- The paper presents a data-centric analysis using RLVR to evaluate multi-domain reasoning, showing both synergy and trade-offs between domains.
- The study employs GRPO with the Qwen-2.5-7B model to quantify in-domain gains and negative cross-domain effects among math, code, and puzzles.
- It highlights the critical role of template consistency and adaptive reward design in achieving robust and generalizable performance.
Data-Centric Analysis of Multi-Domain Reasoning in RLVR for LLMs
Introduction
This paper presents a comprehensive empirical study of multi-domain reasoning in LLMs under the Reinforcement Learning with Verifiable Rewards (RLVR) paradigm. The investigation is data-centric, focusing on the interplay between mathematical reasoning, code generation, and logical puzzle solving. The authors employ the Group Relative Policy Optimization (GRPO) algorithm and the Qwen-2.5-7B model family to systematically analyze in-domain and cross-domain effects, the impact of supervised fine-tuning (SFT), curriculum learning, reward design, and language-specific factors. The study provides nuanced insights into how domain-specific and cross-domain data influence both specialized and generalizable reasoning capabilities in LLMs.
Experimental Framework and Methodology
The experimental setup is rigorous, leveraging curated datasets for each domain: DeepScaleR and CountDown for math, CodeR1-12k for code, and Knights-and-Knaves (KK) and Logic Puzzle Baron (LPB) for puzzles. All datasets are normalized in size to control for data scale effects. The RLVR training is conducted using GRPO, which eschews a value model in favor of group-based advantage estimation, and all experiments are run on 8×A100 GPUs. Evaluation spans standard benchmarks: MATH500, AIME24, CountDown, HumanEval, MBPP, KK, and ZebraLogicBench, with strict control over prompt templates and few-shot settings to ensure reproducibility.
Single-Domain RLVR: In-Domain Gains and Cross-Domain Trade-offs
Mathematical Reasoning
RLVR on math data yields substantial in-domain improvements, with MATH500 accuracy increasing by up to 19.6 points and CountDown accuracy by over 75 points for the base model. However, this comes at the cost of degraded code generation performance, indicating a negative transfer from math to code. Notably, math training enhances puzzle-solving ability, suggesting shared logical structures between math and puzzles.
Code Generation
RLVR on code data (CodeR1-12k) significantly boosts HumanEval and MBPP scores for both base and instruct models. The instruct model, benefiting from SFT, consistently outperforms the base model. However, code RLVR has mixed cross-domain effects: it improves OOD performance for instruct models but constrains the base model's flexibility, leading to format errors in non-code tasks.
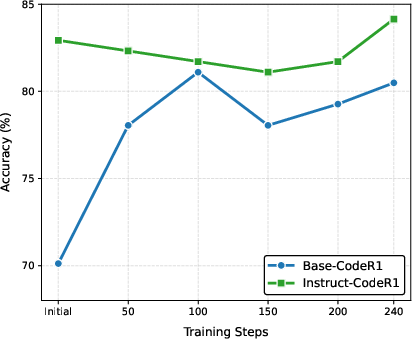
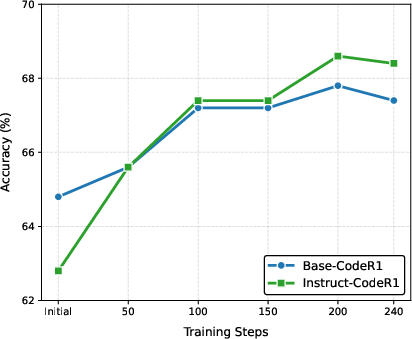
Figure 1: Performance on HumanEval, demonstrating substantial gains from code RLVR, especially for instruct models.
Logical Puzzles
Puzzle-specific RLVR (KK, LPB) dramatically increases in-domain accuracy (e.g., KK accuracy up to 99.14 for instruct models). Puzzle RLVR also transfers positively to math tasks but has inconsistent or negative effects on code generation, especially when training is dominated by fixed-format puzzle data.
Multi-Domain RLVR: Synergy, Conflict, and Generalization
Dual-Domain Combinations
Pairwise domain combinations reveal non-trivial interactions. Math+Puzzle training yields synergistic improvements in math and puzzle tasks but degrades code performance, highlighting the challenge of balancing structurally divergent domains. Puzzle+Code achieves the best overall dual-domain performance, indicating that code and puzzle data can be mutually reinforcing under certain conditions.
