- The paper reformulates regression trees as sparse neural networks to merge the interpretability of tree-based methods with the smooth decision boundaries of neural models.
- The study proposes two training regimes—independent and joint—that reduce overfitting and parameter count using trainable smooth activations.
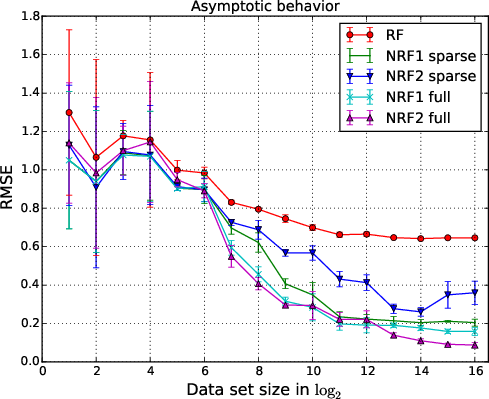
- Empirical results demonstrate that neural random forests achieve lower RMSE and enhanced sample efficiency compared to traditional random forests on various datasets.
Introduction and Background
The paper "Neural Random Forests" (1604.07143) explores a principled connection between ensemble methods based on regression trees—specifically, Breiman's Random Forests—and multilayer neural network architectures. The main motivation is to combine the explicit data-driven partitioning and interpretability of random forests with the expressive, smooth decision surfaces offered by neural networks. The authors present a rigorous reformulation whereby each regression tree in a forest can be mapped to a sparse feedforward neural network, and extend this formulation to new hybrid predictors, termed neural random forests (NRFs), with trainable smooth activation functions. This hybridization aims to leverage the strengths of both paradigms while mitigating their respective drawbacks: overfitting in dense neural network models and rigid, axis-aligned partitions in trees.
Random Forests as Sparse Neural Networks
The first major contribution of the paper is a formal mapping from binary regression trees to specific three-layer neural networks. In this construction:
- The first hidden layer consists of perceptrons encoding the outcomes of tree node splits via threshold functions.
- The second hidden layer reconstructs leaf memberships based on sequences of splits using weighted connections.
- The output layer computes the average response for data points in the corresponding leaf region.
This mapping is extended to an ensemble: each tree in a random forest is reinterpreted as a sparse, multilayer neural network with architectural properties induced by the tree structure and data-specific partitions.
Neural Random Forests: Two Training Regimes
Leveraging the tree-to-network equivalence, the authors propose two training approaches for neural random forests:
Method 1: Independent training
Each tree-derived network is trained individually with gradient-based methods using smooth activations (hyperbolic tangent tanh) to replace step functions, and the ensemble prediction is the average across networks.
Method 2: Joint training
All tree-derived networks are concatenated into a single larger network, and all parameters are jointly optimized.
Both approaches dramatically reduce the number of trainable parameters compared to fully connected networks, yielding O(KnlogKn) parameters for balanced trees, rendering the approach scalable to high-dimensional data.
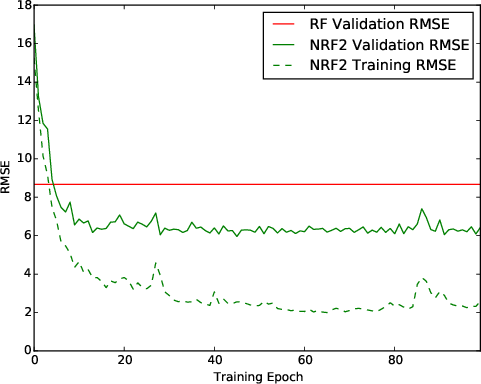
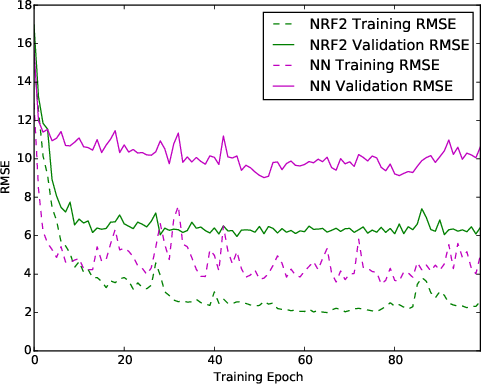
Figure 1: Evolution of training set and validation RMSE for different models. Left: The NRF model achieves lower validation RMSE than the original random forest, and substantially better training RMSE than standard NNs in the same architectural regime.
Theoretical Analysis and Consistency Guarantees
A central claim supported by extensive analysis is that both neural random forest methods are mean-squared error consistent estimators of the regression function under mild conditions: specifically, if the number of tree leaves Kn and activation sharpness parameters γ1,γ2 grow appropriately with the sample size n. The authors specify explicit asymptotic regimes and prove that the ensemble prediction converges to the true regression function as n→∞, provided the regression function lies in a rich function class (including additive, polynomial, and certain product forms).
This consistency result is significant because it demonstrates that the smooth relaxation of crisp tree node membership—via smooth activations and backpropagation-based training—does not compromise the theoretical guarantees typically enjoyed by random forests, while potentially yielding superior finite-sample behavior.
Empirical Evaluation
Extensive experiments on synthetic and real regression datasets from the UCI repository compare neural random forests (NRF) against standard random forests (RF), fully connected neural networks (NN1–NN3), and Bayesian Additive Regression Trees (BART). Key findings are:
Implications and Future Directions
The results underscore the practical value of leveraging tree structures to induce inductive bias and interpretability into neural network models, particularly for low-data and high-dimensional regimes. The NRF architecture integrates the smooth optimization landscape of neural networks with the partitioning efficiency of tree-based methods, enabling gradient-based training and differential relaxation along tree split directions.
From a theoretical perspective, the demonstrated consistency and strong empirical performance suggest that neural random forests are robust alternatives to traditional ensembles and dense neural networks, especially when interpretability and sample efficiency are requisites.
Practical deployment of NRFs is facilitated by a reduction in meta-parameter tuning: architectural decisions are determined by the underlying random forest, and training is manageable even for high-dimensional problems.
Potential future research avenues include:
- Extending NRF formulations to classification and probabilistic prediction.
- Investigating variable selection and feature importance within the NRF framework.
- Merging BART's Bayesian machinery with NRF initialization for uncertainty quantification.
- Developing scalable, sparse matrix multiplication routines for efficient NRF training in large-scale applications.
- Analysing robustness to overfitting and exploring regularization strategies beyond ensemble averaging.
Conclusion
The "Neural Random Forests" paper provides a comprehensive bridge between random forests and neural networks, presenting a rigorous mapping and novel hybrid architecture (NRF) with formal consistency guarantees and strong empirical results. The study demonstrates that initializing neural networks from tree structures and exploiting their sparse architectures yields models that are interpretable, sample-efficient, and less prone to overfitting than fully connected networks. Neural random forests thus offer a theoretically sound and practically appealing middle ground between tree-based ensembles and neural optimization in regression tasks, warranting further investigation and adoption within the broader machine learning community.