- The paper introduces Reasoning Gym, a library that generates dynamic, procedurally generated RL tasks with verifiable rewards for adjustable difficulty.
- The study employs curriculum learning and zero-shot evaluations to demonstrate that reasoning-specific models outperform general-purpose baselines.
- Experiments reveal that intra-domain and cross-domain generalization enable models trained on algorithmic tasks to excel in diverse reasoning challenges like algebra and logic.
REASONING GYM: Reasoning Environments for Reinforcement Learning with Verifiable Rewards
The paper "Reasoning Gym: Reasoning Environments for Reinforcement Learning with Verifiable Rewards" (2505.24760) introduces Reasoning Gym (\rg), a robust library tailored for reinforcement learning (RL) that offers verifiable rewards. The library stands out by providing adjustable complexity in its task environments, thus allowing models to be trained across a range of difficulties without depending on static datasets which are prone to challenges like overfitting.
Introduction to Reasoning Gym
Reasoning Gym is crafted to address a crucial bottleneck in reinforcement learning of reasoning tasks: the availability of scalable and dynamic training data. Traditional datasets are often fixed and limited, posing significant challenges as models can easily memorize solutions rather than learning generalized reasoning skills. \rg distinguishes itself by introducing procedurally generated environments that yield a vast array of tasks with controllable difficulty settings across domains such as algebra, logic, and various games.
Examples of \rg tasks are illustrated in Figure 1, underscoring the diversity of challenges presented within this framework.
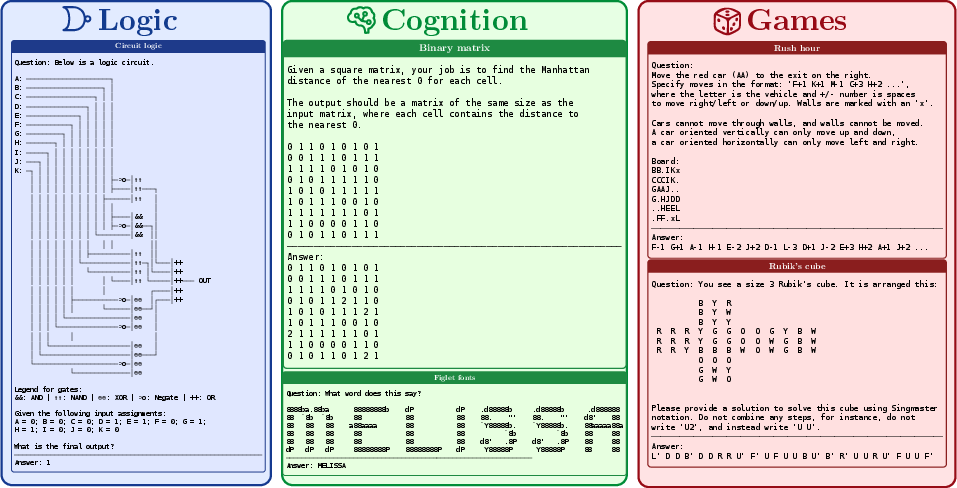
Figure 1: Example \rg tasks from three categories.
An evaluation of current state-of-the-art models with zero-shot tasks within \rg reveals significant areas where performance varies greatly, especially where tasks increase in complexity. Interestingly, reasoning-oriented models like o3-mini and DeepSeek-R1 exhibit pronounced advantages over general-purpose models, both in easy and hard task settings.
The analysis of zero-shot performance is depicted in Figure 2, reflecting these disparities.
