Golden Goose: A Simple Trick to Synthesize Unlimited RLVR Tasks from Unverifiable Internet Text
Abstract: Reinforcement Learning with Verifiable Rewards (RLVR) has become a cornerstone for unlocking complex reasoning in LLMs. Yet, scaling up RL is bottlenecked by limited existing verifiable data, where improvements increasingly saturate over prolonged training. To overcome this, we propose Golden Goose, a simple trick to synthesize unlimited RLVR tasks from unverifiable internet text by constructing a multiple-choice question-answering version of the fill-in-the-middle task. Given a source text, we prompt an LLM to identify and mask key reasoning steps, then generate a set of diverse, plausible distractors. This enables us to leverage reasoning-rich unverifiable corpora typically excluded from prior RLVR data construction (e.g., science textbooks) to synthesize GooseReason-0.7M, a large-scale RLVR dataset with over 0.7 million tasks spanning mathematics, programming, and general scientific domains. Empirically, GooseReason effectively revives models saturated on existing RLVR data, yielding robust, sustained gains under continuous RL and achieving new state-of-the-art results for 1.5B and 4B-Instruct models across 15 diverse benchmarks. Finally, we deploy Golden Goose in a real-world setting, synthesizing RLVR tasks from raw FineWeb scrapes for the cybersecurity domain, where no prior RLVR data exists. Training Qwen3-4B-Instruct on the resulting data GooseReason-Cyber sets a new state-of-the-art in cybersecurity, surpassing a 7B domain-specialized model with extensive domain-specific pre-training and post-training. This highlights the potential of automatically scaling up RLVR data by exploiting abundant, reasoning-rich, unverifiable internet text.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper is about helping AI LLMs get better at tricky, step-by-step reasoning (like solving math problems or understanding science). A popular way to train these models is called Reinforcement Learning with Verifiable Rewards (RLVR), which means the model gets a clear “right or wrong” signal for each answer. The problem is there isn’t enough high-quality, automatically checkable training data, so models eventually hit a “plateau” and stop improving.
The authors introduce a simple idea they call “Golden Goose”: turn ordinary, hard-to-check internet text into unlimited, easy-to-check practice tasks. They do this by making multiple-choice “fill‑in‑the‑middle” questions that focus on the most important missing steps in a solution.
Objectives: What the researchers aimed to do
The paper sets out to:
- Create a simple, scalable way to turn regular text (like textbook explanations or forum solutions) into training tasks that are automatically checkable.
- Keep models improving even after they’ve “memorized” existing RLVR datasets.
- Cover more fields than just math and programming, including science and cybersecurity.
- Show that this synthetic data can boost both small and medium-sized models, and sometimes even beat larger, specialized models.
Methods: How the trick works (in everyday language)
Think of a solution as a story where a few key sentences explain the main idea. The method turns that story into a puzzle:
- Take a source text (for example, a math solution or a science explanation).
- Use a strong LLM to pick a short, crucial chunk of reasoning and replace it with [MASK]. That chunk is the “ground-truth” correct answer.
- Ask the LLM to create several “distractors” — wrong answers that look believable and have a similar style.
- Present everything as a multiple-choice question: the model sees the text-with-[MASK] and must choose the correct missing piece from the list.
This setup is perfect for RLVR because it gives a simple, automatic reward: if the model picks the right option, it gets a “win”; otherwise, it gets a “loss.” No human judge or complex testing is needed.
To make this work well on messy web text (like cybersecurity pages), they:
- First extract or summarize a clean, educational passage from the source.
- Filter out questions that are too easy for the student model.
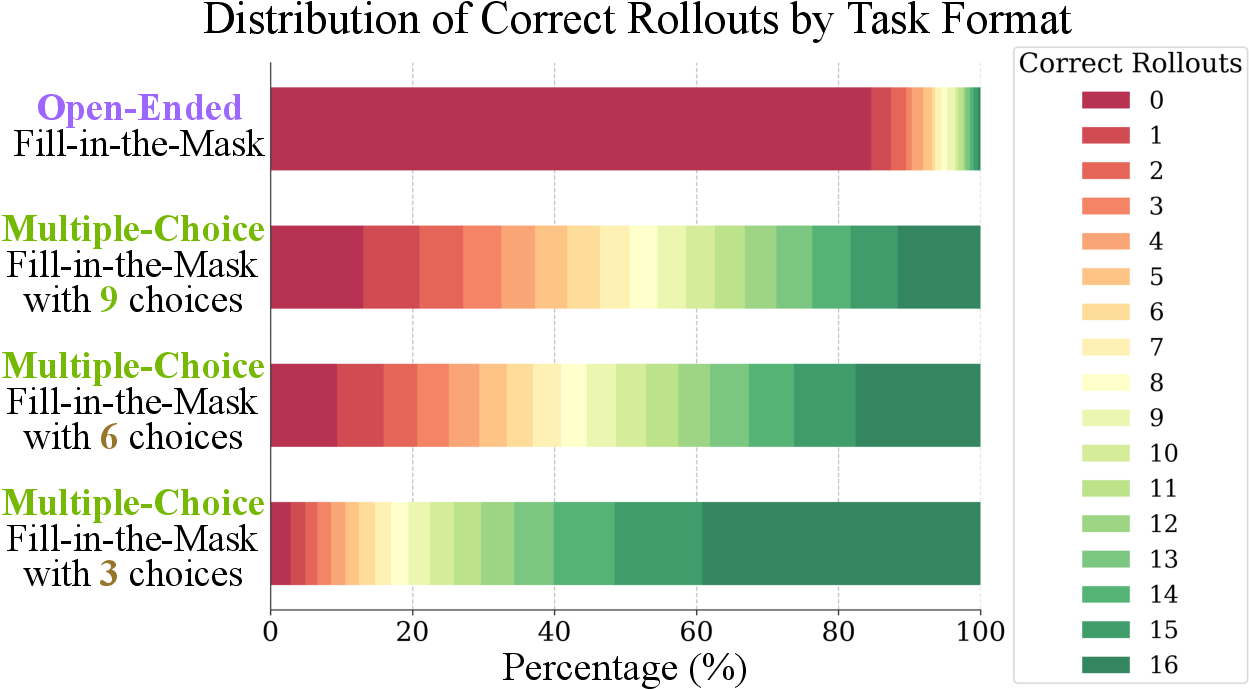
- Use enough options (about 9 choices) so the model can’t just eliminate the obviously wrong ones — it must actually reason.
