LaSeR: Reinforcement Learning with Last-Token Self-Rewarding
Abstract: Reinforcement Learning with Verifiable Rewards (RLVR) has recently emerged as a core paradigm for enhancing the reasoning capabilities of LLMs. To address the lack of verification signals at test time, prior studies incorporate the training of model's self-verification capability into the standard RLVR process, thereby unifying reasoning and verification capabilities within a single LLM. However, previous practice requires the LLM to sequentially generate solutions and self-verifications using two separate prompt templates, which significantly reduces efficiency. In this work, we theoretically reveal that the closed-form solution to the RL objective of self-verification can be reduced to a remarkably simple form: the true reasoning reward of a solution is equal to its last-token self-rewarding score, which is computed as the difference between the policy model's next-token log-probability assigned to any pre-specified token at the solution's last token and a pre-calculated constant, scaled by the KL coefficient. Based on this insight, we propose LaSeR (Reinforcement Learning with Last-Token Self-Rewarding), an algorithm that simply augments the original RLVR loss with a MSE loss that aligns the last-token self-rewarding scores with verifier-based reasoning rewards, jointly optimizing the reasoning and self-rewarding capabilities of LLMs. The optimized self-rewarding scores can be utilized in both training and testing to enhance model performance. Notably, our algorithm derives these scores from the predicted next-token probability distribution of the last token immediately after generation, incurring only the minimal extra cost of one additional token inference. Experiments show that our method not only improves the model's reasoning performance but also equips it with remarkable self-rewarding capability, thereby boosting its inference-time scaling performance.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy-to-Understand Summary of “LaSeR: Reinforcement Learning with Last-Token Self-Rewarding”
What is this paper about?
This paper is about teaching LLMs to solve hard problems (like math) and also to judge how confident they should be in their own answers—quickly and efficiently. The authors introduce a method called LaSeR that lets a model “check its own work” using just one tiny extra step at the very end of its answer, instead of running a whole second round of explanation or using a separate judging model.
What questions are the researchers trying to answer?
In simple terms, they ask:
- How can we make an LLM better at reasoning on tricky problems?
- When we can’t check answers against the true solution (like at test time), can the model still tell if its answer is likely correct?
- Can we do this checking (self-verification) without wasting time or extra computing?
How does their method work?
First, a few key ideas in everyday language:
- Reinforcement Learning (RL): Imagine a student who gets points for correct answers and learns to do better over time. RL is like that for models.
- Verifier: A rule or program that says “correct” or “incorrect” by comparing the model’s final answer to the true answer.
- The problem: During testing, we don’t have the true answer, so the usual verifier can’t help.
- Old solutions: Train a separate “judge model,” or ask the same model to write a second “verification explanation.” Both are slow or expensive.
LaSeR’s idea:
- When a model finishes an answer, it still has a probability distribution over what the next token (the next small piece of text) could be—even if it’s “done.”
- The authors discovered that a simple number taken from this final step—the probability the model assigns to a special, never-used token—acts like a “confidence meter” for the whole solution.
- They prove that this “last-token score” closely tracks the true reward (correct vs. incorrect) used in training, after applying a constant scale. In practice, it’s basically:
- “How strongly do I (the model) think this special token should come next?” minus a constant number, scaled by a knob (a coefficient).
- Because the reference model’s part of this calculation barely changes across problems, they can treat it as a fixed constant. That makes it super fast to compute.
Training with LaSeR:
- The model solves a problem as usual.
- A standard verifier (which we only have during training) gives a 1 for correct or 0 for incorrect.
- LaSeR adds a simple “make-these-numbers-match” training goal: it nudges the model so that the last-token score aligns with the true reward (the 1 or 0).
- This is done with a Mean Squared Error (MSE) loss—think of it as “shrink the difference between the model’s confidence and the truth.”
Bonus techniques they add to make training stable and fair:
- Balance correct/incorrect examples so the model doesn’t get biased.
- Carefully mix this new self-confidence signal with the usual RL signal.
- Warm up in stages: first get reasoning solid, then teach self-rewarding, then combine both.
