- The paper’s main contribution is introducing a probability-based reward framework that eliminates the need for domain-specific verifiers.
- It leverages intrinsic token probabilities from LLMs to generate stable reward signals, resulting in significant improvements in reasoning tasks.
- The framework incorporates debiasing and filtering techniques to ensure robustness against variations in prompt design while enhancing scalability.
RLPR: Extrapolating RLVR to General Domains without Verifiers
The RLPR framework aims to advance Reinforcement Learning with Verifiable Rewards (RLVR) by removing its dependence on domain-specific verifiers, thereby enhancing reasoning capabilities across general domains. Central to RLPR is utilizing the intrinsic token probabilities from LLMs as a reward signal, which eliminates the complexity and scalability issues tied to traditional verifier-based methods.
RLPR Framework
Motivation and Design
RLVR has traditionally relied on domain-specific verifiers to evaluate the correctness of generated responses, especially in mathematical and coding domains. However, the reliance on verifiers leads to high complexity and limited scalability when expanded to general domains. RLPR proposes replacing these external verifiers with the intrinsic probability scores generated by the LLM itself, leveraging its foundational capabilities for reward generation.
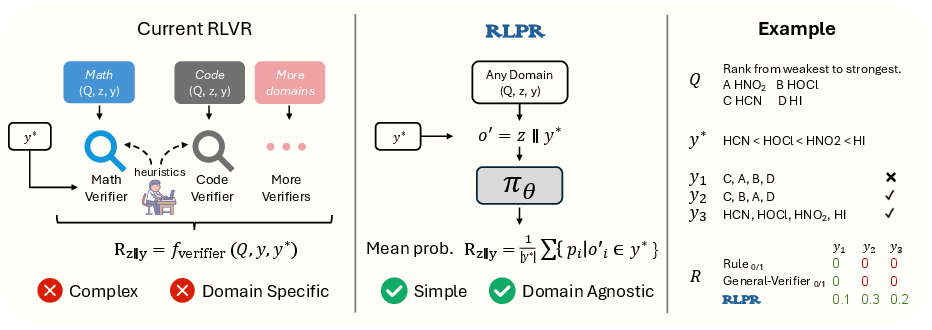
Figure 1: The RLPR framework replaces complex verifier-based rewards with simple probability-based rewards generated by the policy model, enhancing natural language processing capabilities.
Probability Reward Computation
The concept of Probability Reward in RLPR involves calculating rewards based on the LLM's internal evaluation of response quality via token probabilities. Specifically, the framework computes the mean probability of the reference answer's tokens to derive a stable and precise reward signal. This mechanism is more robust than traditional sequence likelihood, as it mitigates the high variance and instability in reward signals caused by minor variations such as synonyms.
Debiasing and Filtering
To address biases in probability-based rewards, the RLPR incorporates a debiasing method that adjusts rewards by comparing the standard decoding of reference answers without reasoning. Additionally, RLPR employs a standard deviation filtering strategy to exclude prompts with low reward variance, adaptive to shifts in reward distribution throughout training.
Experimental Results
Comprehensive experiments demonstrate RLPR's substantial improvements in reasoning tasks across both mathematical and general domains. For instance, RLPR achieved a notable average accuracy improvement over existing RLVR methods such as General Reasoner and concurrent approaches like VeriFree (Figure 2).
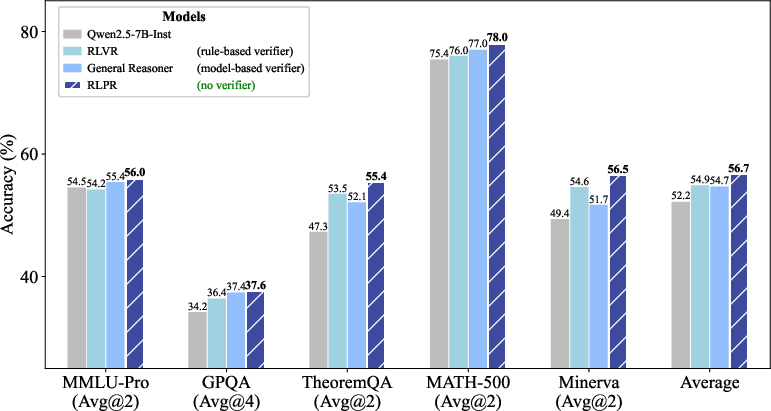
Figure 2: RLPR achieves consistent improvements in both mathematical and general-domain benchmarks, outperforming strong RL methods driven by verifier rewards.
Robustness
Testing across different training prompt templates reveals RLPR's consistent performance and resilience to variations in prompt design, response length, and entropy, exhibiting minimal sensitivity compared to other methods.
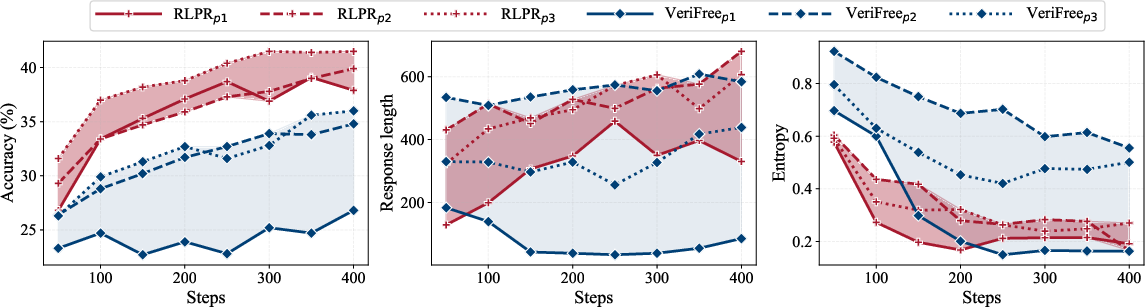
Figure 3: RLPR demonstrates robustness across different training prompt templates, maintaining high performance and stable response characteristics.
Analysis of Probability Reward
Quality and Effectiveness
Through token-level probability analysis and quantitative ROC-AUC evaluation, Probability Reward displays superior discrimination capability compared to rule-based verifiers and trained verifier models. The per-token approach yields stable reward signals, correlating highly with response quality across diverse domains.
Enhancing Verifiable Domains
In domains with established verifiers, RLPR further enhances reasoning by combining rule-based and probability rewards, demonstrating improved utilization of mathematical data in tasks such as theorem proving.
Conclusion
RLPR marks a significant step towards scalable domain-general reinforcement learning by utilizing intrinsic LLM capabilities for reward generation, eschewing external verifiers. The framework's innovative approach to reward computing and training stability through debiasing and filtering strategies sets the stage for broader applications, including multimodal understanding. Future exploration will focus on expanding RLPR to larger models and various complex domains.

