- The paper introduces RLVE, an innovative framework that dynamically adjusts problem difficulty to optimize reinforcement learning for language models.
- It details the RLVE-Gym suite with 400 verifiable environments targeting programming, mathematics, and logical puzzles to enable scalable and diverse training.
- Experimental results show that adaptive difficulty significantly improves in-distribution and out-of-distribution performance under compute constraints.
RLVE: Scaling Up Reinforcement Learning for LLMs with Adaptive Verifiable Environments
Introduction
The paper "RLVE: Scaling Up Reinforcement Learning for LLMs with Adaptive Verifiable Environments" focuses on an approach termed RLVE (Reinforcement Learning with Adaptive Verifiable Environments) to enhance the efficiency of reinforcement learning (RL) when applied to LMs (2511.07317). The RLVE methodology employs dynamically adapting problem difficulty within verifiable environments to optimize training signals and improve learning effectively.
Methodology
RLVE fundamentally shifts the RL paradigm by introducing the concept of adaptive verifiable environments which dynamically modify their problem difficulty based on the evolving capabilities of the policy model. A verifiable environment is defined as a tuple E=(I,P,R), where I is the input template, P is a procedural problem generator, and R serves as the verifier providing algorithmically verifiable rewards. A critical component is employing a dynamic difficulty range [ℓπ,hπ] which adjusts according to the policy’s performance. This ensures problems remain within a challenging yet solvable scope for the model, avoiding the pitfalls of static difficulty distributions which often lead to saturated learning profiles.
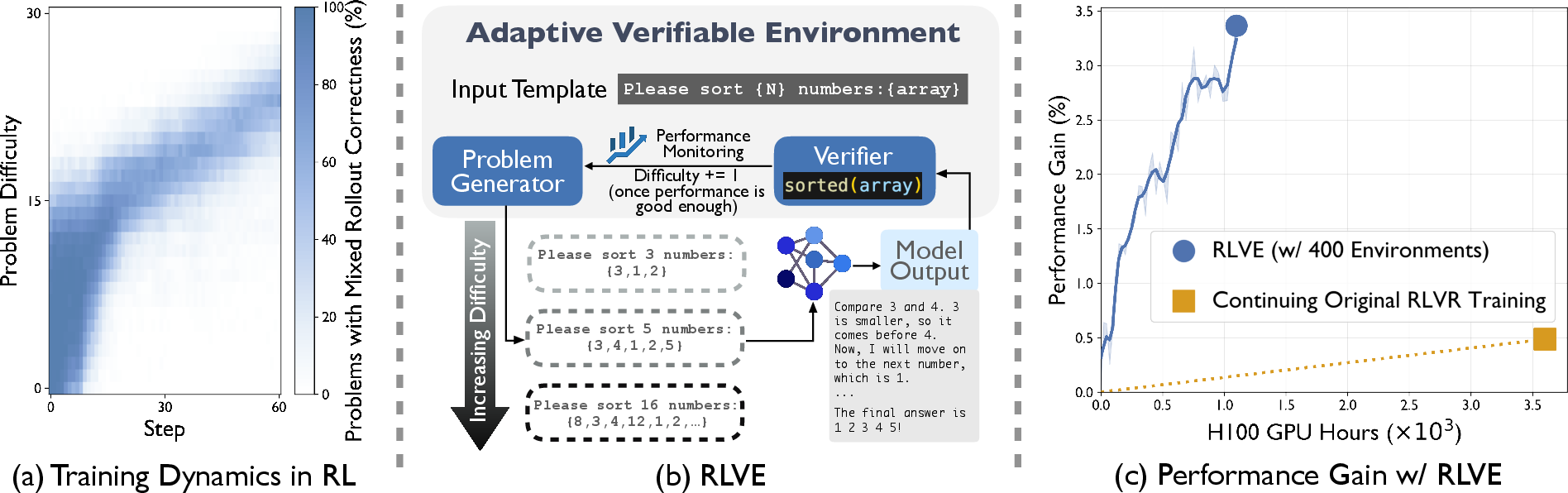
Figure 1: During RL training, some array-sorting problems become too easy, while others that were too hard become learnable as the policy improves.