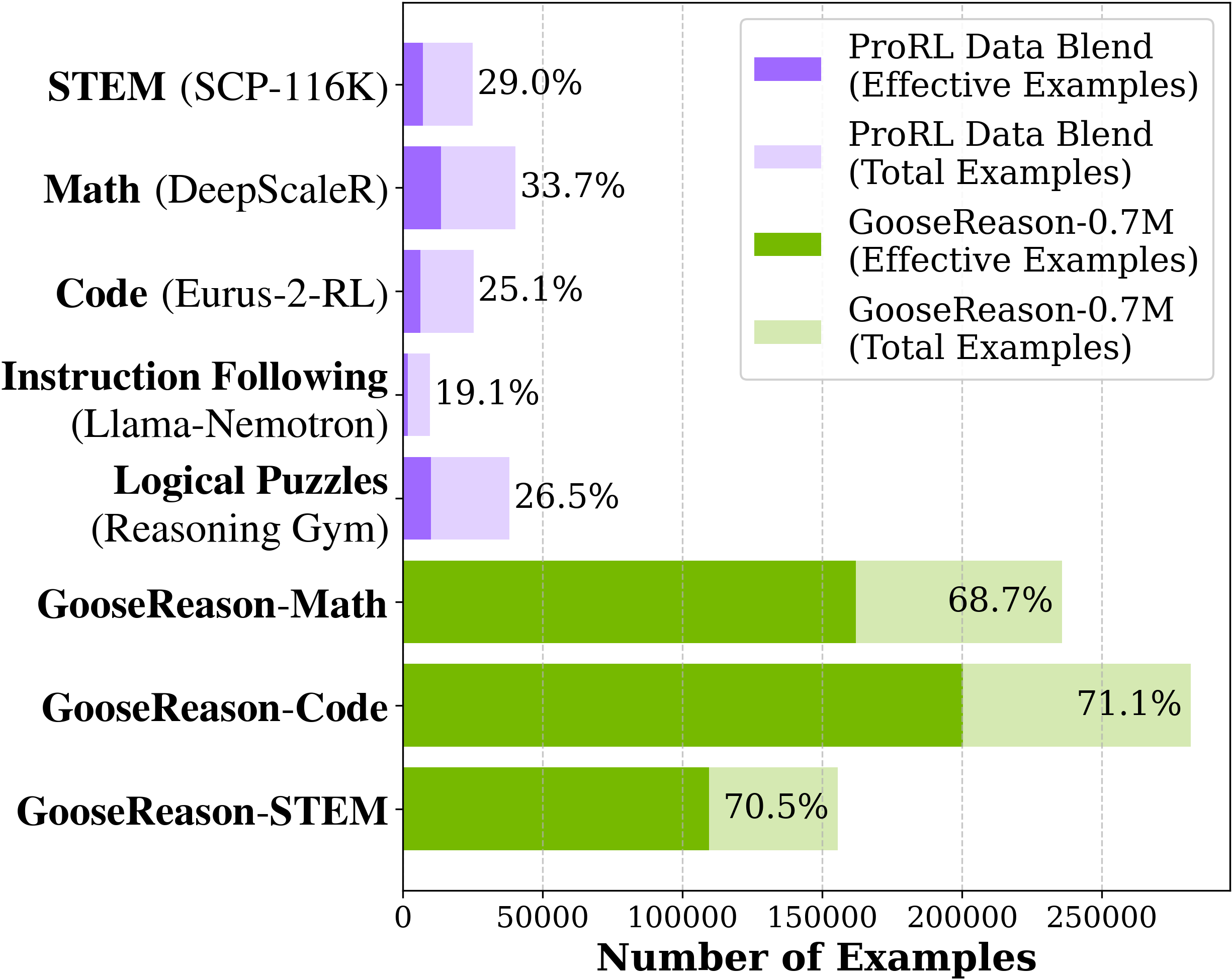
They used a very strong LLM to build these questions and released a large dataset, GooseReason-0.7M, with over 700,000 tasks across math, coding, and science. They also built GooseReason-Cyber (about 180,000 tasks) from cybersecurity web scrapes.