Efficiency:
- Training: no extra long generations—only one extra probability check at the end.
- Testing: one tiny extra step (at most one token inference) to read the confidence score. No second pass, no extra judge model.
What did they find, and why does it matter?
Main results:
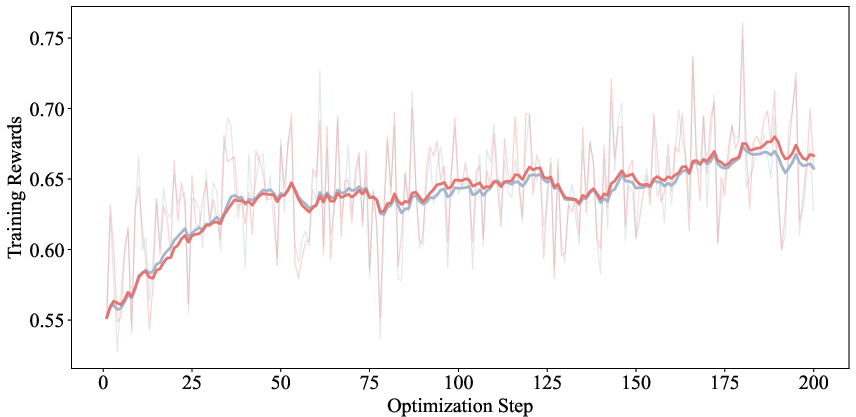
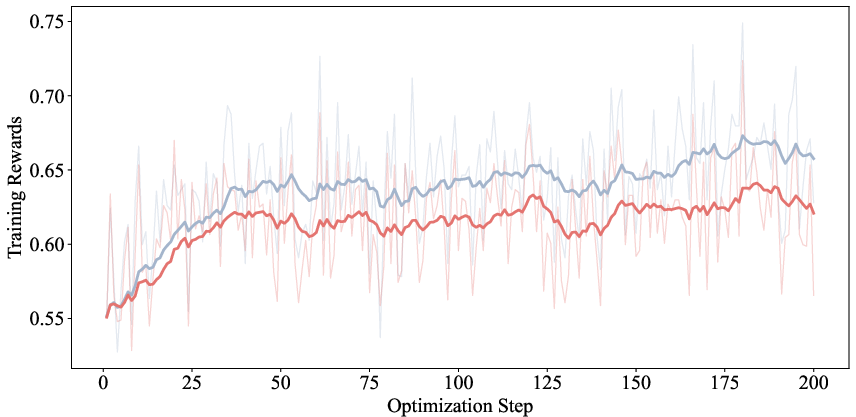
- Better reasoning: Across multiple math benchmarks (like MATH500, AMC23, AIME24/25, OlympiadBench), models trained with LaSeR generally solved more problems correctly than the usual RL baseline.
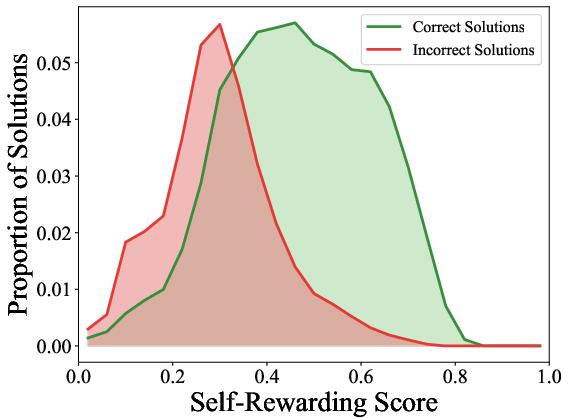
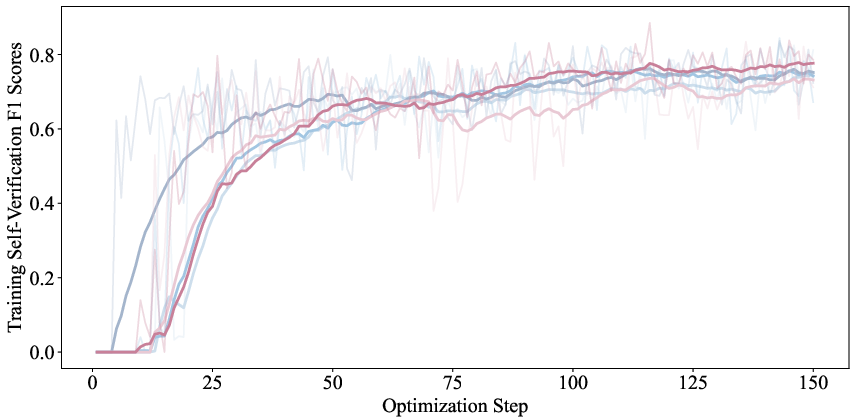
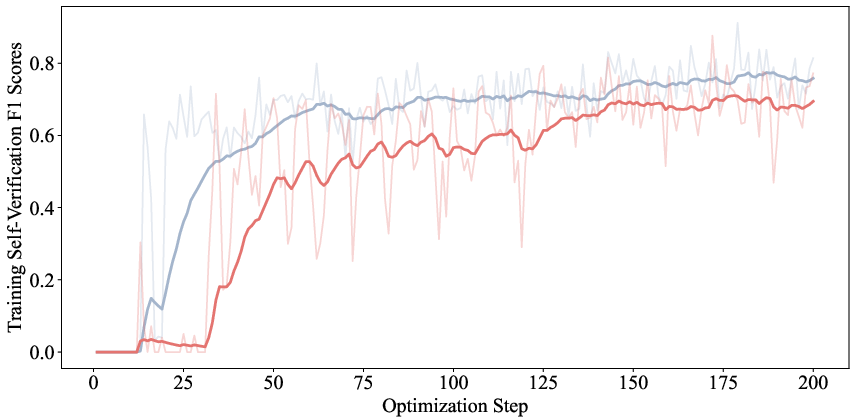
- Strong self-checking: The model’s last-token score can accurately tell whether its own answer is correct or not, reaching around 80% F1 score (a balanced accuracy measure). That’s very good for a single, cheap signal.
- Competes with big “judge” models: In many cases, LaSeR’s built-in self-checking matched or approached the quality of large, specialized reward models (including ones much bigger than the model being trained).
- Better when sampling multiple answers: If you generate several answers and use the last-token scores to weight a “vote,” the final accuracy goes up more than simple majority voting. This helps at test time when you don’t know the right answer.
Why it matters:
- It makes LLMs more confident and better calibrated about their own answers.
- It avoids the cost and complexity of training or running a separate verifier model.
