- The paper introduces a deep learning approach leveraging a BiLSTM network to predict online content popularity solely from titles.
- The model uses pre-trained GloVe embeddings and bidirectional processing to capture semantic nuances, achieving over a 15% accuracy gain on benchmark datasets.
- The study highlights practical implications for content creators and digital marketers by optimizing title formulations to drive higher engagement.
Overview
The paper "Shallow reading with Deep Learning: Predicting popularity of online content using only its title" (1707.06806) presents a deep learning methodology for predicting the popularity of online content based solely on its title. The study leverages the architectural advantages of a bidirectional Long Short-Term Memory (BiLSTM) network, showing a significant improvement over traditional methods for binary classification of content popularity. The focus is on enhancing interpretability and accuracy in predicting whether a piece of online content will become popular.
Methodology
The proposed method formulates the problem as a binary classification task, assessing whether an online content title suggests it will be popular or not. The architectural foundation is a BiLSTM network that processes input sequences bidirectionally to capture the entire context of the title. The authors employ pre-trained GloVe embeddings for word representation, facilitating a richer semantic understanding from the outset. The hidden state interpretation is emphasized, allowing for introspection of each word's contribution to predicted popularity.
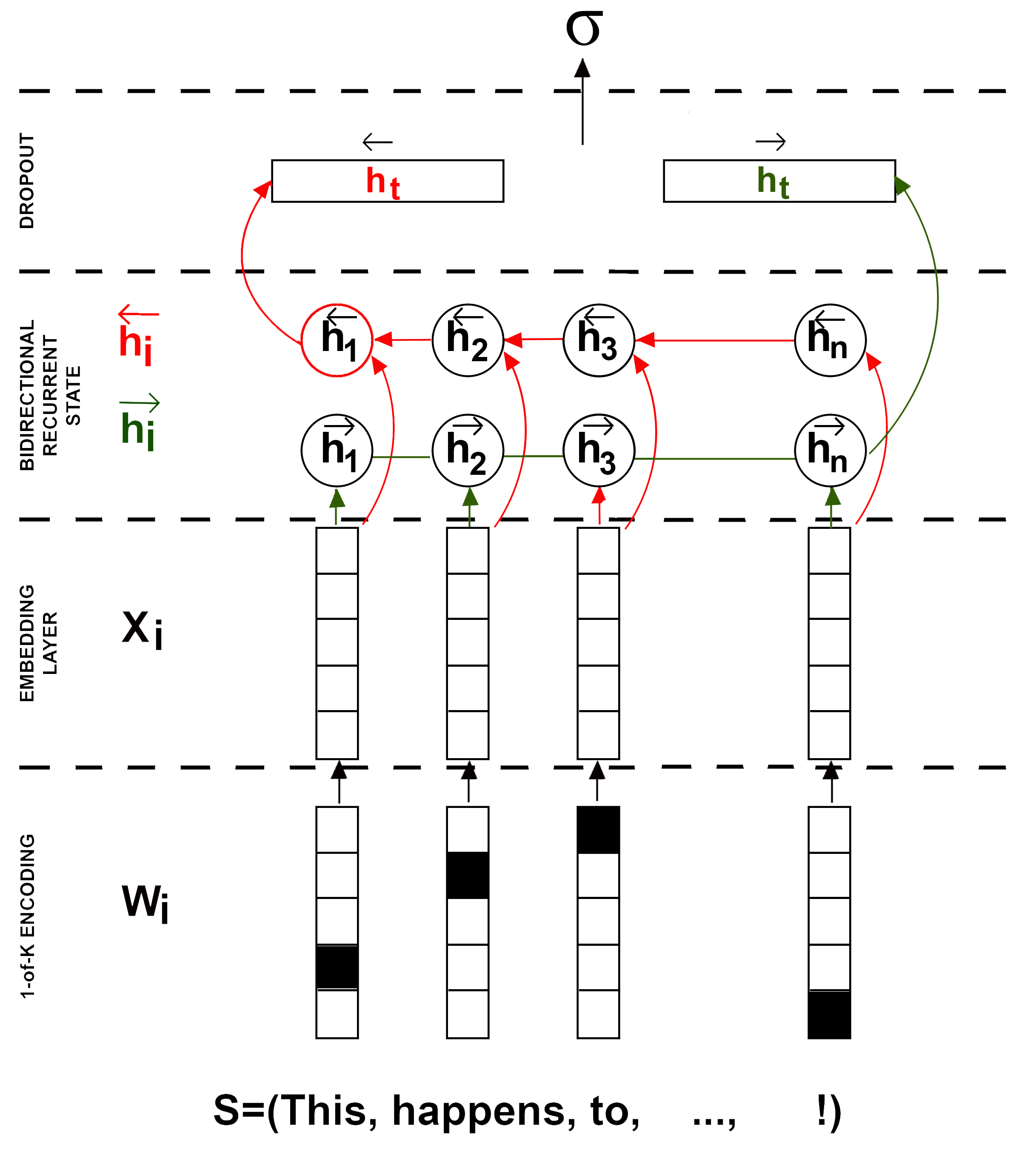
Figure 1: A bidirectional LSTM architecture with 1-of-K word encoding and embedding layer proposed in this paper.
Text Representation and Bidirectional LSTM
Utilizing word embeddings from large corpora, the model captures semantic nuances of the titles. By initializing the embedding layer with pre-trained GloVe vectors, the method improves upon foundational text representation techniques. The BiLSTM architecture is central to the performance gain. It processes sequences forwards and backwards, so every element informs the final prediction irrespective of its position in the sequence. The concatenated forward and backward passes provide a more robust representation for classification.
Advantageous Training Techniques
The model employs the Adam optimization algorithm for training, incorporating techniques like learning rate reduction and early stopping to enhance convergence and prevent overfitting. This disciplined approach to optimization ensures that the model attains a balance between capacity and generalization, effectively embodying the complexity necessary to capture subtle relationships.
Evaluation
The evaluation demonstrates significant accuracy gains over baseline models across two datasets: NowThisNews and Breaking News. On the NowThisNews dataset, the BiLSTM approach surpasses traditional BoW and CNN methods, registering over a 15% improvement relative to shallow techniques. The Breaking News dataset evidences similar trends, confirming the model's robustness and indicating the feasibility of predicting popularity from sparse data like titles alone.
The performance metrics, detailed in the paper, underscore the BiLSTM's efficacy in handling diverse text inputs with improved semantic comprehension compared to conventional methods. The use of word vector fine-tuning further refines model predictions, particularly on datasets with more narrowly defined content contexts.
Discussion
The implications of this work extend to content creators and digital marketers who can employ such models to optimize titles for maximum impact, thereby leveraging data-driven insights in creative processes. The ability to generate context-dependent vector interpretations opens avenues for nuanced content quality analysis and A/B testing for title selection.
Despite these advantages, the study also acknowledges the potential for further improvement through character-level models and multimodal approaches that incorporate image or video data. Such extensions could provide an even more comprehensive framework for predicting online content popularity, integrating textual and non-textual data into a unified predictive model.
Conclusion
This study introduces a sophisticated approach for online content popularity prediction using BiLSTMs, showcasing significant advancements over traditional shallow classifiers. It demonstrates the potential for deep learning to provide actionable insights in digital content strategy, enhancing both accuracy and interpretability. Future work will likely explore integrating multimodal data and further refining character-level text representations to continue improving prediction accuracy and broad applicability.