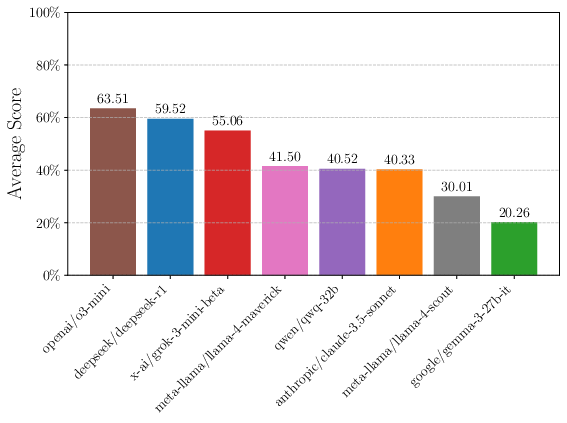
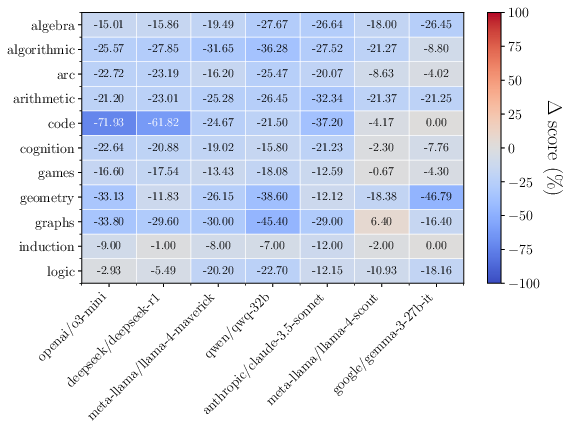
Figure 2: Zero-shot performance of frontier LLMs.
This performance disparity highlights that reasoning models have more broadly applicable skills as opposed to non-reasoning baselines. Nevertheless, the performance sharply declines in difficult configurations such as long-horizon puzzles (Figure 3), indicating the models' need for further enhancement in systematic reasoning capabilities.
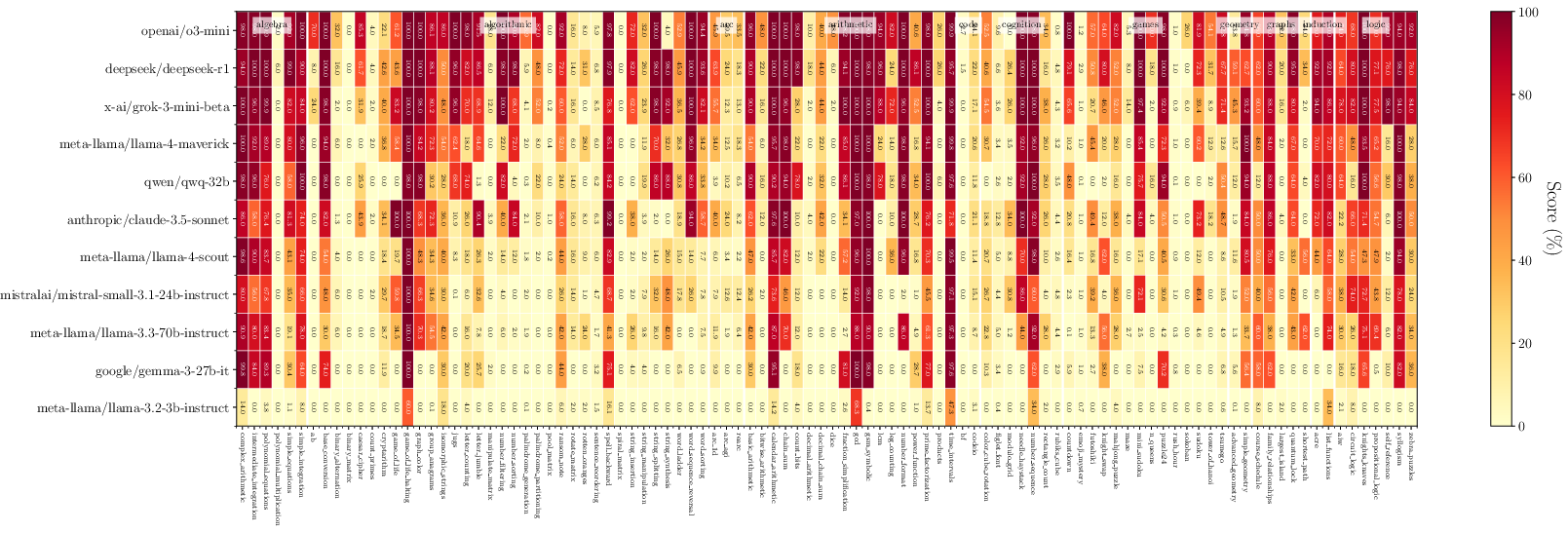
Figure 3: Performance on hard settings decreases substantially for complex reasoning tasks.