Implementation: RLVE-Gym
To implement RLVE, the researchers designed RLVE-Gym, a comprehensive suite consisting of 400 verifiable environments. These environments address various domains such as programming, mathematical operations, and logical puzzles, each crafted to incrementally challenge the LM. Implementation details emphasize environments as pedagogical tools, leveraging computational asymmetries where environments can verify outputs more efficiently than the LM can solve them.
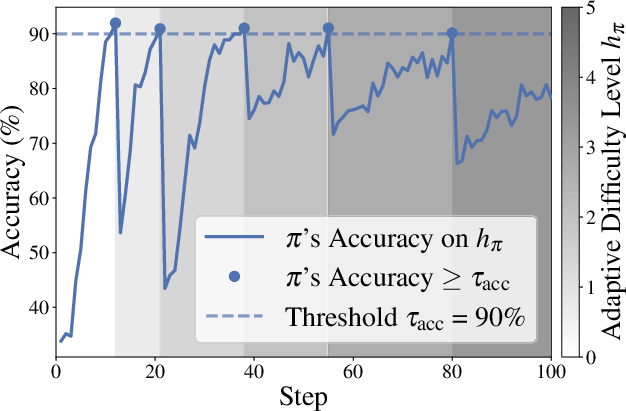
Figure 2: Illustration of adaptive difficulty enabled by RLVE when training a policy model on the Sorting environment.
Experimental Results
The authors conducted extensive experiments to validate the effectiveness of RLVE, demonstrating substantial improvements in both in-distribution (ID) and out-of-distribution (OOD) environments.
- Adaptive vs. Static Difficulty: Adaptive environments result in higher learning efficiency and prevent learning stalls common with static distributions (Figure 3).
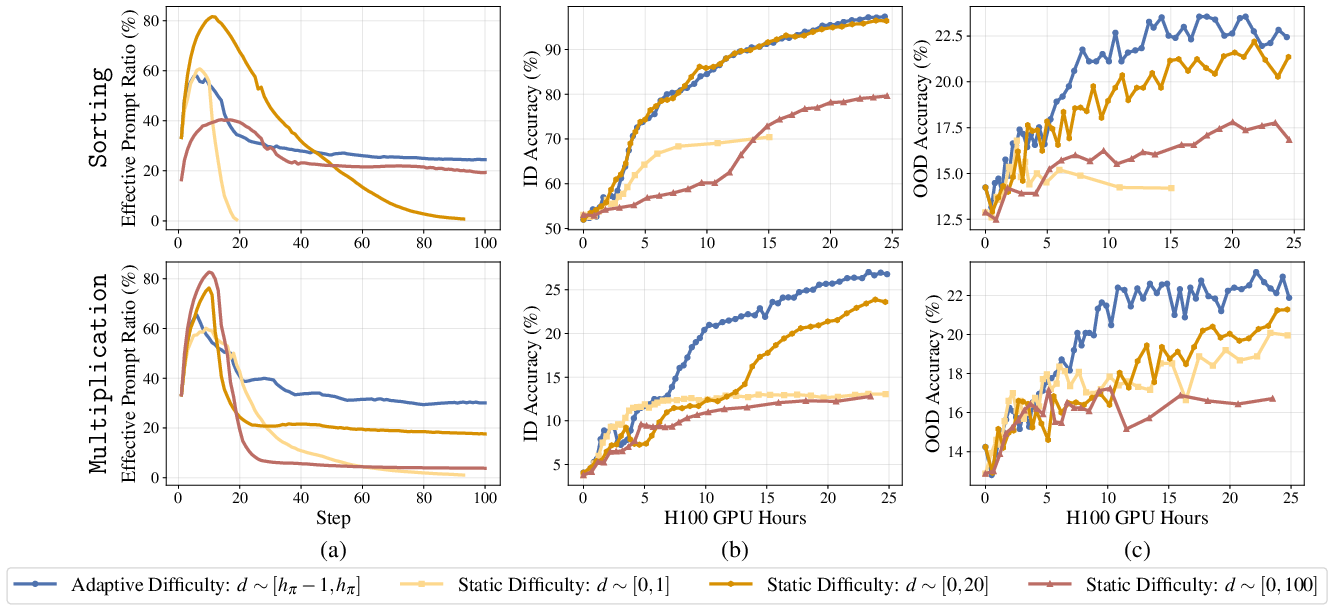
Figure 3: Comparison of RLVE (using dynamically adjusted difficulty range) against static difficulty ranges, showing superior ID and OOD performance.
