Shared LoRA Subspaces for Almost Strict Continual Learning
This presentation explores a breakthrough method called Share that enables large pretrained models to continually learn new tasks without forgetting old ones, using remarkably few parameters. By discovering and exploiting a shared low-dimensional subspace that emerges across related tasks, Share achieves near-perfect continual learning with 100x fewer parameters than traditional approaches, while maintaining performance across language, vision, and generative domains. The work fundamentally redefines the efficiency boundaries of continual adaptation in foundation models.Script
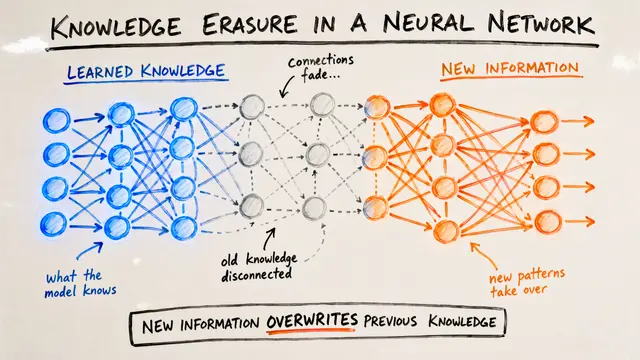
Imagine your AI model learning hundreds of new skills without forgetting a single one it learned before, all while using less memory than a single traditional adapter. That's the promise researchers are now delivering with a elegant mathematical insight about how neural networks actually share knowledge.
To understand why this matters, we first need to see what's broken in current approaches.
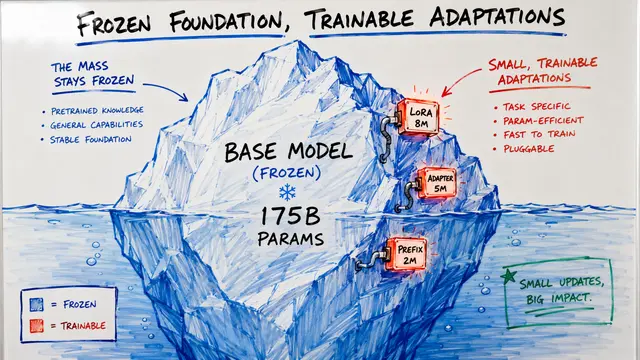
Building on that challenge, the core issue is that while LoRA adapters reduce parameters for individual tasks, they don't solve the explosion problem. Each new task still requires its own adapter, and eventually you're managing hundreds or thousands of separate parameter sets with no knowledge sharing.
The authors discovered something surprising hidden in how these adapters actually behave.
This empirical observation transforms the entire problem. Instead of treating each task independently, the researchers realized they could extract and maintain the principal directions that matter across all tasks, then represent each task as a lightweight combination of those shared directions.
Let's see how this insight becomes a practical algorithm.
Continuing from initialization, the beauty of Share is its mathematical elegance. When a new task arrives, the method doesn't start from scratch or add completely new parameters. It identifies whether the task fits within the existing subspace, and if not, expands minimally while maintaining all prior knowledge through analytical reprojection.
This schematic reveals the efficiency at the heart of Share. Notice how the method maintains a compact set of principal factors that remain largely frozen, while only the lightweight coefficients adapt to new tasks. The merging step analytically integrates new knowledge without catastrophic interference, and the entire process operates with strictly bounded memory regardless of how many tasks you encounter.
Now let's examine how this theoretical framework performs in practice.
Bridging theory to impact, the empirical results are striking. Share matches or exceeds the performance of full task-specific LoRA adapters while using a fraction of the resources. On GLUE benchmarks, vision datasets like CIFAR and Food-101, and even text-to-image generation, Share maintains high accuracy with dramatically reduced forgetting compared to replay-based methods.
Perhaps most impressive is Share's scalability to real-world scenarios. In experiments with Mistral-7B, the method continually integrated hundreds of independently trained adapters, compressing them into a unified subspace while preserving their individual capabilities. This opens possibilities for decentralized learning where adapters arrive asynchronously from different sources.
Share fundamentally redefines what's possible in continual learning by proving that the knowledge we need isn't scattered across countless adapters, but concentrated in a surprisingly compact shared subspace. Visit EmergentMind.com to explore how this breakthrough enables sustainable, scalable adaptation of foundation models.