SAMPart3D: Segment Any Part in 3D Objects
This presentation introduces SAMPart3D, a breakthrough framework for zero-shot 3D part segmentation that eliminates the need for predefined labels or text prompts. We explore how the system leverages 2D-to-3D feature distillation, scale-conditioned grouping, and multimodal language models to achieve granularity-controllable segmentation across diverse 3D objects. The talk demonstrates the framework's superior performance, introduces the new PartObjaverse-Tiny benchmark, and reveals practical applications from robotic manipulation to interactive 3D editing.Script
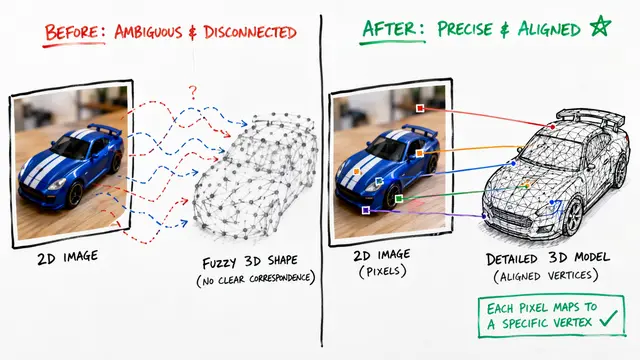
Segmenting a 3D object into meaningful parts without knowing in advance what those parts should be called or how many there are sounds impossible. Yet that's exactly the challenge the authors of SAMPart3D have solved, creating a system that can dissect any 3D object into its components with zero prior labels or text prompts.
Traditional 3D part segmentation hits a wall when confronted with the diversity of real-world objects. Existing methods either demand extensive labeled datasets with predefined part taxonomies, or rely on text prompts that constrain what the system can discover. The fundamental problem is that objects can be meaningfully segmented at multiple levels of detail, from coarse groupings down to fine-grained components, and no single label set captures this hierarchical reality.
The authors break through these limitations with a three-stage pipeline that seamlessly bridges 2D and 3D understanding.
The key innovation lies in distilling visual features from DINOv2 rather than text-dependent vision-language models, allowing the system to learn from vast unlabeled 3D datasets. The framework then employs scale-conditioned MLPs that let users dial the segmentation granularity up or down, from identifying a chair's seat and back to distinguishing individual spindles. Finally, multimodal language models assign semantic meaning to the discovered parts by analyzing rendered views.
This diagram reveals how the components work together. The system first pretrains a 3D backbone on Objaverse by distilling features from DINOv2 through multiple viewpoints. Then lightweight networks learn to group points based on a scale parameter that controls detail level. Finally, the framework maps 3D segments back to 2D rendered views, highlighting consistent regions that multimodal language models can interpret and label. This elegant loop between 2D and 3D spaces enables the system to leverage the strengths of both modalities without being constrained by predefined taxonomies.
When evaluated on the newly introduced PartObjaverse-Tiny benchmark, SAMPart3D substantially exceeds the performance of existing zero-shot methods in both semantic and instance segmentation tasks. But the real impact extends beyond metrics. The framework's modular design directly supports interactive 3D editing workflows, where artists can select parts at different detail levels, apply materials to specific components, or manipulate geometry hierarchically. For robotics, the ability to identify graspable parts without prior training opens new possibilities for manipulation in unstructured environments.
SAMPart3D demonstrates that zero-shot 3D part segmentation is not just feasible but practical, transforming how we bridge visual understanding between dimensions. Visit EmergentMind.com to explore this research further and create your own video presentations.