Triple-Domain Training
Incorporating all three domains further improves overall performance and task balance, with the highest aggregate accuracy observed in the triple-domain setting. However, negative transfer persists for highly specialized tasks (e.g., puzzle accuracy drops compared to puzzle-only training), underscoring the specialization-generalization trade-off.
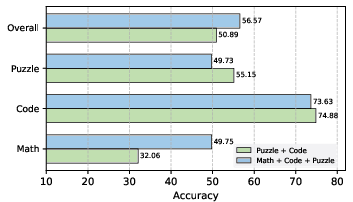
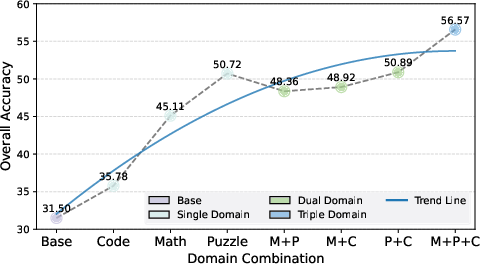
Figure 2: Performance comparison of triple-domain and optimal dual-domain data, illustrating the benefits and trade-offs of broader domain coverage.
Template Consistency and Robustness
A critical finding is the extreme sensitivity of RLVR-trained models to prompt template alignment. Mismatched templates between training and evaluation can cause severe performance degradation across all domains, particularly for complex tasks like KK and ZebraLogicBench. This exposes a significant robustness gap in current RLVR approaches.
Curriculum Learning and Policy Refresh
Curriculum learning, implemented via progressive difficulty stratification in the KK dataset, raises the upper bound of puzzle-solving performance. The introduction of a policy refresh strategy—periodically updating the reference model and resetting the optimizer—further accelerates convergence and improves final accuracy, nearly achieving perfect scores.
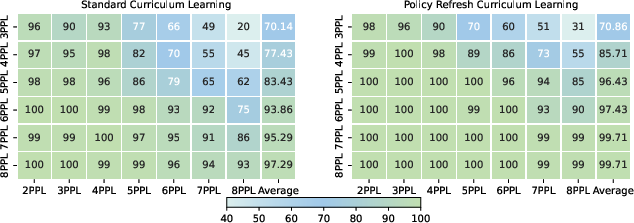
Figure 3: Model performance on the KK dataset with different curriculum settings, showing the efficacy of curriculum learning and policy refresh.
Reward Design: Task-Dependent Efficacy
Reward scheme selection is shown to be highly task-dependent. Binary rewards are optimal for tasks with low solution sparsity (e.g., KK), while partial and rescaled rewards are necessary for harder, sparser tasks (e.g., LPB). The study highlights the limitations of response-level partial rewards and suggests that finer-grained, cell-level reward signals are needed for further progress.
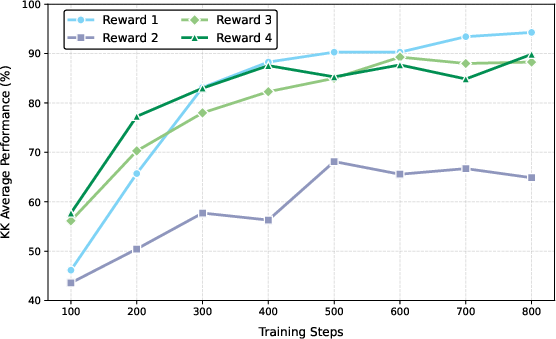
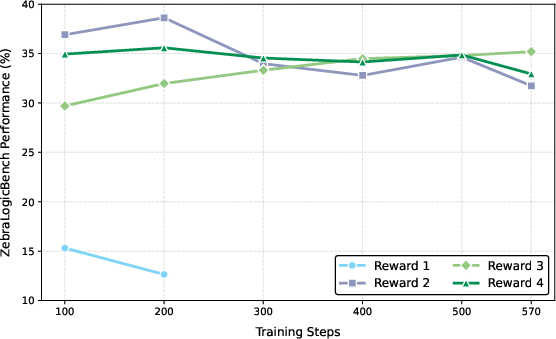
Figure 4: Performance on KK, comparing the impact of different reward configurations.
