- The paper introduces a dual-reward framework combining semantic and temporal rewards to improve video-specific reasoning in VideoLLMs.
- It utilizes the GRPO algorithm and variance-aware data selection to enhance reinforcement learning tuning efficiency and sample quality.
- Experiments on VideoQA and temporal grounding tasks demonstrate significant performance gains over traditional fine-tuning approaches.
Reinforcement Learning Tuning for VideoLLMs: Reward Design and Data Efficiency
Introduction
The paper investigates the application of Reinforcement Learning Tuning (RLT) to improve the reasoning capabilities of Multimodal LLMs (MLLMs) in video understanding tasks. By leveraging the Group Relative Policy Optimization (GRPO) algorithm, a dual-reward framework is proposed targeting semantic and temporal reasoning subtasks. The research highlights necessary enhancements in reward design and data selection strategies to achieve more effective video-specific learning.
Reward Design and Optimization
The dual-reward system combines discrete and continuous rewards to enhance semantic and temporal reasoning:
- Semantic Reward: A discrete reward aligns the VideoLLM's semantic understanding with task-specific correctness via Multi-Choice Video Question Answering (MC-VQA), transforming open-ended reasoning into a classification problem.
- Temporal Reward: A continuous reward based on the temporal Intersection over Union (IoU) is applied to temporal grounding tasks to improve alignment and precision.
These rewards provide structured supervision, guiding VideoLLMs through both high-level semantic comprehension and fine-grained temporal localization.
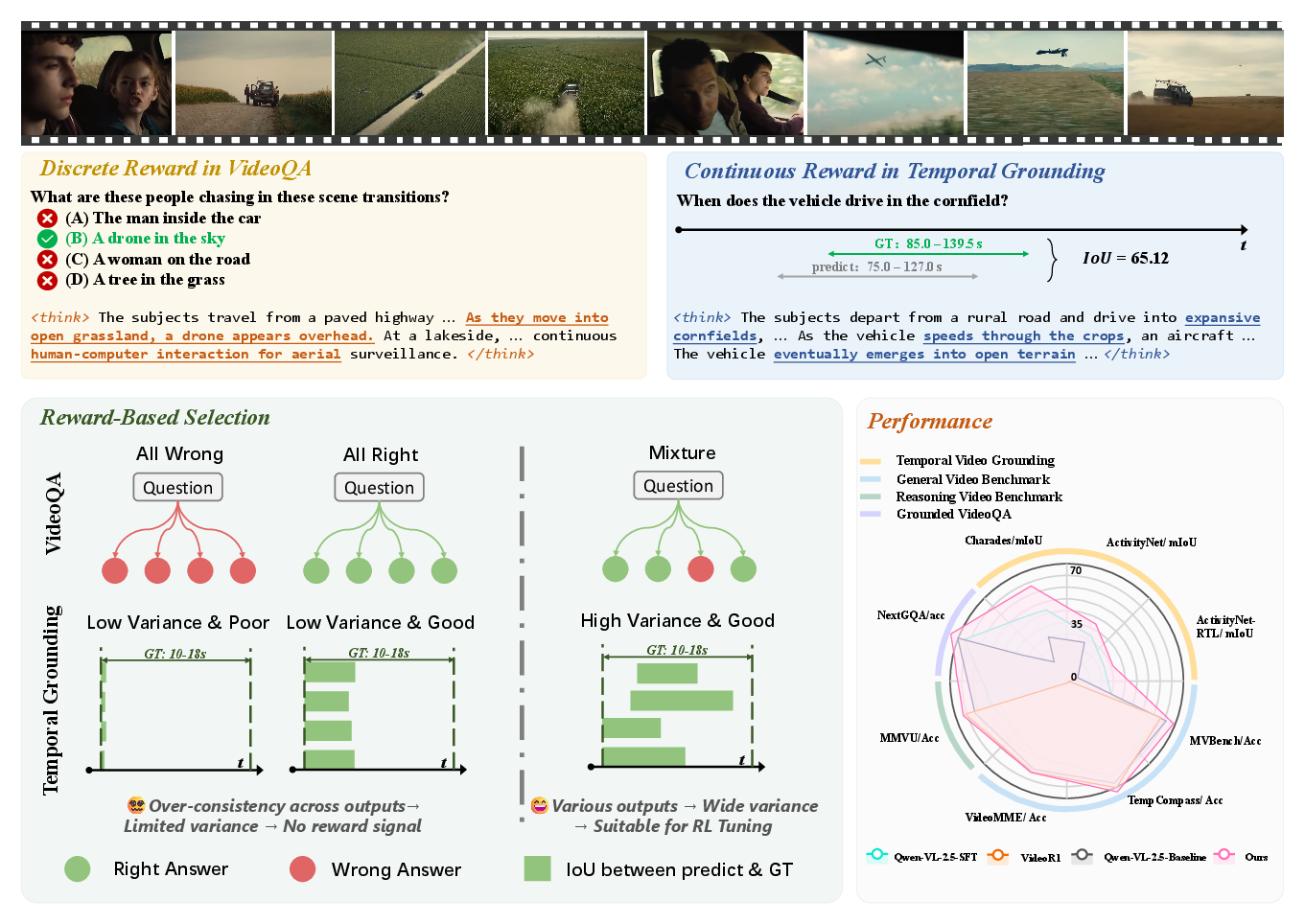
Figure 1: Overview of our reward-based framework for post-training on video understanding tasks.