Main Findings: What they discovered and why it matters
Here are the key results the authors report:
- Breaking through training plateaus:
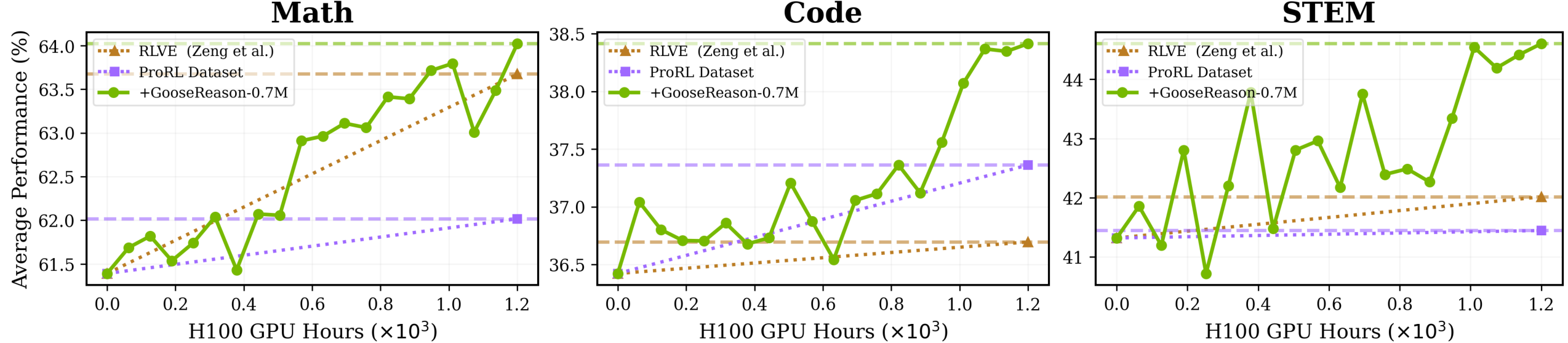
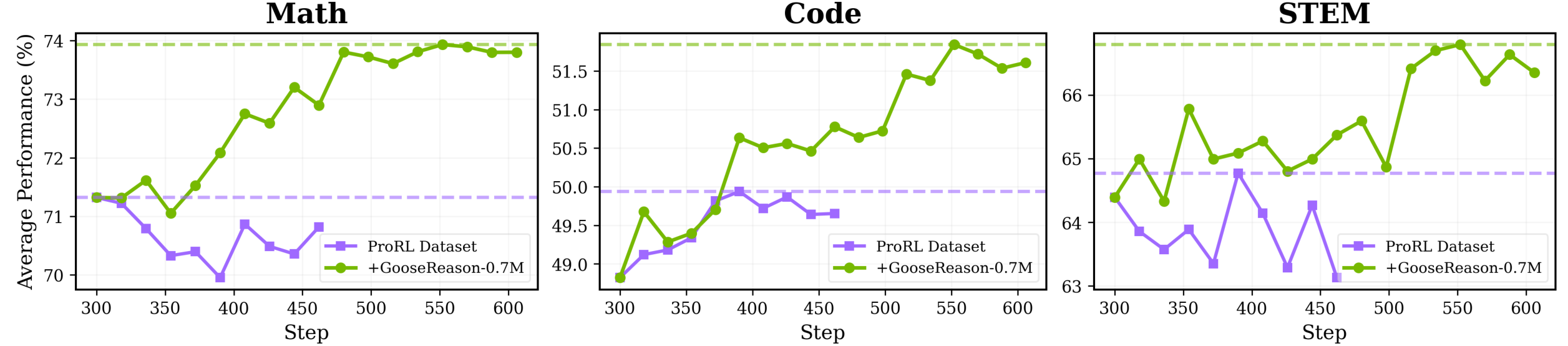
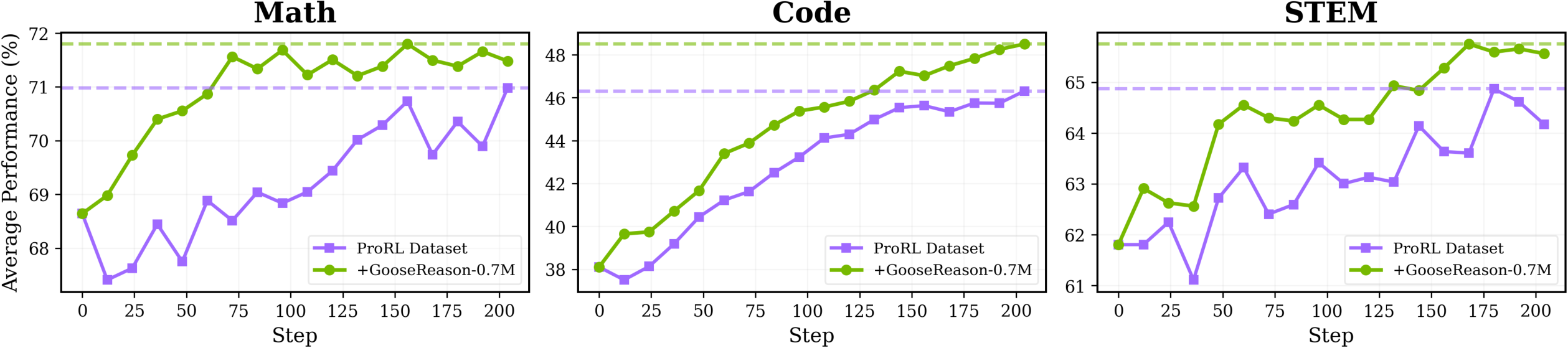
- Models that had stopped improving on existing RLVR data started getting better again when trained on GooseReason-0.7M.