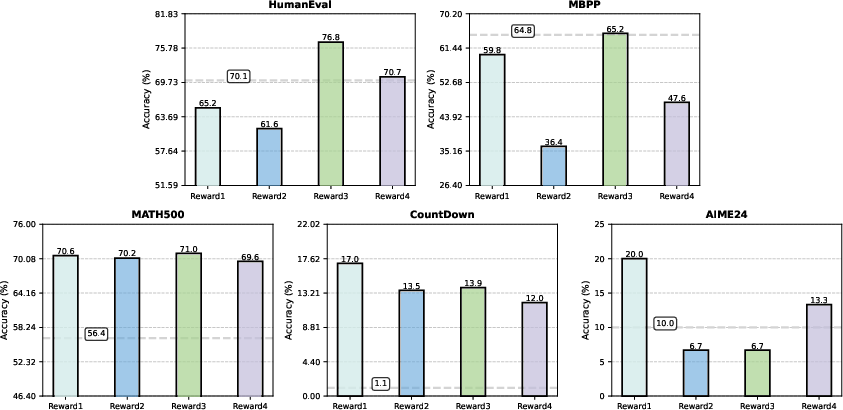
Figure 5: KK-impact of reward configurations (base model shown with dashed lines), illustrating the sensitivity to reward design.
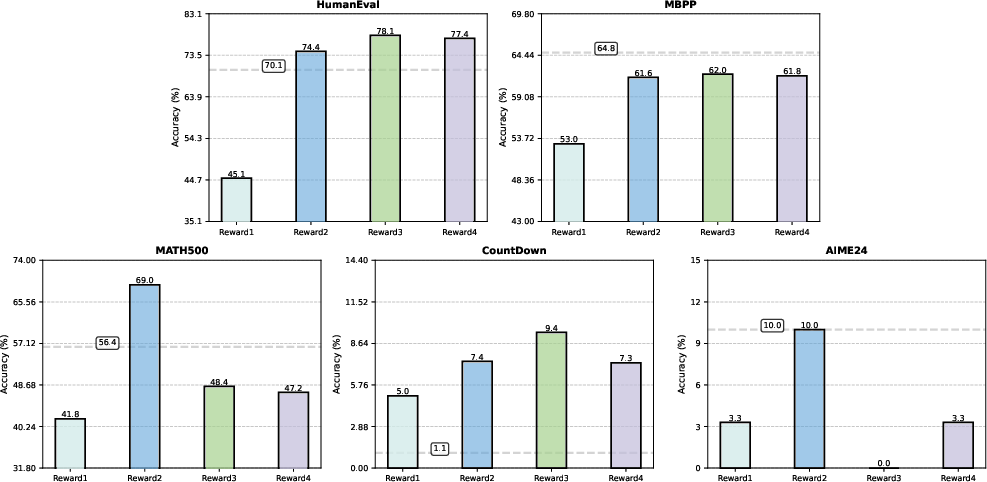
Figure 6: LPB-impact of reward configurations (base model shown with dashed lines), showing the necessity of partial and rescaled rewards for sparse tasks.
Language Sensitivity
RLVR-trained models exhibit a consistent performance gap when trained in Chinese versus English, even with identical data and reward enforcement. This highlights a limitation in current RLVR methods for cross-lingual generalization in complex reasoning tasks.
Implications and Future Directions
The study provides several actionable insights for RLVR-based LLM post-training:
- Domain synergy is not universal: While math and puzzle data are mutually supportive, code data can introduce both positive and negative cross-domain effects depending on model initialization and SFT.
- Multi-domain training enhances generalization and stability: Broader domain coverage improves aggregate performance and mitigates catastrophic forgetting, but may reduce peak specialization.
- Template alignment is critical: Robustness to prompt format remains a major challenge for RLVR-trained models.
- Reward design must be task-adaptive: No single reward scheme suffices across all domains; future work should explore more granular, context-sensitive reward mechanisms.
- Language remains a bottleneck: Cross-lingual RLVR requires further methodological advances.
Conclusion
This work delivers a systematic, data-centric analysis of multi-domain reasoning in LLMs under RLVR, elucidating the complex interactions between domain-specific and cross-domain training, the importance of SFT, curriculum learning, reward design, and language effects. The findings inform best practices for constructing robust, generalizable reasoning models and highlight open challenges in template robustness, reward granularity, and cross-lingual transfer. Future research should extend this analysis to additional domains (e.g., science, general reasoning), larger model families, and more sophisticated reward and curriculum strategies to further advance the state of multi-domain reasoning in LLMs.