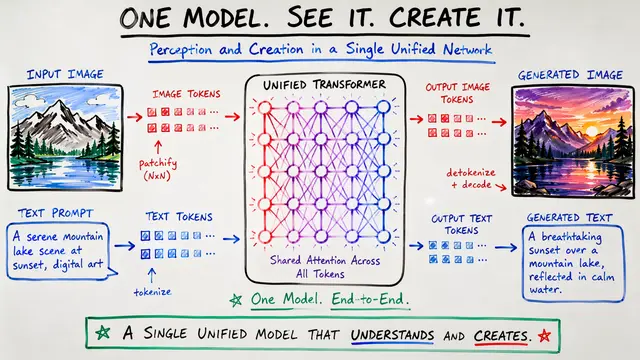
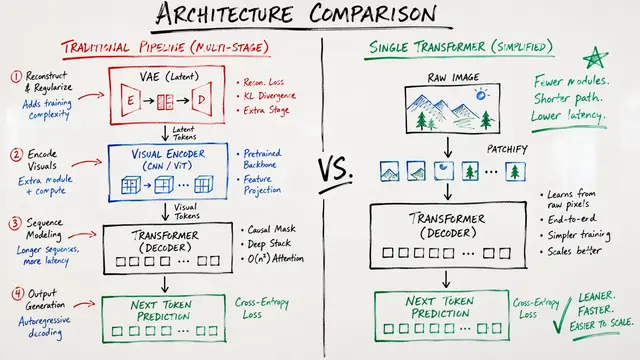
VQRAE: One Tokenizer for Understanding, Generation, and Reconstruction
This presentation explores VQRAE, a novel approach that solves a fundamental challenge in multimodal AI: creating a single visual tokenizer that excels at understanding, generation, and reconstruction simultaneously. We'll examine how the authors overcome the typical trade-offs between semantic and pixel-level representations through innovative quantization of high-dimensional semantic features and a two-stage training strategy with self-distillation.Script
Picture trying to build one system that can understand images like a human, generate new ones like an artist, and reconstruct details like a camera. This fundamental challenge has forced AI researchers to choose between semantic understanding and pixel-perfect details, until now.
Building on this tension, current visual tokenizers face an impossible triangle. Understanding tasks work best with continuous semantic embeddings, while generation needs discrete tokens for next-token prediction, and reconstruction requires preserving fine details that quantization typically destroys.
Existing solutions either split the problem with dual encoders that add complexity, or force everything through discrete tokens that damage understanding through quantization errors. The authors ask a provocative question: what if one tokenizer could output both continuous features and discrete tokens simultaneously?
VQRAE flips conventional wisdom by quantizing semantic features rather than pixel features.
The key insight is elegantly simple: use the continuous features directly for understanding while quantizing them for generation and reconstruction. This approach preserves semantic richness by operating at the level of vision transformer features rather than raw pixels.
Rather than using convolutional encoders typical in VQ approaches, VQRAE builds on vision transformers throughout. The authors discovered that quantizing high-level semantic features allows much larger codebooks without the collapse issues that plague pixel-level quantization.
The training approach carefully balances semantic preservation with reconstruction capability.
Stage one establishes the quantization and reconstruction capability while protecting the semantic understanding features. By freezing the pretrained encoder, the authors ensure that the strong semantic representations from foundation models remain intact.
Stage two introduces the critical self-distillation mechanism. A frozen teacher copy of the original encoder constrains the fine-tuning process, allowing the encoder to adapt for better reconstruction while preserving its semantic understanding capabilities.
The authors demonstrate that this unified approach achieves competitive performance across all three target tasks.
The reconstruction results validate the high-dimensional quantization approach. While conventional wisdom suggests low-dimensional codebooks for stability, the authors show that semantic features can support much richer quantization without collapse.
For understanding tasks, VQRAE delivers on its promise by outperforming other unified approaches. The ability to plug directly into existing multimodal language models without special adaptation makes it practically valuable for real applications.
The generation results complete the triangle, showing that the discrete tokens from VQRAE support effective autoregressive image synthesis. This validates that quantizing semantic features doesn't sacrifice the discrete structure needed for generation.
Several counterintuitive findings emerge from this work that challenge conventional approaches.
The success of VQRAE challenges several established practices in visual tokenization. By moving quantization up to the semantic level, the authors unlock the ability to use much richer codebooks while maintaining the unified architecture that dual-encoder systems abandon.
The experimental setup demonstrates broad applicability across different foundation models and training regimes. The comprehensive comparison against both reconstruction-focused and understanding-focused baselines provides strong evidence for the unified approach.
The authors acknowledge remaining challenges while pointing toward promising research directions.
Like any ambitious approach, VQRAE faces remaining challenges. The authors are refreshingly honest about failure cases, particularly in text rendering and complex scenes, while suggesting that post-training techniques could address many issues.
The future directions reveal the broader vision: moving beyond merely avoiding trade-offs toward finding genuine synergies between understanding, generation, and reconstruction. This opens fascinating questions about how different visual tasks might actually reinforce each other.
VQRAE represents more than just another tokenization method. By showing that semantic-level quantization can support the full spectrum of visual tasks, it suggests a path toward simpler, more unified multimodal architectures that could reshape how we build AI systems.
VQRAE demonstrates that the supposed conflict between understanding and generation is not fundamental, but rather a consequence of where we choose to draw the line between continuous and discrete representations. For more insights into cutting-edge AI research like this, visit EmergentMind.com to explore the latest developments shaping the future of artificial intelligence.