- A strong 1.5B-parameter model and a 4B-parameter model both showed steady gains across 15 benchmarks (math, coding, STEM reasoning, and more).
- Bigger gains where data was scarce:
- STEM (science) saw the largest improvements because most RLVR data before was focused on math and code. The new method taps into textbook-like content that had been hard to use.
- Works even for stronger models:
- Larger base models tend to plateau faster. Golden Goose revived a 4B model that had started regressing, turning it into a new state-of-the-art among similar-sized “Instruct” models.
- Helps beyond the training format:
- Even though the training uses multiple-choice questions, the models improved on non-multiple-choice tasks. That suggests they learned general reasoning skills, not just test-taking tricks.
- More efficient training:
- Under the same training budget, adding GooseReason-0.7M led to better performance in fewer steps than using the old data alone.
- Real-world domain success (cybersecurity):
- They created GooseReason-Cyber from noisy web text and trained a 4B model for just 100 reinforcement steps.
- It beat a specialized 7B cybersecurity model that had lots of domain-specific training, showing this approach can unlock progress in niche areas where verified data is hard to get.
Implications: Why this could be a big deal
- Scaling reasoning training: This method turns huge amounts of “unverifiable” text (like explanations and solutions without test cases) into clean, checkable, multiple-choice tasks. That unlocks more data, so models can keep improving instead of plateauing.
- Stronger small and mid-sized models: With better training data, smaller models can compete with or beat larger ones in reasoning-heavy tasks.
- Broad domain coverage: Beyond math and code, the approach works on science and specialized areas like cybersecurity. It could extend to fields like law or medicine, where verifying answers is tough.
- Practical and safe verification: Because each task is multiple-choice with a single correct option, checking answers is fast and objective — perfect for reinforcement learning loops.
The authors note that using internet text can carry biases, and cybersecurity improvements have dual-use concerns (helping defense but potentially also offense). Still, this technique provides a scalable, general path to build better reasoning models from widely available text.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues that future work could address.
- Dependence on GPT-5 for synthesis: How does data quality, task difficulty, and downstream RL gains change when using weaker or open-source generators (e.g., GPT-4, Llama, Qwen) rather than GPT-5? Provide head-to-head comparisons and cost–quality trade-offs.
- Reproducibility and accessibility: The pipeline’s core relies on a closed, non-public model (GPT-5). Can the approach be reproduced with publicly available models and prompts, and are the released datasets/code sufficient for independent replication?
- Quality assurance of synthesized MCQs: There is no explicit human evaluation or independent verifier ensuring that (i) the ground-truth masked span is correct and unambiguous, (ii) distractors are truly incorrect in context, and (iii) the masked step is actually the “crux.” Establish annotation protocols and inter-annotator reliability for a subset.
- Ambiguity and multiple-valid-answers risk: In many domains, multiple spans could plausibly fill the mask. How often do multiple options become partially correct or equivalently acceptable? Introduce adversarial filtering or multi-judge verification to detect ambiguity.
- Generator–distractor stylistic leakage: Since the same LLM generates the answer span and distractors, models may exploit stylistic or lexical cues rather than reason. Test cross-generator setups (e.g., different LLMs for answers vs distractors), style obfuscation, and adversarial distractors.
- MCQ-format overfitting: The training signal is answer selection in MCQ, but most downstream tasks are open-ended. Quantify how much performance transfers to long-form, chain-of-thought reasoning and program synthesis that require generative outputs.
- Open-ended vs MCQ training gap: The paper reports poor open-ended infill performance but doesn’t show whether MCQ-based RL degrades or improves free-form reasoning. Run controlled studies comparing MCQ-only, mixed MCQ/open-ended, and open-ended-only RL.
- Reward granularity: Binary matching to the correct option gives no partial credit for near-correct reasoning. Explore graded rewards (e.g., similarity to ground truth, step-level rubrics) and whether they improve reasoning quality without adding a heavyweight judge.
- Difficulty calibration bias: Difficulty-based filtering is performed using the student model’s success across 16 rollouts. This may bias the dataset toward that model’s “decision boundary.” How does this filtering transfer to other models or sizes? Evaluate filtering with multiple reference policies.
- Number of options and span length sensitivity: Only limited ablation is shown (e.g., nine options). Systematically study how option count, mask span length/position, and multiple masked spans affect learning across model sizes and domains.
- Contamination and overlap: The sources (AoPS, MegaScience, code problems) likely overlap with public benchmarks (e.g., Olympiad Bench). Provide a thorough contamination analysis and deduplication across training/evaluation corpora.
- Verifiability of “incorrectness”: Distractor incorrectness is asserted by the generator but not independently verified. Build automatic or human checks to ensure distractors are contextually wrong (not merely stylistically different).
- Hallucination and fabrication in noisy scrapes: For web data (e.g., FineWeb), the LLM first “extracts an educationally valuable passage.” How often does the generator fabricate details or introduce errors? Measure hallucination rates and implement anti-hallucination safeguards.
