- The paper introduces a CRNN model that unifies convolutional feature extraction, bidirectional LSTM sequence modeling, and CTC-based transcription for scene text recognition.
- It demonstrates high accuracy on benchmarks like IIIT-5K, Street View Text, and ICDAR, accommodating both lexicon-free and lexicon-driven scenarios.
- The model's efficient design with 8.3 million parameters and ADADELTA optimization supports deployment on resource-constrained devices.
An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
Introduction
The paper introduces "An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition." The research presents a novel neural network architecture designed for image-based sequence recognition, specifically targeting the challenging task of scene text recognition. The proposed architecture integrates feature extraction, sequence modeling, and transcription into a unified framework, referred to as the Convolutional Recurrent Neural Network (CRNN).
Network Architecture
The CRNN architecture consists of three main components: convolutional layers for feature extraction, recurrent layers for sequence modeling, and a transcription layer that converts frame predictions into a final label sequence.
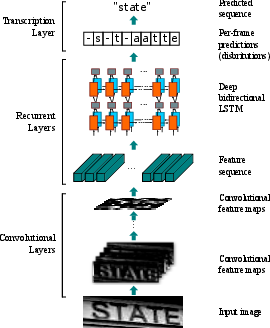
Figure 1: The network architecture. The architecture consists of three parts: 1) convolutional layers, which extract a feature sequence from the input image; 2) recurrent layers, which predict a label distribution for each frame; 3) transcription layer, which translates the per-frame predictions into the final label sequence.
The convolutional layers leverage the strengths of DCNNs, allowing for translation-invariant feature representation directly from raw image data. Recurrent layers, composed of deep bidirectional LSTM units, further enhance the model by capturing contextual sequences from input images.
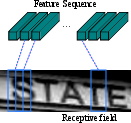
Figure 2: The receptive field. Each vector in the extracted feature sequence is associated with a receptive field on the input image, and is considered as the feature vector of that field.
A significant advantage of CRNN is its ability to handle sequences of arbitrary length without requiring character segmentation or predefined lexicons. This feature is beneficial for handling various scripts and sequence-like content beyond scene text, such as musical scores (Figure 1).
Sequence Modeling with Recurrent Layers
A pivotal aspect of CRNN is the integration of recurrent neural networks, specifically LSTM units, which address the vanishing gradient problem.
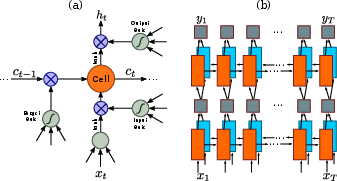
Figure 3: (a) The structure of a basic LSTM unit. An LSTM consists of a cell module and three gates, namely the input gate, the output gate and the forget gate. (b) The structure of deep bidirectional LSTM used in the paper. Combining a forward and backward LSTM results in a bidirectional LSTM. Stacking multiple bidirectional LSTM results in a deep bidirectional LSTM.
Deep bidirectional LSTMs enable CRNN to utilize context from both directions, allowing for rich sequential information to inform the labeling process. This contributes to the model's robustness against sequence length variability and improves recognition accuracy.
Transcription Layer
The transcription layer efficiently converts per-frame predictions into label sequences using Connectionist Temporal Classification (CTC). The CTC framework supports lexicon-free and lexicon-based transcription modes. Lexicon-free transcription determines the most probable sequence directly from predictions, whereas lexicon-based transcription restricts predictions to existing lexicons.
Experimental Results
CRNN demonstrates superior performance across standard text recognition benchmarks such as IIIT-5K, Street View Text, and ICDAR datasets. Notably, it achieves high accuracies in both lexicon-driven and lexicon-free scenarios.
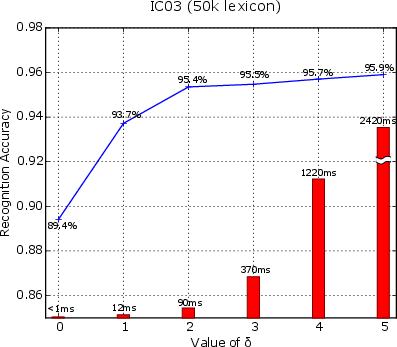
Figure 4: Blue line graph: recognition accuracy as a function parameter δ. Red bars: lexicon search time per sample. Tested on the IC03 dataset with the 50k lexicon.
The results highlight CRNN's competitive advantage over existing methods, especially in lexicon-constrained environments.
Furthermore, CRNN shows promising results in Optical Music Recognition (OMR), surpassing commercial systems like Capella Scan and PhotoScore on diverse musical score datasets (Figure 5).

Figure 5: (a) Clean musical scores images collected from Musescore (b) Synthesized musical score images. (c) Real-world score images taken with a mobile phone camera.
Implementation and Optimization
Implementation of CRNN within the Torch7 framework includes custom LSTM units, CTC transcription layers, and BK-tree-based lexicon searches. Training leverages ADADELTA, optimizing per-dimension learning rates without manual adjustments, offering faster convergence over traditional methods.
CRNN's compact model size, with only 8.3 million parameters, facilitates deployment in resource-constrained environments such as mobile devices. The unified training process using image-sequence pairs further streamlines model development without necessitating detailed component annotations.
Conclusion
The CRNN architecture offers an integrated solution for image-based sequence recognition, demonstrating versatility and robustness across various domains, including scene text and music score recognition. By combining convolutional and recurrent neural network strengths, CRNN provides a comprehensive and efficient approach to sequence recognition tasks. Future research could explore additional applications and optimized deployment strategies to enhance real-world usability.