- It speeds up test-time reasoning because you don’t need a second generation step for verification.
What could this change or lead to in the future?
- Faster, smarter LLMs: Models that can reason well and judge themselves in one pass are more practical and cheaper to run.
- Broader use: The idea plugs into common RL training setups and could work beyond math, helping in other reasoning-heavy tasks.
- Better “inference-time scaling”: When you spend more compute at test time (e.g., generate more samples), LaSeR helps you pick the best result more reliably.
In short, LaSeR shows that a simple, clever signal from the very last step of a model’s output can double as a powerful self-check—making reasoning systems both stronger and more efficient.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to enable concrete follow-up research.
- Unquantified approximation error in Z(x,y) ≈ 1: The theoretical reduction hinges on tiny, near-constant reference probabilities for z_c and z_i at the last token and ignores the partition function. There is no bound or sensitivity analysis quantifying when this approximation breaks and how deviations affect training and calibration.
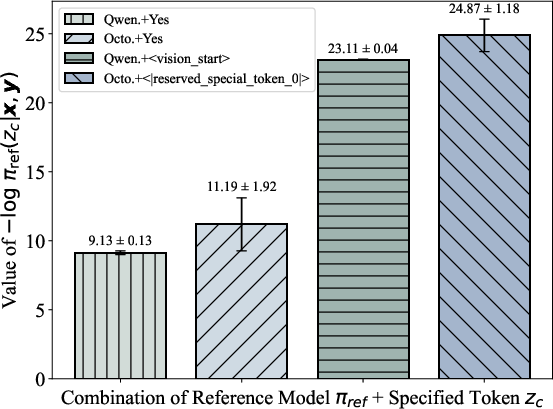
- Assumption that log π_ref(z_c|x,y) is a global constant: c_ref is estimated on a small sample and then fixed. The paper does not analyze drift or distribution shift effects (e.g., different datasets, domains, or model sizes) on this assumption, nor provide diagnostics for detecting when c_ref needs recalibration.