- Domain coverage beyond math/code/STEM/cyber: The approach is claimed to be general (e.g., medicine, law), but no experiments are provided. Test in additional knowledge-intensive domains and analyze domain-specific challenges (terminology, safety).
- Multilingual generalization: All experiments appear English-centric. Can the pipeline synthesize high-quality RLVR MCQs in other languages, and do gains transfer to multilingual benchmarks?
- Long-term scaling and saturation: While results show “revival” after 0.7M examples, it remains unknown if gains persist with much larger synthesized datasets or over longer training horizons. Provide scaling curves vs dataset size and training steps.
- Compute and cost accounting: Synthesis/verification with GPT-5 is likely expensive. Report the end-to-end cost (tokens, latency, GPU-hours) per usable RLVR sample and compare against handcrafted environments or human-curated RLVR data.
- Dataset diversity and deduplication: There is no analysis of diversity (topic, skill, reasoning pattern) or deduplication of near-duplicate MCQs. Introduce diversity metrics and redundancy control to mitigate overfitting to recurring patterns.
- Robustness to spurious cues: Even with option shuffling, models may exploit option length, punctuation, formatting, or tokenization artifacts. Diagnose and remove such artifacts; evaluate with adversarially perturbed options.
- Evaluation breadth: Most reported gains are on established reasoning/coding benchmarks. Add evaluations on long-form explanation quality, calibration, factual consistency, and robustness under instruction variants to assess broader impacts.
- Safety in cybersecurity: The work acknowledges dual-use but lacks red-teaming or misuse assessments. Evaluate whether MCQ-trained models become better at potentially harmful tasks and define mitigation strategies (e.g., policy filters, domain-specific safeguards).
- Legal/licensing risks: Using web scrapes and textbooks raises licensing and copyright questions. Clarify data provenance, permissions, and whether MCQ transformations constitute fair use in various jurisdictions.
- Transfer to tool-use and RAG: Many practical reasoning tasks involve tools (e.g., executing code, querying databases) or retrieval. Test whether MCQ-based RL improves tool-use reliability and RAG-integrated reasoning.
- RL algorithm generality: The pipeline is evaluated primarily with ProRLv2/GRPO. Do gains hold for other RL paradigms (PPO variants, off-policy RL, bandit-style preference RL, DPO/IPO alternatives)? Run cross-algorithm comparisons.
- Curriculum and scheduling: The work does not explore curricula (e.g., easy-to-hard sequencing, domain mixing schedules). Investigate adaptive sampling, dynamic difficulty, and curriculum design for more stable and efficient learning.
- Option-set construction policies: The number and nature of distractors (near-miss vs obviously wrong vs adversarial) are not systematically controlled. Develop principled distractor taxonomies and generation/selection policies tied to targeted reasoning skills.
- Multiple-mask tasks and non-contiguous reasoning: Only contiguous spans are masked. Many solutions depend on multi-hop, non-contiguous interactions. Explore multi-mask tasks and graph-structured masks to encourage deeper reasoning.
- Generalization across generator families: If the generator changes (e.g., from GPT-family to Llama-family), does the trained policy still perform as well, or did it learn generator-specific artifacts? Evaluate cross-family synthesis–training mismatches.
- Impact on instruction following and dialogue: MCQ training may shift models toward discriminative selection rather than instruction-following generation. Beyond IFEval, assess broader instruction adherence and conversational helpfulness.
- Negative transfer and trade-offs: Does MCQ RL adversely affect other capabilities (e.g., coding style, verbosity, safety refusal behavior)? Provide capability trade-off analyses before and after MCQ-based RL.
- Open-sourcing completeness: It is unclear whether all prompts, synthesis code, and final datasets (including the cybersecurity set) are released with sufficient metadata for reuse. Detail release plans, licenses, and any redactions/filters applied.
Glossary
- Advantage normalization: A technique in policy gradient methods that stabilizes learning by normalizing advantage estimates across groups and batches. "decoupled advantage normalization strategy from REINFORCE++ consisting of a group-wise mean subtraction followed by batch-level standardization."
- AIME: A math benchmark from the American Invitational Mathematics Examination used to evaluate problem-solving ability. "Math performance is tested on AIME 2024/2025"
- AMC: The American Mathematics Competitions benchmark used to assess mathematical reasoning. "AMC"
- AoPS-Instruct: A dataset of Olympiad-level math Q&A pairs extracted from the Art of Problem Solving forum. "AoPS-Instruct \citet{Mahdavi2025LeveragingOO} extracted around 600k question-answer pairs from the Art of Problem Solving (AoPS) forum"
- Clipped GRPO objective: A modification of the GRPO reinforcement learning objective that uses clipping to stabilize policy updates. "clipped GRPO objective with a decoupled advantage normalization strategy"
- CodeContests: A coding benchmark derived from competitive programming tasks to evaluate code generation. "CodeContests"
- CTI-Bench: A cybersecurity benchmark focused on cyber threat intelligence reasoning and vulnerability analysis. "CTI-Bench \cite{Alam2024CTIBenchAB}, which assesses threat-intelligence reasoning and vulnerability analysis"
- CyberMetricc: A cybersecurity benchmark testing knowledge in areas like compliance and penetration testing. "CyberMetricc \cite{10679494}, which tests knowledge in domains like compliance and penetration testing"
- Data saturation: The phenomenon where further training yields plateauing or declining performance due to finite and overused datasets. "data saturation occurs much earlier and is more severe with stronger LLMs"
- Difficulty-based filtering: A data curation step that removes overly easy tasks to preserve informative training signals. "We further apply difficulty-based filtering to remove easy problems."
