GutenOCR: Grounding Vision-Language Models
An overview of GutenOCR, a grounded vision-language front-end that bridges the gap between text generation and pixel-level provenance in document processing.Script
Imagine asking an AI to extract a critical liability clause from a contract, but when you ask where that text came from, it cannot point to the specific pixels on the page. This disconnection creates a "provenance gap" where we might trust the text, but we cannot verify its source. The paper we are examining today, titled GutenOCR, proposes a robust solution to anchor language models back to the visual reality of documents.
To understand why this work is necessary, we must look at the current landscape of document processing. On one side, we have modern vision-language models that read well but suffer from hallucinations regarding where text actually sits on a page. On the other side, classical OCR pipelines provide coordinates but are brittle and struggle with complex reasoning. This paper argues that production workflows are flying blind without a system that combines the flexibility of a language model with the verifiable pixel precision of a detector.
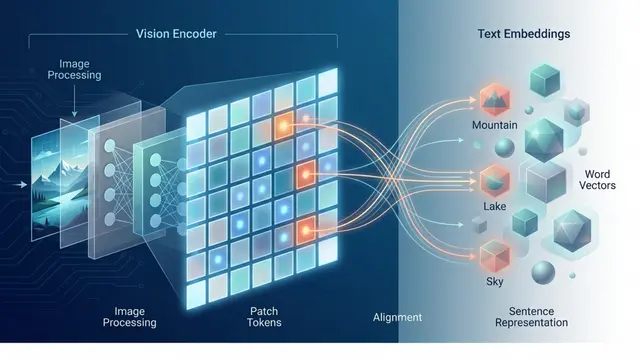
Addressing this gap, the researchers introduce GutenOCR. Instead of building a complex pipeline of separate models, they fine-tune the Qwen2.5-VL architecture to act as a unified, grounded front-end. This single model can perform multiple duties based on the prompt it receives, from transcribing a full page to detecting specific regions, always returning structured JSON that explicitly links text to its bounding box coordinates.
The power of this approach lies in how the authors structure the interaction and training. On the left, we see the model behaves like an API; you can ask it to read the whole page, find a specific word, or transcribe just one region. On the right, the researchers enabled this by using a staged curriculum, starting with synthetic datasets for basic grounding and progressively training on real business documents and scientific papers to handle complex, long-context layouts.
The results of this fine-tuning are dramatic, yet they reveal an interesting trade-off. As shown on the left, the model's ability to ground text doubled compared to the base model, and detection recall saw a massive thirty-fold increase. However, the right side highlights the cost: focusing so heavily on text and boxes caused the model to 'forget' some pre-training capabilities, specifically regarding color-coded tasks and complex mathematical formula recognition.
Ultimately, GutenOCR demonstrates that we can force dream-like vision models to be precise and verifiable, provided we accept some specialized trade-offs. This work suggests a future where AI reading agents are not just fluent, but fully accountable for every pixel they process.