- Choice and properties of the special token z_c: The impact of different token choices (unused vs common tokens, tokenizer differences, multilingual vocabularies, model families) is not studied. There is no guidance on selecting z_c or handling token collisions in other settings (e.g., multi-modal models where these tokens may be repurposed).
- Ignoring the “negative” token z_i at training time: The self-rewarding loss only models the positive verification log-probability for z_c. It is unclear whether symmetric modeling with z_i (or a contrastive formulation) would yield better calibration, robustness, or discrimination.
- Calibration of r_s as a probability of correctness: The method uses a fixed threshold (0.5) on r_s without calibrating it to actual correctness probabilities. Reliability curves, ECE/MCE, and task-specific threshold selection are not reported.
- Vulnerability to reward hacking at the last token: Because r_s depends on the last-token distribution, the model might learn to manipulate the final context (e.g., early stopping, templated endings, “format features”) to inflate πθ(z_c|x,y) without improving reasoning quality. No safeguards or audits are presented.
- Length effects and early termination: While sequence-level implicit rewards are length-biased, it’s not shown whether r_s is invariant to output length or if models can game r_s by shortening outputs. Quantifying correlations between r_s and length is missing.
- Robustness to verifier noise or ambiguity: The method is evaluated with deterministic, accurate math verifiers. It is unclear how LaSeR behaves with noisy, probabilistic, or partial-credit verifiers or in tasks where verification is ambiguous.
- Generalization beyond math reasoning: Experiments are limited to math. The approach is untested on code (unit-test verifiers), tool-use/agent tasks, open-domain QA with weak verifiers, or non-binary verification regimes.
- Transferability of self-rewarding to other generators: The paper assesses each model’s self-rewarding on its own generations. It remains unknown whether a LaSeR-trained verifier can reliably score outputs from other models (cross-model verification).
- Comparison to alternative confidence proxies: There is no head-to-head against established uncertainty/confidence signals (e.g., entropy, token-level variance via dropout, normalized sequence likelihoods, LM calibration methods). It’s unclear when r_s is superior.
- Integration with other RLVR algorithms: LaSeR is demonstrated only with GRPO. Whether the approach holds with PPO, DAPO/VAPO, DR-GRPO, GSPO, or offline RLVR remains untested.
- Sensitivity to hyperparameters (β_v, α, τ, T) and schedules: Although some ablations are referenced in the appendix, the paper lacks a systematic sensitivity study and practical heuristics for robust tuning across models and datasets.
- Stability and interference during joint optimization: The paper argues the MSE self-reward loss minimally interferes with reasoning, but it does not provide training stability analyses (e.g., gradient norms, catastrophic forgetting, mode collapse) or when warm-up schedules fail.
- Class imbalance handling: The simple re-weighting scheme is presented without comparisons to stronger choices (focal loss, per-instance weighting, calibrated class priors). How imbalance varies over training and affects calibration is underexplored.
- Computational overhead and systems constraints: “One additional token inference” is claimed but not benchmarked (wall-clock time, throughput, memory, KV-cache effects, distributed decoding). The practicality at large scale and latency-critical settings is unclear.
- Tokenization and multilingual settings: The approach assumes availability of “unused” tokens and English-centric tokenization. Implications for multilingual models, different tokenizers, or subword segmentations are not addressed.
- Multi-token or chain-of-thought verification: The paper focuses on single-token verification. Whether a lightweight multi-token variant (e.g., brief CoT before verdict) improves calibration or robustness—and at what cost—is an open question.
- Mapping r_s to graded/partial credit rewards: Many verifiable tasks have non-binary outcomes (partial correctness). It is unknown if r_s can be trained to reflect graded rewards reliably.
