- The paper introduces Enigmata, a framework that scales logical reasoning in LLMs by integrating synthetic, verifiable puzzles with multi-stage reinforcement learning.
- It employs a diverse dataset across 7 puzzle categories using generator-verifier pairs to enable robust evaluation and adaptive training.
- Experiments demonstrate superior performance on benchmarks, validating enhanced model generalization and improved math reasoning capabilities.
Overview
The paper introduces Enigmata, a suite designed to enhance logical reasoning in LLMs through the use of synthetic, verifiable puzzles. Enigmata aims to address the limitations of existing models in handling complex puzzle tasks, a domain where human-like reasoning is expected. The primary components of Enigmata include a diverse puzzle dataset and a series of training strategies tailored to improve puzzle-solving capabilities in LLMs.
Puzzle Dataset: Enigmata-Data
Enigmata-Data consists of 36 distinct tasks organized into seven categories: Crypto, Arithmetic, Logic, Grid, Graph, Search, and Sequential Puzzles. Each task features a generator-verifier pair that allows for scalable data generation and automatic evaluations. This generator-verifier setup facilitates seamless integration with Reinforcement Learning with Verifiable Rewards (RLVR) paradigms, enabling structured reinforcement learning.
Puzzle Categories
- Crypto Puzzle: Evaluates cryptography skills, requiring models to decode encrypted messages or challenges without explicit keys.
- Arithmetic Puzzle: Tests numerical reasoning through problems that combine arithmetic operations with constraints.
- Logic Puzzle: Enhances deductive reasoning, requiring models to infer logical conclusions from given premises.
- Grid Puzzle: Challenges spatial reasoning by solving structured grids like Sudoku and Skyscraper.
- Graph Puzzle: Involves reasoning about nodes and paths in graph structures to solve Hamiltonian paths and cycles.
- Search Puzzle: Emphasizes efficient exploration through state spaces governed by specific rules, exemplified by Minesweeper and Tic Tac Toe.
- Sequential Puzzle: Involves understanding and predicting sequences of steps, as seen in various arrangement puzzles.
Data Construction
Enigmata-Data construction involves three phases: tasks collection and design, development of auto-generators and verifiers, and difficulty control mechanics ensuring content adaptability based on model proficiency.
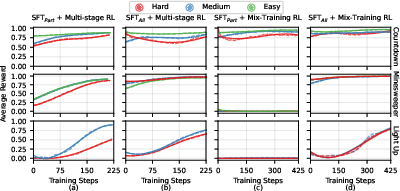
Figure 1: Learning curves across training approaches for representative puzzle tasks. Each row represents a different task, and each column represents a different training approach. The curves show how the average reward changes with training steps for different difficulty levels.
Training Recipe: Enigmata-Model
The Enigmata-Model employs two primary training phases: rejection fine-tuning and multi-task reinforcement learning. Rejection fine-tuning uses high-quality solutions for supervised pattern establishment, combining mathematics and puzzles to create a robust reasoning foundation.
Reinforcement Learning with Verifiable Puzzles
VC-PPO, a variant of Proximal Policy Optimization (PPO), is utilized for reinforcement learning, relying on automated verifiers to assign reward signals based on correctness immediately. This pipeline operates via strategic data mixing and sampling approaches, leveraging dynamic difficulty controls.
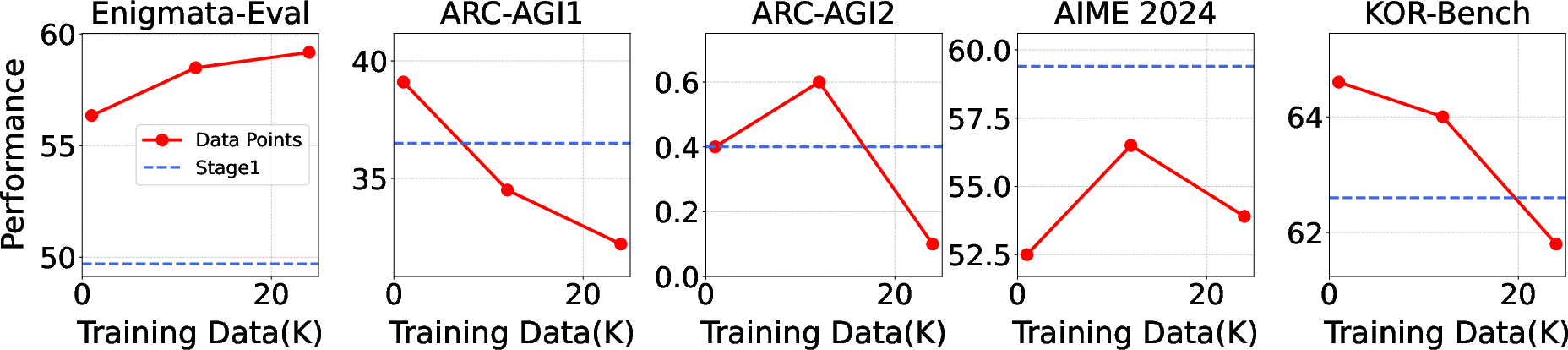
Figure 2: Impact of training data size in the second stage of Multi-stage Training on model performance across different benchmarks. The blue dashed line represents model performance after the first training stage, while the red solid line shows performance after the second stage.