- Distractors: Incorrect but plausible options in multiple-choice tasks designed to challenge the model. "generate a set of diverse, plausible distractors"
- Fill-in-the-middle: A task formulation where a contiguous reasoning span is masked and the model must infer the missing content. "fill-in-the-middle task"
- FineWeb: A large-scale web scrape corpus used as a source for synthesizing domain-specific tasks. "FineWeb \cite{Yu2025PrimusAP}"
- GPQA Diamond: A graduate-level STEM reasoning benchmark evaluating deep scientific understanding. "STEM reasoning is measured through GPQA Diamond"
- GRPO algorithm: A reinforcement learning method related to PPO, used for optimizing LLM policies with verifiable rewards. "variant of the GRPO algorithm"
- Ground-truth answer: The correct masked content used as the reference for verification in RL tasks. "treating the removed content as the ground-truth answer"
- GooseReason-0.7M: A large-scale RLVR dataset of ~0.7M synthesized tasks spanning math, programming, and science. "GooseReason-0.7M"
- GooseReason-Cyber: A synthesized RLVR dataset focused on the cybersecurity domain constructed from web scrapes. "GooseReason-Cyber"
- HumanEvalPlus: A coding benchmark extending HumanEval to evaluate code generation robustness and accuracy. "HumanEvalPlus"
- IFEval: A benchmark that evaluates instruction-following capability of LLMs. "IFEval"
- LLM-as-judge: A verification setup where a LLM evaluates whether a model’s open-ended answer matches the reference. "an LLM-as-judge verifies the prediction against the ground-truth"
- LiveCodeBench: A contamination-free coding benchmark for holistic evaluation of code generation. "LiveCodeBench"
- Masked context: The problem setup where critical reasoning steps in the source text are replaced with a [MASK] token. "construct a masked context $S_{\text{mask}$ by replacing in with a special token [MASK]"
- MegaScience: A dataset of university-level scientific textbook Q&A pairs spanning multiple STEM disciplines. "MegaScience\citet{fan2025megascience} exacted 650k question-answer pairs from nearly 12k university-level scientific textbooks"
- Minerva: A quantitative reasoning benchmark used to assess mathematical and scientific problem solving. "Minerva"
- Multiple-choice question (MCQ): A question format with several options where the model selects the correct answer, enabling simple verifiable rewards. "multiple-choice question-answering version (MCQ) of the fill-in-the-middle task."
- Olympiad Bench: A challenging benchmark of Olympiad-level problems to evaluate high-level mathematical reasoning. "Olympiad Bench"
- Open-ended: A task type with free-form answers that are difficult to automatically verify. "open-ended fill-in-the-mask"
- Pass@1: An evaluation metric indicating the accuracy of the first generated solution or choice. "Performance (pass@1) comparison across math benchmarks."
- Procedural data generators: Expert-designed environments that produce infinite verifiable tasks with tunable complexity. "handcrafted verifiable environments (i.e., procedural data generators)"
- ProRL: A reinforcement learning recipe for prolonged training of LLMs on verifiable tasks. "ProRL"
- ProRL-1.5B-v2: A strong RL-trained 1.5B-parameter model used as a baseline for continued training. "ProRL-1.5B-v2"
- ProRLv2: A variant of the GRPO-based RL recipe that emphasizes stable long-horizon training. "ProRLv2"
- Qwen-4B-Instruct: A 4B-parameter instruction-tuned LLM used for RL experiments and benchmarking. "Qwen-4B-Instruct"
- Reasoning Gym: A suite of procedurally generated tasks for evaluating logical and algorithmic reasoning. "Reasoning Gym"
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL paradigm where tasks provide automatic correctness checks to supply reward signals. "Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a core ingredient for unlocking complex reasoning behavior in LLMs"
- Rollout budgets: The number of sampled trajectories or attempts per training example used to compute RL signals. "through extended training steps or rollout budgets"
- Rollouts: Multiple independent model attempts on a task used to estimate success rates and learning signals. "both successful and failed model rollouts"
- rStar-Coder: A curated competitive programming dataset with expert-written problems and synthesized variants. "rStar-Coder \citet{liu2025rstarcoderscalingcompetitivecode} curated and cleaned 37.7K expert-written problems"
- Sandbox environment: An isolated execution setting for safely running unit tests and verifying code solutions. "sandbox environment"
- STEM: A category encompassing science, technology, engineering, and mathematics domains evaluated in the paper. "STEM"
- Unit tests: Automated checks that verify code correctness by executing test cases against expected outputs. "unit tests executable in a sandbox environment"
- Verifiable reward computation: Automatic validation that determines whether a model’s answer is correct to provide an RL reward. "verifiable reward computation"
- Verifier-based approach: A data curation and training strategy relying on automatic verifiers to check correctness. "under the verifier-based approach in current RLVR pipeline"
Practical Applications
Overview
This paper introduces a simple, scalable pipeline (“Golden Goose”) that transforms unverifiable, reasoning-rich text (e.g., textbooks, forums, web scrapes) into Reinforcement Learning with Verifiable Rewards (RLVR) tasks by masking key reasoning spans and turning them into multiple-choice fill-in-the-middle (FIM-MCQ) questions with plausible distractors. The resulting datasets (e.g., GooseReason-0.7M, GooseReason-Cyber) revive models that have saturated on existing RLVR data, enabling sustained gains in math, coding, STEM, and specialized domains like cybersecurity. Below are concrete, real-world applications derived from the method, results, and artifacts.