Integration with GRPO
GRPO is utilized to optimize preference-driven learning without explicit value functions. The incorporation of GRPO within this reward framework leverages relative rankings of sampled outputs to guide optimization, thus simplifying the implementation and enhancing interpretability.
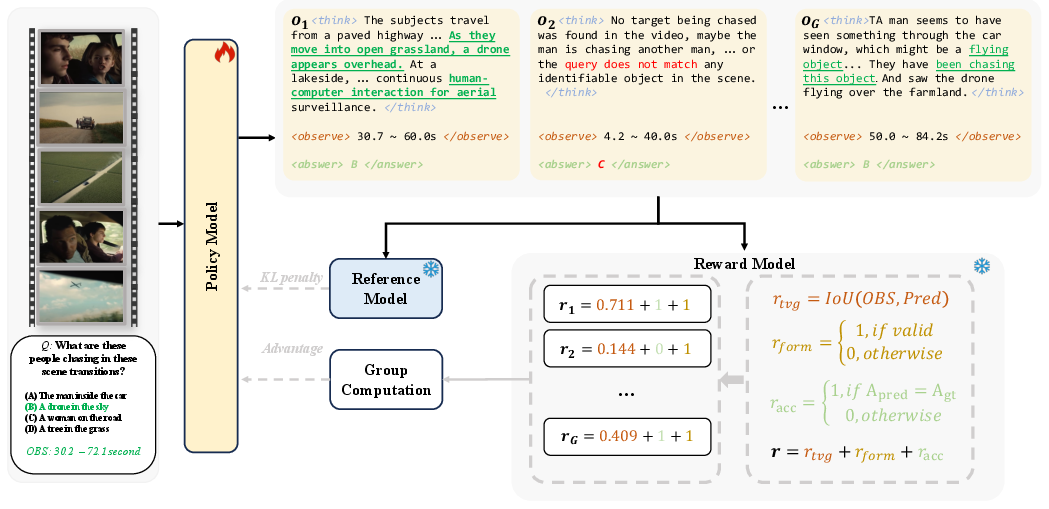
Figure 2: Overview of our training framework using GRPO-based RLT with task-specific rewards.
Data Efficiency and Selection Strategy
Variance-Aware Data Selection
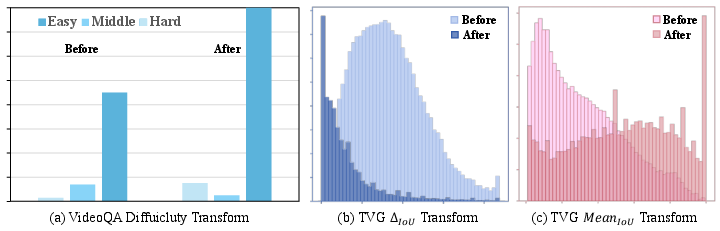
The variance-aware data selection strategy identifies effective samples for GRPO-based fine-tuning by monitoring behavioral variance among repeated inferences. Samples showing high variance are prioritized, ensuring that learning signals are strong and informative. This process enhances both training efficiency and sample quality.
Dataset Construction
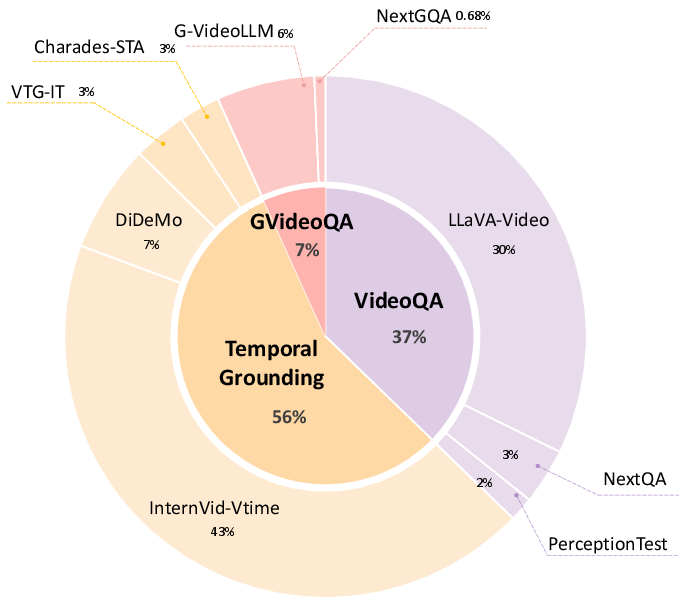
The authors constructed two datasets, Temporal-RLT-Full-490k and Temporal-RLT-32k, tailored for efficiency:
Experimentation and Results
Through comprehensive experiments across tasks such as VideoQA, Temporal Video Grounding, and Grounded VideoQA, the framework demonstrated superior performance over existing baselines, including supervised fine-tuning and RLT methods.
Conclusion
The proposed RLT framework, enriched with dual-reward design and advanced data selection, successfully improves the video-specific reasoning capabilities of VideoLLMs. This research underscores the importance of effective reward design and data efficiency, paving the way for future developments in video understanding using reinforcement learning strategies.
Limitations and Future Work
The study did not explore the generation of high-quality, fine-grained thinking traces for structured reasoning enhancement. Future research directions may include the integration of such supervision into RLT frameworks, potentially elevating video reasoning performance even further. Additionally, exploring more advanced RL methods tailored to specific subtasks in video understanding could yield further improvements.