- The paper introduces a reinforced co-training framework that incorporates Q-learning to adaptively select high-quality unlabeled data.
- It mitigates sampling bias and myopic sample selection by using a performance-driven reward system based on classifier improvements.
- Experimental results on clickbait detection and text classification show enhanced precision and robust model stability.
Reinforced Co-Training
Introduction
The paper "Reinforced Co-Training" addresses the intrinsic limitations of conventional co-training methodologies by leveraging a reinforcement learning framework. Co-training is a semi-supervised learning strategy, utilizing abundant unlabeled data to augment learning from a limited labeled dataset. This paper innovatively combines Q-learning with co-training to adaptively select unlabeled samples, thereby mitigating the issues of sampling bias and inadequate exploration inherent in traditional co-training methods.
Co-Training Challenges
Standard co-training methods face two predominant issues: sampling bias and myopic sample selection. Random sampling from the unlabeled pool often introduces bias, shifting the model's focus inadvertently towards a non-representative data distribution, as illustrated in Figure 1. Moreover, reliance on high-confidence selections could lead to minimal training gain as they do not challenge the model with tough, boundary-level examples, leading to a narrow and potentially suboptimal decision boundary.
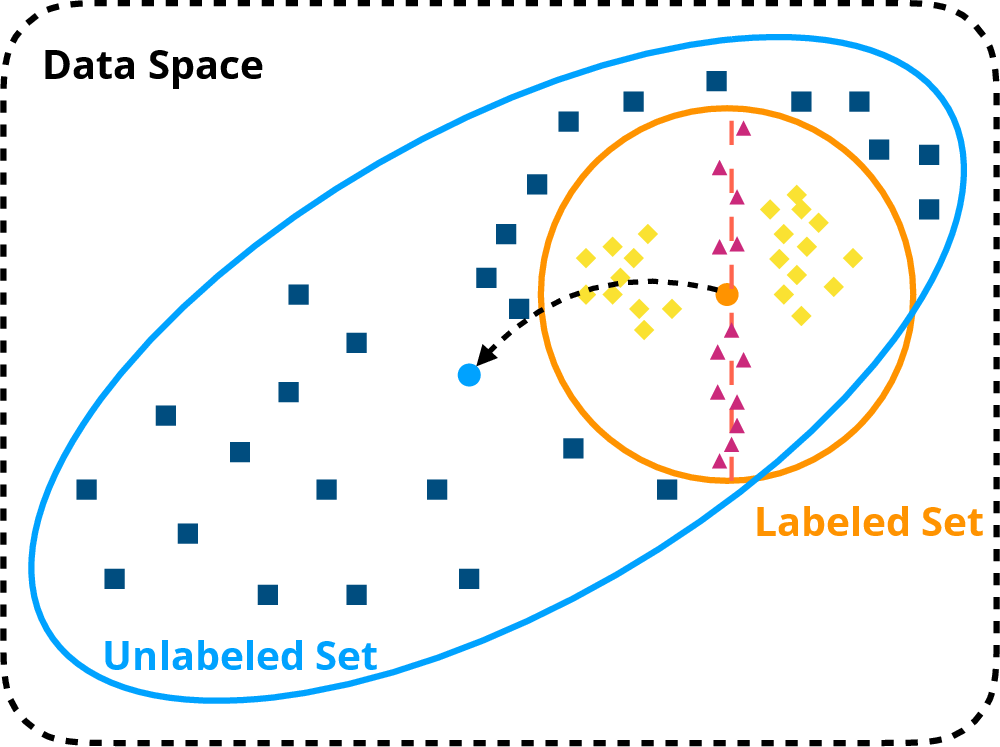
Figure 1: Illustration of sample-selection issues in co-training methods. (1) Randomly sampled unlabeled examples (Box) will result in high sampling bias, which will cause bias shift towards the unlabeled dataset (←). (2) High-confidence examples (Diamond) will contribute little during the model training, especially for discriminating the boundary examples (triangle), resulting in myopic trained models.
Reinforced Co-Training Framework
The proposed framework integrates Q-learning to dynamically formulate a data selection policy for unlabeled samples. The workflow incorporates a Q-agent to make sequential decisions based on a learned policy that optimizes a performance-driven reward system. This process aims to select a high-quality, informative subset of unlabeled samples for augmentation.