Intra-Domain and Cross-Domain Generalization
A key strength of RLVR-trained models on \rg tasks is their ability to generalize across tasks within the same reasoning domain and even to different domains, showcasing both intra-domain and cross-domain generalization capabilities. The intra-domain generalization (Figure 4) shows significant reward improvements, which remain consistent across various reasoning task categories.

Figure 4: Rewards of Intra-Domain Generalization RL.
Moreover, cross-domain generalization experiments demonstrate that skills learned in algorithmic tasks can improve performance in unrelated areas such as algebra or geometry, as illustrated in Figure 5.
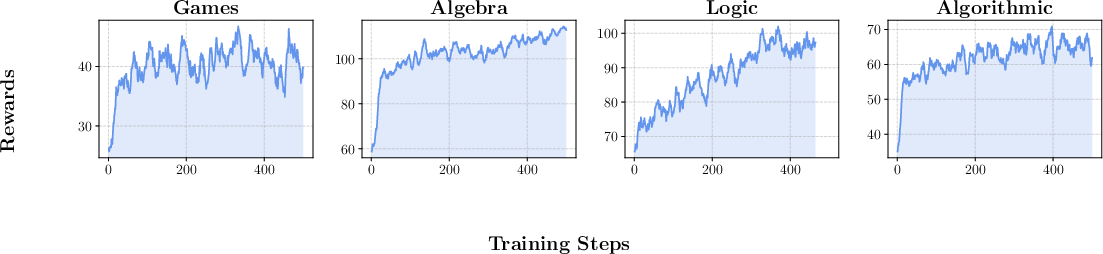
Figure 5: Rewards of Cross-Domain Generalization RL.
Curriculum Learning in Reinforcement Learning
The curriculum learning approach within \rg is shown to yield better results compared to non-curriculum settings. By starting with simpler tasks and progressively increasing complexity based on performance thresholds, models can learn more effectively. Figure 6 highlights the reward dynamics between curriculum and regular training regimes.
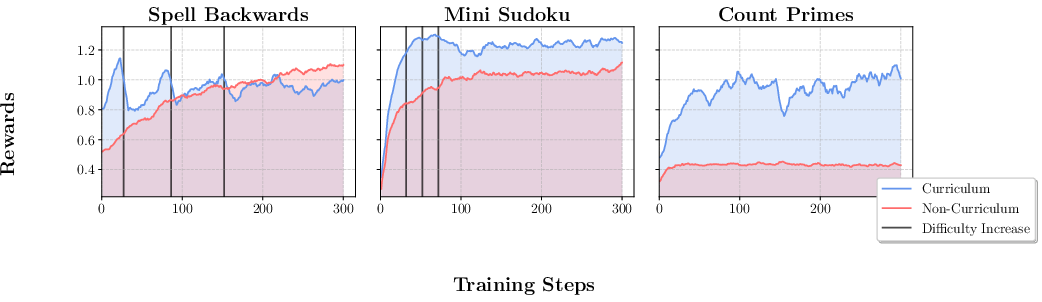
Figure 6: Rewards for the Curriculum Learning experiments; curriculum learning facilitates better adaptation to task difficulty increases.
Conclusion
Reasoning Gym provides an innovative and essential resource for advancing reinforcement learning-based reasoning models. Its ability to generate diverse and dynamic tasks effectively removes the data constraints faced by previous static benchmarks. The results demonstrate that procedural generation and verifiable rewards not only facilitate robust training but also significantly enhance generalization across and within reasoning domains. As \rg becomes part of the open-source ecosystem, it will enable broader investigation into model reasoning, curriculum learning strategies, and the development of more sophisticated AI reasoning systems.