Immediate Applications
The following applications can be deployed now with current tooling and datasets, or with modest engineering effort:
- RLVR data augmentation for reasoning LLMs
- Sector(s): Software/AI platforms; Foundation model providers; Research labs
- Tools/Products/Workflows: Integrate the FIM-MCQ synthesis pipeline into existing RL training (e.g., ProRL/GRPO/PPO); regularly “refresh” training mixes with new MCQs generated from reasoning-rich corpora; monitor effective-sample ratio to avoid data staleness.
- Assumptions/Dependencies: Access to a strong “teacher” model for synthesis (e.g., frontier LLM), RL infrastructure with verifiable rewards, GPU budget; licensing/compliance for source corpora.
- Domain bootstrapping where RLVR data is scarce (e.g., cybersecurity)
- Sector(s): Security, Compliance, Enterprise IT, Defense
- Tools/Products/Workflows: Curate domain scrapes (e.g., FineWeb filters), synthesize MCQ-FIM tasks, difficulty-filter easy items, and train small/medium models for specialized benchmarks; release internal “Domain RLVR Packs” for continued training.
- Assumptions/Dependencies: High-quality domain scraping/filters; risk controls for dual use; legal permission to process web content; domain experts for post-hoc audits as needed.
- Coding assistant improvement via verifiable reasoning tasks
- Sector(s): Software engineering, DevTools
- Tools/Products/Workflows: Convert code explanations and discussions lacking test suites into MCQ code-reasoning tasks; use as RLVR data to upscale small coding models; expose “explain-then-choose” training curricula.
- Assumptions/Dependencies: Strong model can produce plausible distractors without leaking the answer; avoid contamination; sandbox eval remains MCQ-based rather than executing untrusted code.
- STEM education content generation (practice and assessments)
- Sector(s): Education/EdTech
- Tools/Products/Workflows: Convert textbook Q/A and solutions into MCQ fill-in-the-middle items; calibrate difficulty by adjusting number/quality of distractors; generate formative assessments and step-focused quizzes; integrate into LMS.
- Assumptions/Dependencies: Rights to use textbooks; LLM moderation to avoid toxic or biased material; item banking and deduplication to prevent answer leakage.
- Enterprise knowledge training for internal assistants
- Sector(s): Enterprise software, Knowledge management, Compliance
- Tools/Products/Workflows: Transform SOPs, policy documents, and technical manuals into verifiable MCQ tasks that test understanding of critical steps; leverage RLVR to tune internal assistants on company-specific reasoning without human graders.
- Assumptions/Dependencies: Data governance and privacy; legal review for internal document processing; accuracy checks where errors create operational risk.
- Evaluation set creation with controllable difficulty
- Sector(s): AI benchmarking, QA/testing
- Tools/Products/Workflows: Produce MCQ-FIM benchmarks from public corpora with known masked spans; tune difficulty via distractor count/quality; track model saturation by success/failure rollouts.
- Assumptions/Dependencies: Balanced distractor generation to minimize “elimination heuristics”; contamination checks to preserve benchmark integrity.
- Compute-efficient RL scaling
- Sector(s): AI training/ops
- Tools/Products/Workflows: Under fixed budgets, mix MCQ-FIM tasks with existing RLVR data to achieve higher gains per step; prioritize tasks that yield mixed rollout outcomes (most informative advantages).
- Assumptions/Dependencies: Accurate measurement of “effective examples”; scheduler to maintain a target distribution of medium-difficulty tasks.
- Instruction-following and reasoning generalization tuning
- Sector(s): General AI products, Agent frameworks
- Tools/Products/Workflows: Use MCQ-FIM to enforce adherence to task constraints (selecting the masked step vs. solving from scratch); supplement chain-of-thought training with verifiable choices to stabilize RL.
- Assumptions/Dependencies: Careful prompt formatting; avoidance of overfitting to MCQ; periodic validation on non-MCQ tasks.
- Safer alternatives to LLM-as-judge verification
- Sector(s): AI safety, Compliance
- Tools/Products/Workflows: Substitute or complement judge-based verification with MCQ ground-truth matching to reduce compute and judgment variability in RL training pipelines.
- Assumptions/Dependencies: MCQ alignment with real reasoning quality; good distractor diversity to avoid trivial options.
- Personalized study tools and daily learning
- Sector(s): Consumer apps, Lifelong learning
- Tools/Products/Workflows: Apps that convert articles/tutorials into step-focused MCQs for self-study; difficulty adapts by number of distractors; explanations reveal masked “crux” steps to reinforce learning.
- Assumptions/Dependencies: Content licenses; precise span selection to avoid trivial or ambiguous items; UX that shows context around the mask.
