- The paper introduces a dual-anchoring approach combining statistical clustering and LLM-based semantic feature generation to counteract temporal prediction drift.
- It employs multi-modal feature extraction using VideoLLaMA3, BERT, ViT, and Open-L3 to create robust, high-dimensional representations.
- Experiments on 6,000 TikTok videos demonstrate significant improvements in MAE and MAPE over traditional models, validating the framework's efficacy.
Introduction
The paper, "Anchoring Trends: Mitigating Social Media Popularity Prediction Drift via Feature Clustering and Expansion," addresses the challenge of prediction drift in social media popularity prediction. As user-generated content on platforms like TikTok and Instagram continues to grow, predicting which content will become popular poses significant challenges due to temporal distribution shifts. Traditional prediction models, which often rely on historical data, degrade in performance as they fail to accommodate the rapidly changing trends, memes, and user behaviors.
Anchored Multi-modal Clustering and Feature Generation Framework
The proposed solution is the Anchored Multi-modal Clustering and Feature Generation (AMCFG) framework. The framework aims to introduce temporally invariant patterns across different data distributions by combining multi-modal clustering with semantic feature generation using LLMs. The model is inspired by Test-Time Adaptation (TTA) techniques utilized in computer vision, aiming to adapt spatial domain adaptation strategies to temporal distribution issues faced in social media content.
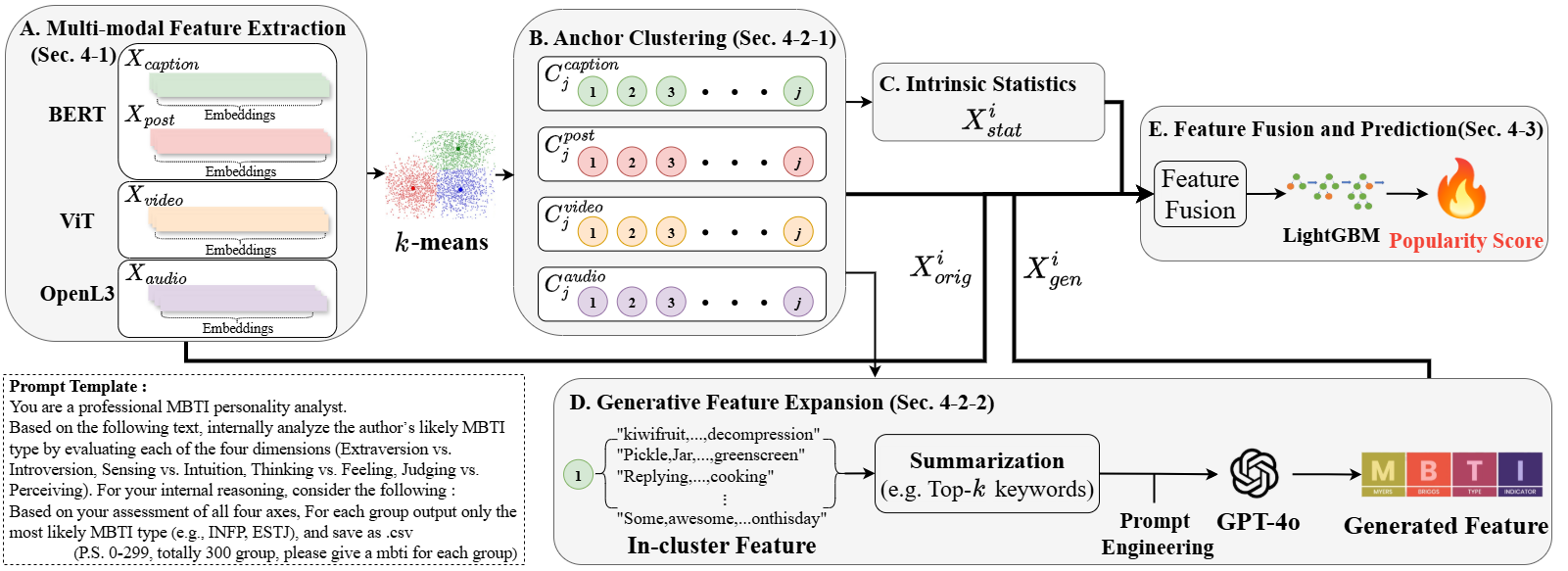
Figure 1: Overall architecture of the proposed Anchored Multi-modal Clustering and Feature Generation (AMCFG) framework. Our TTA-inspired approach leverages multi-modal clustering to discover stable behavioral patterns, then generates dual anchoring features: statistical anchors from cluster-level engagement patterns and semantic anchors from LLM-based thematic analysis.