- Environment Scaling: Increasing the number of environments in RLVE-Gym consistently enhances OOD performance, supporting the theory that diversity in training environments fosters generalizable capabilities (Figure 4).
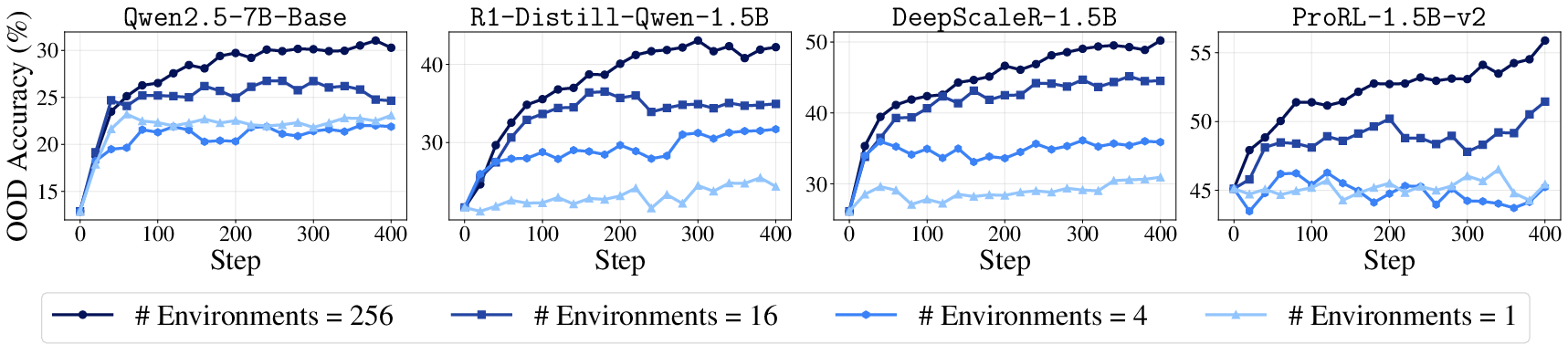
Figure 4: Expanding the collection of training environments consistently leads to better performance on held-out environments across all model types.
- Compute-Efficiency: In scenarios comparing RLVE against high-quality RLVR datasets, RLVE demonstrated superior results in fostering generalizable reasoning capabilities when constrained by compute resources.
Implications and Future Directions
The research underscores the potential of adaptive environments in RL for LMs, addressing inherent limitations encountered with static datasets. RLVE's implementation not only optimizes compute efficiency but also significantly enhances the generalization capabilities of LMs.
Moving forward, the authors advocate for advancements in adaptive environment engineering, potentially elevating environment construction as a foundational aspect of LM development. Future explorations could also extend RLVE principles to non-verifiable environments, thereby addressing challenges in creative tasks where verifiable rewards are less applicable.
Conclusion
Overall, the RLVE framework presents a robust advancement in the landscape of RL for LLMs, promoting adaptive difficulty as a key lever for achieving scalable, efficient, and generalizable LM training. The introduction of RLVE-Gym serves as an adaptable and comprehensive platform that paves the way for ongoing innovations in AI.