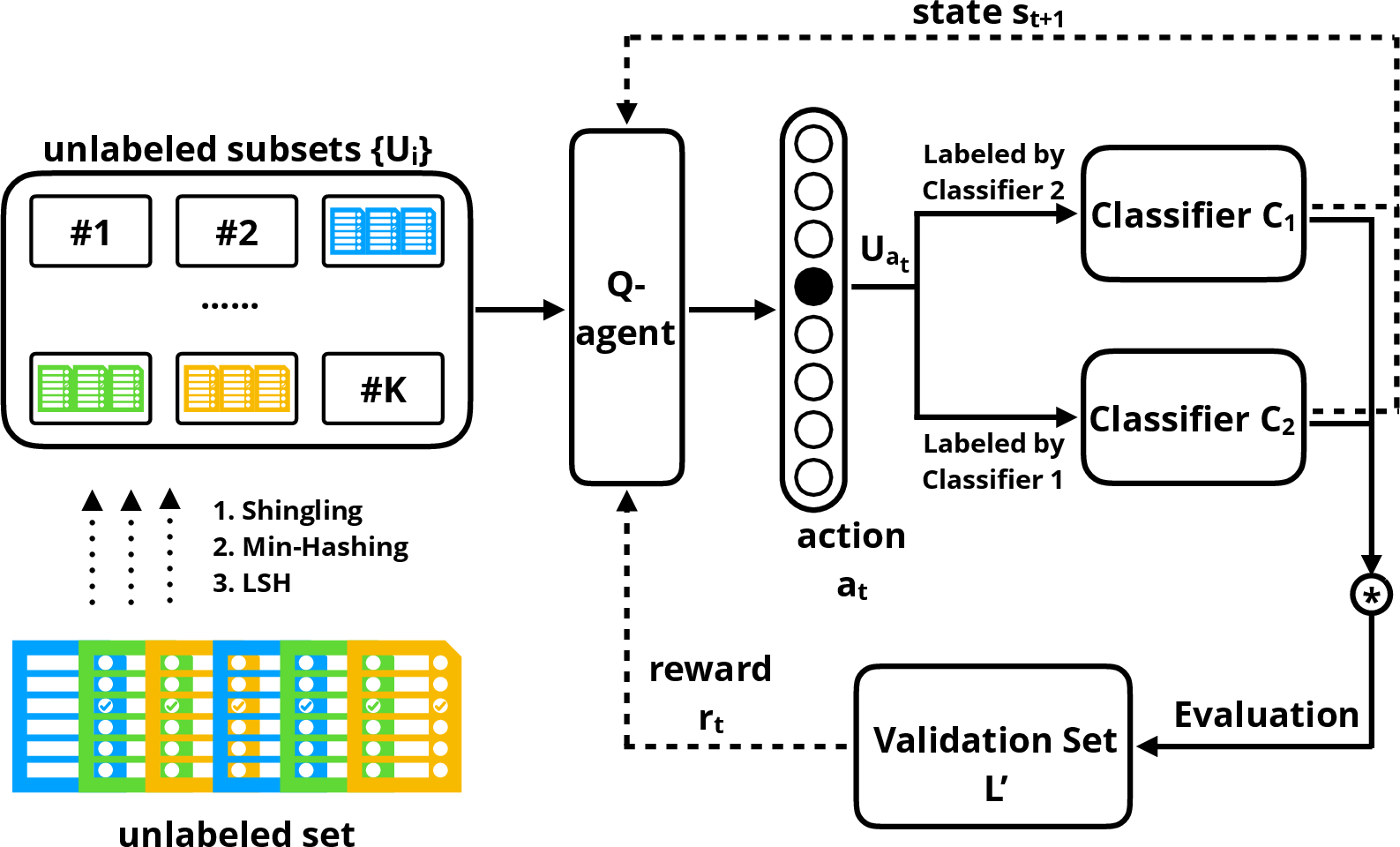
Figure 2: The Reinforced Co-Training framework.
The Q-agent calculates states by analyzing the classifier's probability distributions on representative samples for each data batch and chooses actions that maximize a future reward function. Notably, the rewards are computed based on classifier performance improvements on a separate validation set.
Implementation and Experimentation
Implementing the framework involves partitioning the unlabeled dataset using methods such as Jaccard similarity and hashing techniques to manage computational resources efficiently. At each iteration, two classifiers are updated based on pseudo-labeling by the other classifier, reminiscent of conventional co-training strategies but refined through the RL-enhanced process.
For experimentation, the methodology was evaluated on clickbait detection and generic text classification tasks. Reinforced Co-Training's performance was notably superior to conventional co-training and other semi-supervised baselines, demonstrating robust classifiers and a reduction in sampling bias.
Numerical Results
In numerical evaluation, Reinforced Co-Training achieved higher accuracy metrics on both experimental datasets. For clickbait detection, the method achieved a precision of 0.709, surpassing other techniques significantly.
Algorithm Robustness & Stability
The adaptability and stability of the learned policy were validated by re-training on various reshuffled training partitions. This robustness test supported the consistency and reliability of the Q-agent's policy choices across different sample distributions, affirming the generalizable nature of the approach.
Conclusion
Reinforced Co-Training advances the co-training paradigm by autonomously adapting data selection via RL, addressing limitations of static, confidence-driven sample selection strategies. Future prospects include extending this RL framework to other domains of semi-supervised learning and incorporating multi-agent environments for enriched collaborative learning scenarios.