Framework Details
- Feature Extraction: The AMCFG framework begins with feature extraction that encodes textual, visual, and audio contents into high-dimensional representations. VideoLLaMA3 and BERT are employed for text, Vision Transformer (ViT) for videos, and Open-L3 for audio.
- Multi-modal Clustering: The data across modalities are clustered to reveal stable behavioral patterns. Each modality features k-means clustering (with k=300) to identify cluster-level engagement trends, creating statistical anchors that summarize these patterns numerically.
- Semantic Anchor Generation: LLMs are used to analyze clusters to ascertain thematic descriptions and personality profiles, creating semantic anchors. These features capture high-level concepts that are stable over time despite trend evolution.
- Feature Fusion: Combining original feature embeddings with statistical and semantic anchors forms a composite feature space used to train predictors, ensuring stability and resistance to temporal distribution shifts.
Experimental Results
The framework was evaluated on a dataset of 6,000 TikTok videos, achieving a Mean Absolute Error (MAE) and Mean Absolute Percentage Error (MAPE) that significantly outperformed baseline models. Results indicated a marked improvement in robustness and predictive accuracy when compared to traditional methods, notably demonstrating effectiveness in generalizing predictions across temporal content changes.
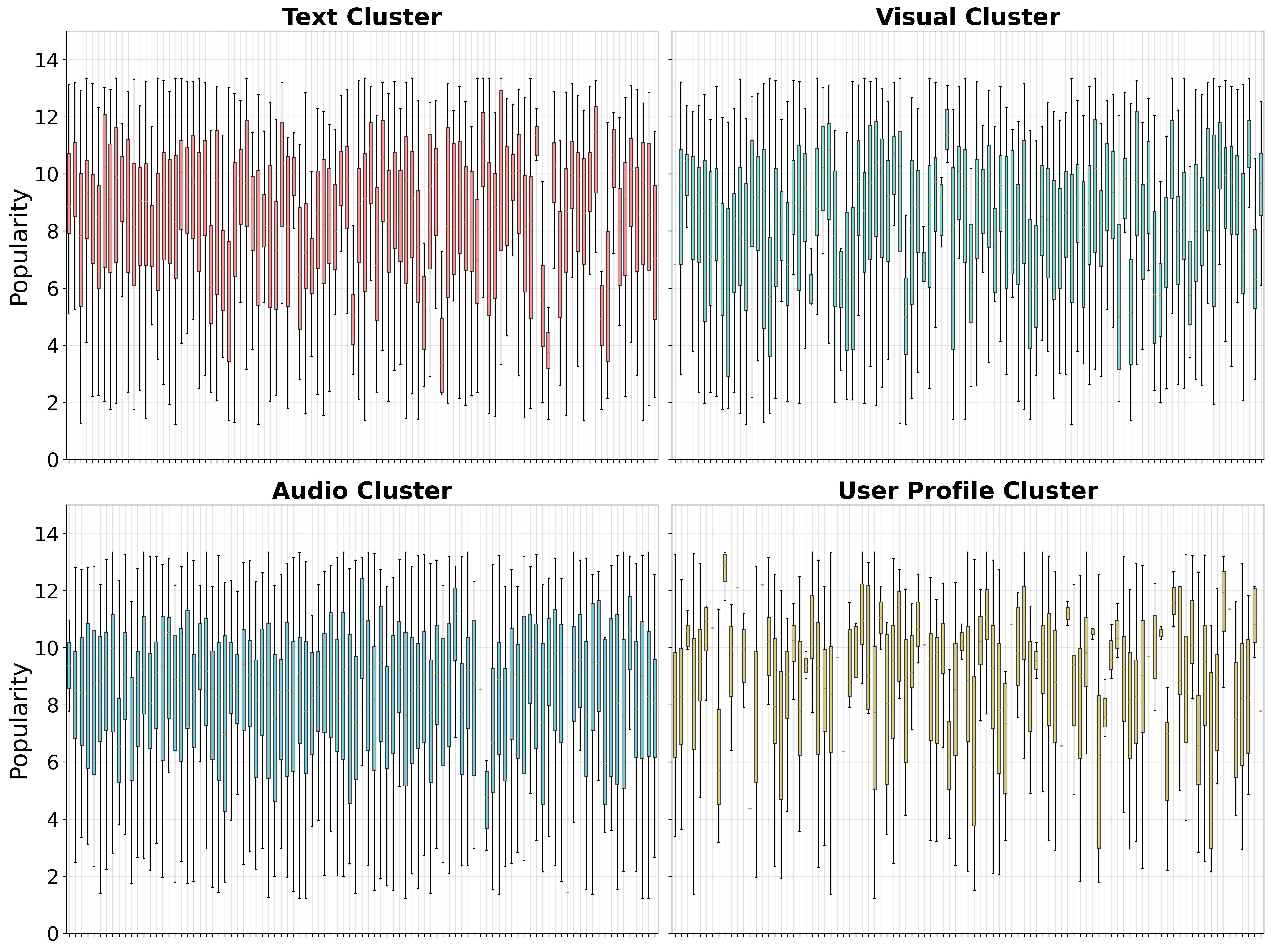
Figure 2: Clustering visualization of four modalities (text, video, audio, and user profile).