Multi-task Training Approaches
Enigmata-Model explores two multi-task strategies:
- Mix-training RL: Incorporates diverse puzzle types simultaneously, yielding broad generalization and stability.
- Multi-stage RL: Applies a curriculum-based training, systematically developing skills before introducing new challenges, resulting in enhanced learning effectiveness.
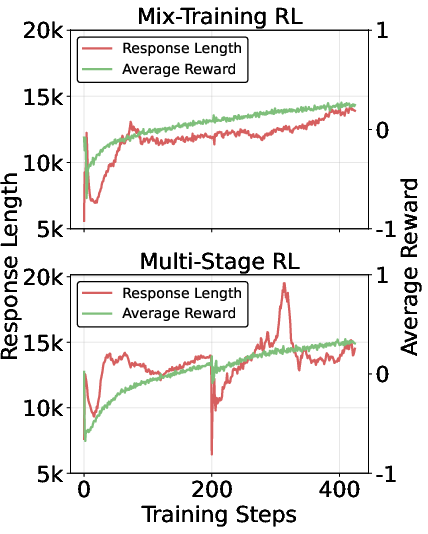
Figure 3: The response length and reward curves during Mix-Training RL and Multi-Stage RL training.
Experiments and Results
Evaluation on several benchmarks, including Enigmata-Eval, ARC-AGI 1 & 2, demonstrates the model's superior logical reasoning capabilities. Enigmata-Model surpasses state-of-the-art models across various puzzle classes, confirming its effectiveness in generalizing to unseen tasks without compromising math reasoning.
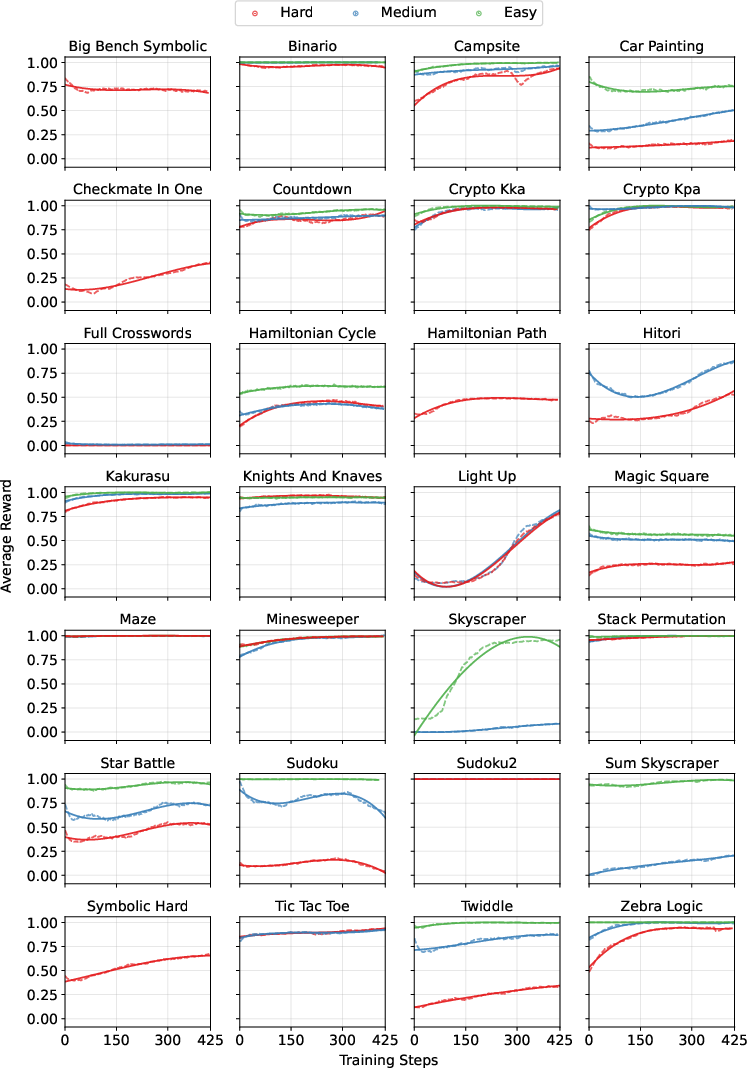
Figure 4: Reward curves for Qwen2.5-32B-Enigmata across all individual tasks during training. Each subplot represents a different puzzle task, with the x-axis showing training steps and the y-axis showing average reward. Colors indicate different difficulty levels: Easy (green), Medium (blue), and Hard (red).
Implications and Conclusion
The introduction of Enigmata provides a structured framework for advancing logical reasoning in LLMs, combining synthetic puzzle data with Reinforcement Learning with Verifiable Rewards. Its scalable design ensures broad applicability, not only enhancing puzzle-solving capabilities but also contributing to improved general reasoning performance across domains. Further research could explore expanding the puzzle categories and integrating multi-turn puzzles for richer logical evaluation.
Enigmata represents a significant step towards refining cognitive reasoning in LLMs, promoting robust analytical skills that align closer with human-like problem-solving abilities. It stands as a valuable asset for the community intent on pushing the boundaries of LLM intelligence and adaptability in complex scenarios.