Crossing the Reward Bridge: Expanding RL with Verifiable Rewards Across Diverse Domains
Abstract: Reinforcement learning with verifiable rewards (RLVR) has demonstrated significant success in enhancing mathematical reasoning and coding performance of LLMs, especially when structured reference answers are accessible for verification. However, its extension to broader, less structured domains remains unexplored. In this work, we investigate the effectiveness and scalability of RLVR across diverse real-world domains including medicine, chemistry, psychology, economics, and education, where structured reference answers are typically unavailable. We reveal that binary verification judgments on broad-domain tasks exhibit high consistency across various LLMs provided expert-written reference answers exist. Motivated by this finding, we utilize a generative scoring technique that yields soft, model-based reward signals to overcome limitations posed by binary verifications, especially in free-form, unstructured answer scenarios. We further demonstrate the feasibility of training cross-domain generative reward models using relatively small (7B) LLMs without the need for extensive domain-specific annotation. Through comprehensive experiments, our RLVR framework establishes clear performance gains, significantly outperforming state-of-the-art open-source aligned models such as Qwen2.5-72B and DeepSeek-R1-Distill-Qwen-32B across domains in free-form settings. Our approach notably enhances the robustness, flexibility, and scalability of RLVR, representing a substantial step towards practical reinforcement learning applications in complex, noisy-label scenarios.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper explores a way to train AI LLMs to reason better using a method called “reinforcement learning with verifiable rewards” (RLVR). Instead of just math and coding, the authors test RLVR on many school subjects—like medicine, chemistry, psychology, and economics—where answers are free-form and not just a single number or letter. They show that a single, small “judge” model can reliably check whether an AI’s answer matches an expert-written reference answer, and that this helps train stronger AI models across diverse fields.
What questions did the researchers ask?
- Can RLVR work well outside of math and coding, where answers are often messy and long?
- Do we need huge, special reward models for each subject, or can one general “judge” work across many subjects?
- Is it better to score answers as simply right/wrong (binary), or give partial credit with flexible “soft” scores?
- Can a smaller judge model, trained from a bigger one, be good enough?
- Does this approach scale up—does performance keep improving with more training?
How did they do it? (In simple terms)
Imagine a classroom:
- The “student” is the AI trying to answer questions.
- The “answer key” is an expert-written reference answer for each question.
- The “judge” is another AI that checks if the student’s answer matches the reference answer.
Here’s the approach:
- Reference-based judging: The judge AI reads the question, the student’s final answer, and the reference answer, then outputs:
- Binary score: 1 (correct) or 0 (incorrect), like a simple pass/fail.
- Soft score: A confidence score between 0 and 1, like partial credit if the answer is close.
- Soft rewards: Instead of only right/wrong, the judge gives a confidence score. Think of it like a teacher saying, “You’re 80% correct,” which helps the student learn more smoothly.
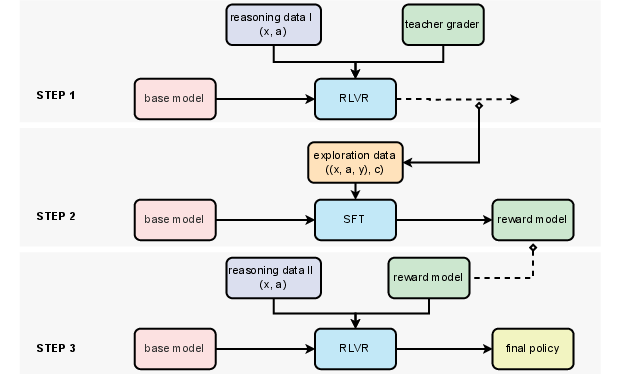
- Training the judge: The team used a large, strong AI (“teacher judge,” e.g., a 72B model) to label many answers, then trained a smaller AI (“student judge,” a 7B model) to copy its judgments. This is like a senior teacher training a junior teacher.
- Reward normalization: When training, they compare scores within each batch of student answers and scale them. It’s like grading on a curve—so improvements stand out and training is stable.
- Staying sensible (KL penalty): They nudge the student AI not to drift too far from how it usually writes, so it doesn’t learn odd tricks just to please the judge.
- Datasets:
- Math: A big set of school math questions with long, free-form reference answers (not just “42”). Translated from Chinese to English.
- Multi-subject: A large exam-style dataset (medicine, law, economics, management, psychology, chemistry, etc.), turned into free-form Q&A with objective answers.
- RL algorithms: They tried three standard learning strategies (REINFORCE, RLOO, REINFORCE++) that all follow the same basic idea—try answers, get points from the judge, tweak the AI to do better next time.
What did they find, and why does it matter?
Here are the main findings:
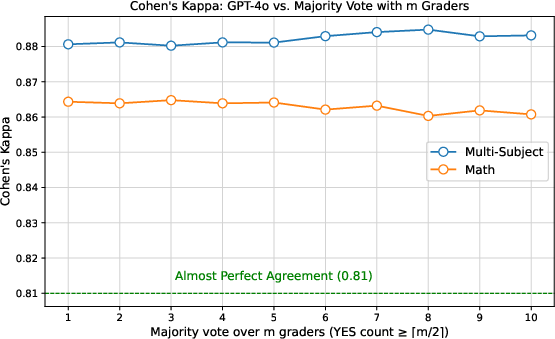
- A single cross-domain judge works: Different strong LLMs largely agree when judging with reference answers. This suggests you don’t need gigantic, domain-specific labeled datasets to build a reliable judge.
- Soft scores help in harder, messier subjects: Binary (right/wrong) works fine in math (where matching is clearer). But in complex subjects with diverse wording, soft scores are more flexible and can lead to better learning.
- A small judge can be great: Their trained 7B judge model performed almost as well as (and sometimes better than) a much larger 72B judge, while being cheaper and faster.
- Better than big models: Using RL with their judge, a base 7B model beat powerful open-source models (like Qwen2.5-72B-Instruct and DeepSeek-R1-Distill-Qwen-32B) by a noticeable margin (up to 8% accuracy improvement) across multiple domains.
- Scales well: As they used more training data, the model-based reward (the judge) kept improving results. But rule-based rewards (simple matching rules) got worse with more data, especially when answers were unstructured.
- Works out-of-distribution: The judge also helped on other benchmarks beyond the training domains, showing it generalizes well.
Why it matters:
- It shows we can train AIs to reason across many subjects using verifiable answers, without building separate, giant reward models for each field.
- It makes RLVR more robust and practical for real-world tasks where answers aren’t neat or standardized.
- It points to a scalable path for improving reasoning in LLMs using affordable, smaller models as judges.
What’s the big takeaway?
This work expands RLVR beyond math and coding to many subjects with free-form answers. By using a general-purpose judge model (even a small one) and soft scoring, AI can learn to reason better across domains. It reduces the need for expensive, domain-specific labeling, scales well with more data, and beats strong baselines. This approach makes it more realistic to deploy AI that can learn from noisy or varied answers—like those you’d find in exams, textbooks, or real-world problem solving.
Collections
Sign up for free to add this paper to one or more collections.