Long-Term Applications
These applications require additional research, domain validation, scaling, or regulatory considerations:
- High-stakes domain RLVR (medicine, law, finance)
- Sector(s): Healthcare, Legal, Finance
- Tools/Products/Workflows: Convert guidelines, case studies, and worked solutions into MCQ-FIM tasks that mask pivotal diagnostic/legal/analytical steps; train domain LLMs with verifiable rewards to enhance stepwise reasoning.
- Assumptions/Dependencies: Rigorous domain expert validation; bias/ethics reviews; approval pathways for clinical/legal deployment; stronger methods to avoid misleading distractors.
- Agent planning and tool-use training via step masking
- Sector(s): Software agents, Automation, Robotics (planning modules)
- Tools/Products/Workflows: Mask critical planning steps in procedures or tool-use tutorials; train reasoning modules to pick the right next step; combine with tool execution for closed-loop evaluation.
- Assumptions/Dependencies: Mapping MCQ choices to executable actions; bridging from textual step selection to robust plans; safety constraints for real-world actuation.
- Continual learning pipelines from live data
- Sector(s): AI platforms, MLOps
- Tools/Products/Workflows: Always-on scrapers for targeted domains; periodic synthesis of MCQ-FIM tasks; difficulty filters to prioritize informative items; automatic curriculum to prevent saturation.
- Assumptions/Dependencies: Reliable deduplication/contamination control; monitoring to curb data drift and topic imbalance; sustained access to high-quality sources.
- Process reward modeling and structured verification
- Sector(s): AI research
- Tools/Products/Workflows: Leverage masked-step supervision to train process reward models (PRMs) that assess intermediate reasoning; extend beyond MCQ by aligning step embeddings with ground-truth proofs/derivations.
- Assumptions/Dependencies: New verifiers for semi-structured intermediate steps; hybrid MCQ+open-ended scoring; scalability of annotations or automated alignment.
- Curriculum and difficulty-aware RL orchestrators
- Sector(s): AI training/ops, EdTech
- Tools/Products/Workflows: Orchestrators that automatically adjust distractor count, topic mix, and span length to target optimal “medium-difficulty” regimes; maximize effective-example ratio over time.
- Assumptions/Dependencies: Reliable difficulty estimators; avoidance of curriculum collapse; cross-domain generalization.
- Policy and standards for verifiable training artifacts
- Sector(s): Policy, Governance, Certification
- Tools/Products/Workflows: Standardized protocols for RLVR dataset synthesis, difficulty labeling, and provenance; audits documenting how unverifiable text was transformed into verifiable tasks.
- Assumptions/Dependencies: Multi-stakeholder consensus; legal clarity on data sourcing/transformation; privacy safeguards.
- Cross-modal and multi-turn reasoning MCQs
- Sector(s): Multimodal AI, Education, Design/Manufacturing
- Tools/Products/Workflows: Extend MCQ-FIM to diagrams, tables, code+text, or multi-turn dialogues by masking pivotal multimodal steps; verifiable choices align with ground-truth artifacts.
- Assumptions/Dependencies: Multimodal distractor generation; robust verification across formats; UI for presenting masked context.
- Safety-focused RLVR synthesis (defense and hardening)
- Sector(s): Cybersecurity, Trust & Safety
- Tools/Products/Workflows: Generate MCQ-FIM tasks designed to elicit safe choices (e.g., non-escalatory actions, compliance-friendly steps) and penalize risky reasoning; build verifiable “red team to green team” curricula.
- Assumptions/Dependencies: Safety taxonomies, domain constraints, and red-team input to avoid inadvertently teaching misuse; governance of release practices.
- Regulatory compliance assistants trained on policies
- Sector(s): Finance, Healthcare, Government
- Tools/Products/Workflows: Mask key compliance steps in regulations/SOPs to train assistants that reliably choose compliant actions; integrate with auditing workflows for explainability.
- Assumptions/Dependencies: Up-to-date policy corpora; jurisdictional differences; legal review; fine-grained traceability of choices.
- Enterprise-grade “RLVR Data Synthesizer” products
- Sector(s): AI tooling vendors, Platforms
- Tools/Products/Workflows: Off-the-shelf SaaS that ingests licensed corpora and outputs vetted MCQ-FIM datasets with provenance, difficulty metrics, and contamination reports; plug-ins for popular RL recipes.
- Assumptions/Dependencies: Market demand; SLAs for quality and compliance; connectors to enterprise data lakes and RL stacks.
Notes on Feasibility and Risk (cross-cutting)
- Dependencies on strong synthesis models: Quality of masked spans and distractors depends on a powerful LLM; weaker models may produce trivial or misleading items.
- Legal and ethical use of web data: Ensure licenses permit transformation for training; implement privacy and content filtering; document provenance.
- Bias and safety: Unverifiable text can carry biases/toxicity; include filtering and audits, especially in high-stakes or dual-use domains (e.g., cybersecurity).
- Overfitting to MCQ format: Mitigate with mixed-format training and evaluations; regularly validate on non-MCQ tasks.
- Effective-example monitoring: Maintain medium-difficulty regimes (e.g., by tuning number of distractors) to keep RL signal informative.
These applications collectively show how Golden Goose can unlock scalable, verifiable reasoning training across industries, research, policy, and consumer learning—immediately for RL data augmentation and domain bootstrapping, and over time for high-stakes domains, standards, and robust agentic systems.
Collections
Sign up for free to add this paper to one or more collections.