architectural hypotheses about where complexity lives in different tasks.
The optimal schedule is not universal, it's task and scale dependent. In vision, descending schedules consistently win because early convolutional layers face maximum representational diversity from raw pixels. But in language modeling, the story changes with scale. Tiny models benefit from descending, Small models prefer ascending as deeper semantic integration becomes critical, and Medium models converge best with uniform allocation. This empirically confirms that schedule selection must match the representational diversity profile, not follow a one-size-fits-all rule.
These heatmaps reveal the routing decisions in action. With descending schedules, early layers light up with intense activation as tokens recruit many experts to handle input complexity. Uniform schedules show consistent activation across depth. Ascending schedules flip the pattern, concentrating expert engagement in deeper layers where abstract representations form. The visual difference is dramatic, and it directly corresponds to performance gaps measured across tasks.
The authors provide rigorous theoretical grounding. Dynamic routing expands the space of piecewise-linear functions the network can represent, increasing expressivity without adding parameters. Balanced expert utilization reduces gradient variance, improving convergence stability with a formal bound on variance reduction. And because expert activation is sparse and adaptive, you can scale parameter counts independently of inference cost, a crucial property for deployment. DynaMoE proves that smarter allocation beats bigger budgets.
DynaMoE reveals that the right expert at the right layer for the right token isn't just an optimization, it's a fundamental architectural principle. To explore this paper further and create your own research video, visit EmergentMind.com.