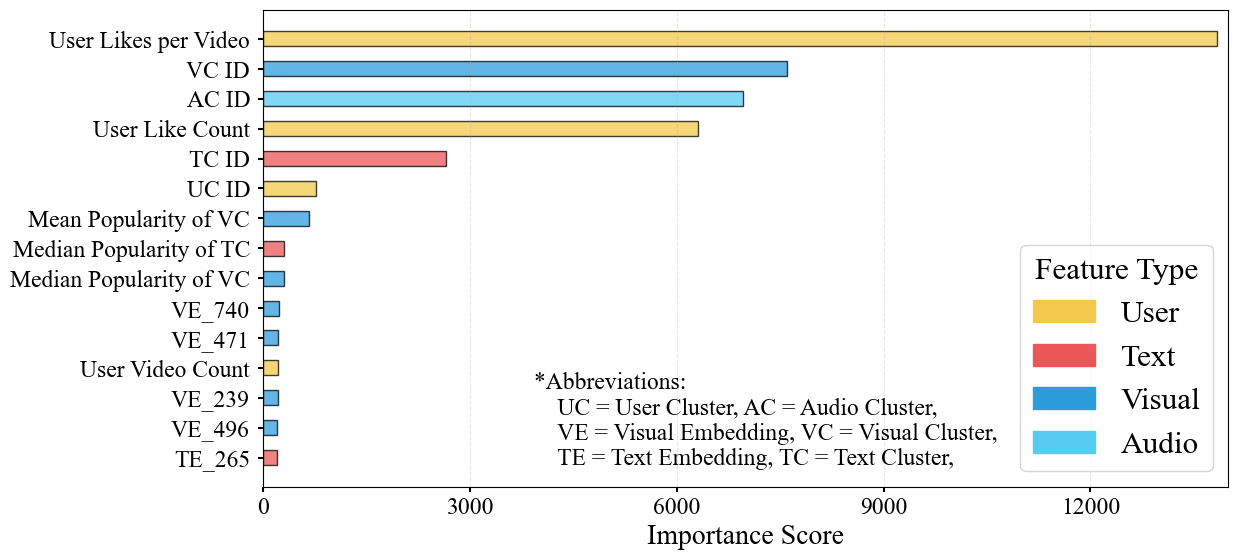
Figure 3: Feature importance analysis across different modalities.
Discussion
The AMCFG framework's dual-anchoring strategy embraces both statistical and semantic dimensions for robust prediction outcomes. The results emphasize the importance of incorporating high-level semantic understanding alongside raw multi-modal features to mitigate temporal prediction drift. This aligns with broader machine learning methodologies that leverage multi-scale feature representations to enhance model robustness.
By demonstrating the effectiveness of a framework rooted in TTA principles, this paper provides insights into cross-domain applicability of these adaptation techniques. This paves the way for future research targeting further generalization of TTA methods beyond spatial domain challenges, potentially addressing a wider range of dynamic predictive tasks.
Conclusion
The AMCFG framework presents a novel approach to addressing prediction drift in social media popularity prediction. By employing a dual-anchoring mechanism incorporating statistical and semantic patterns, the framework achieves significant performance improvements, ensuring stable and accurate predictions over time. This research opens up new avenues for adapting TTA-inspired strategies to non-visual temporal domain challenges, underscoring the potential for further advancements in AI and predictive analytics.