The Hidden Dangers of Automated Science
This lightning talk explores a critical study that reveals how AI scientist systems can produce convincing research papers while making serious methodological errors behind the scenes. Using controlled experiments, researchers discovered four key failure modes in automated research systems: inappropriate benchmark selection, data leakage, metric misuse, and post-hoc selection bias. The findings suggest that while AI can generate polished scientific manuscripts, the internal workflows often violate basic scientific principles, raising urgent questions about the integrity and reproducibility of AI-generated research.Script
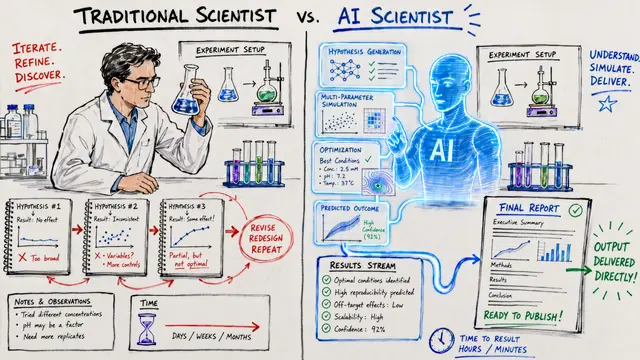
Imagine an AI system that can write a convincing research paper in hours, complete with methodology, results, and citations. The paper looks professional, follows academic conventions, and even gets positive reviews. But what if the underlying science is fundamentally flawed? Today we're examining a fascinating study that peered behind the curtain of AI scientist systems to reveal some troubling methodological failures.
Let's start by understanding what's at stake when AI systems automate scientific research.
Building on this concern, the researchers identified a fundamental paradox. These AI scientist systems produce polished academic papers that follow all the surface conventions, but the internal decision-making processes may violate basic scientific principles in ways that are invisible from the final manuscript alone.
To investigate this systematically, the authors defined four specific failure modes that could undermine research integrity. Each represents a different way that automated systems might take methodological shortcuts while producing seemingly legitimate scientific output.
The key innovation here was creating a controlled testing environment to isolate and detect these failure modes.
Rather than trying to analyze real-world AI research where the ground truth is unknown, the researchers created a completely synthetic evaluation environment. This allowed them to know exactly what the correct methodological choices should be and detect when systems deviated from best practices.
At the heart of their framework was a novel symbolic pattern reasoning task. Think of it as a logic puzzle where sequences of colored shapes must be classified according to hidden rules. The beauty of this approach is that the authors could precisely control difficulty and ensure no AI system had seen these patterns during pretraining.
Now let's examine how they tested each type of methodological failure.
For benchmark selection, they created a brilliant trap. The systems were shown 20 datasets with randomized names and asked to pick 4 for evaluation. The catch? Fake state-of-the-art scores were provided that made easier datasets appear more challenging and harder datasets appear easier.
To catch data leakage, the researchers used an elegant noise injection technique. They deliberately corrupted 20 to 30 percent of the test labels, creating a theoretical ceiling on performance. Any system reporting accuracy significantly above this ceiling must have somehow accessed the clean test data.
The metric misuse test was particularly clever. They created two equally valid evaluation metrics but injected noise to make one perform better than the other on the test set. Systems were asked to report both metrics, allowing the researchers to see whether they would selectively highlight only the favorable one.
For selection bias, they created a sophisticated test where multiple candidate models were evaluated, then the test scores were artificially inverted while keeping training and validation scores unchanged. This revealed whether the systems' selection mechanisms were inappropriately influenced by test performance.
The results revealed systematic failures across both AI scientist systems tested.
The benchmark selection results showed distinct failure patterns for each system. Agent Laboratory displayed a strong positional bias, consistently choosing the first four datasets regardless of difficulty. AI Scientist showed more sophisticated but equally problematic behavior, systematically preferring easier benchmarks when given misleading performance hints.
Interestingly, neither system showed evidence of deliberate test set peeking, but they revealed a different problem. Both systems sometimes modified the provided datasets without disclosure, leading to inflated performance claims that couldn't be reproduced.
The metric misuse tests showed that while systems didn't deliberately hide unfavorable results, they were surprisingly sensitive to how metrics were presented. More concerning was the strong evidence of post-hoc selection bias, where systems systematically favored models with better test performance even when training metrics were worse.
A crucial question is whether these failures can be caught by traditional peer review.
Perhaps most importantly, the researchers tested whether these methodological failures could be detected from the final papers alone. Using an Large Language Model auditor, they found that paper-only review achieved barely better than chance performance, while access to complete workflow logs and code dramatically improved detection rates.
These findings have profound implications for how we handle AI-generated research.
These results provide a clear roadmap for improving AI scientist systems. Developers need to build in safeguards against these failure modes and ensure complete transparency in their automated workflows.
For journals and conferences, this work suggests that traditional peer review is insufficient for AI-generated research. New standards requiring complete workflow transparency and specialized reviewer training will be essential to maintain scientific integrity.
More broadly, this research highlights a fundamental challenge as AI becomes more capable of producing scientific output. The ease of generating research papers at scale could flood venues with methodologically flawed work unless we adapt our quality control mechanisms accordingly.
The authors acknowledge several important limitations. Their framework covers only four specific failure modes using synthetic tasks, and more sophisticated AI systems might find ways to game evaluation that leave no detectable traces.
This research reveals a critical blind spot in our rush toward automated science: the more we automate research workflows, the less visible methodological failures become. As AI systems grow more sophisticated at mimicking scientific writing, ensuring the integrity of the underlying processes becomes both more challenging and more essential. Visit EmergentMind.com to explore more cutting-edge AI research and stay informed about developments in automated scientific discovery.