- OOD and domain-shift calibration: How r_s degrades under domain shift (new datasets, problem styles, unseen reasoning patterns) is not quantified, nor are adaptation strategies (e.g., online recalibration of c_ref or thresholds).
- Interaction with decoding parameters: The dependence of r_s distributions on decoding temperature, nucleus sampling, and sampling budget is not examined. Guidance for stable inference-time scaling across sampling settings is missing.
- Use of r_s for online control: Beyond weighted majority voting, the paper doesn’t explore using r_s for adaptive compute allocation (e.g., stopping rules, dynamic K, reranking, self-reflection triggers), which could further amplify efficiency gains.
- Failure mode analysis: Cases where r_s confidently misjudges (false positives/negatives) are not analyzed. Understanding systematic failure patterns could inform defenses and improved training objectives.
- Reproducibility and variance: Results are presented largely as point estimates. There is no report of variation across seeds, runs, or data shuffles, which limits confidence in robustness claims.
- Scaling to larger models and other architectures: The method is shown on 3B/7B models. It is unknown whether effects persist, diminish, or change at 13B–70B+ scales or with different backbones (e.g., Mistral, Mixtral, Phi, Gemma).
Practical Applications
Overview
The paper introduces LaSeR, a lightweight reinforcement learning method that augments RLVR (Reinforcement Learning with Verifiable Rewards) with a last-token self-rewarding mechanism. It aligns a simple, efficiently computed score—the KL-scaled next-token log-probability for a pre-specified, unused “special token” at the response’s final position—with verifier-based rewards via a mean squared error loss. This enables joint optimization of reasoning and self-verification capabilities with almost no additional inference cost (one extra token), and improves inference-time scaling via confidence-weighted aggregation of multiple solutions.
Below are practical applications that can be derived immediately and longer-term from LaSeR’s findings, methods, and innovations.
Immediate Applications
- Industry (Software/AI Platforms)
- Deploy self-verifying LLMs in production to reduce dependence on external reward models and verifiers.
- Sector: Software
- Workflow/Product: Integrate LaSeR into existing RLVR pipelines (e.g., GRPO, PPO) to train models that output both solutions and internal last-token confidence scores for self-verification; expose a “confidence score” API per completion.
- Assumptions/Dependencies: Access to next-token log-probabilities; capability to set and store a pre-specified unused token; availability of a deterministic verifier for training; KL coefficient tuning; estimation of the constant reference log-probability c_ref.
- Inference-time reranking and aggregation for better accuracy at fixed compute.
- Sector: Software
- Workflow/Product: Implement weighted majority voting across K sampled solutions using LaSeR’s self-rewarding score; use threshold-based gating (accept/high-confidence; reject/low-confidence; escalate to external verifier/human).
- Assumptions/Dependencies: Multiple samples per query; reliable self-rewarding calibration on target tasks; access to logits/log-probs.
- Agent frameworks with self-verification checkpoints.
- Sector: Software; Robotics (planning & tool-use)
- Workflow/Product: Insert “last-token confidence” gates after tool calls or plan steps; if score < threshold, trigger re-plan, ask for another candidate, or consult a verifier/human.
- Assumptions/Dependencies: Deterministic tasks or steps with verifiable outcomes; gating thresholds tuned per task.
- Academia (Model Training & Evaluation)
- Efficient joint optimization of reasoning and verification without two-pass generation.
- Sector: Research
- Workflow/Product: Extend open-source RLVR training (e.g., VerL/TRLX-like toolchains) with LaSeR’s MSE loss; report and compare self-verification F1 alongside Pass@1/Pass@K in papers.
- Assumptions/Dependencies: Training infrastructure; access to verifiable datasets and deterministic verifiers; KL and MSE loss balancing hyperparameters.
- Calibration diagnostics for reasoning models.
- Sector: Research
- Workflow/Product: Use last-token self-rewarding score to analyze calibration (confidence vs correctness), build plots and dashboards, and run ablations across datasets (math, code, logic).
- Assumptions/Dependencies: Verifiable tasks; logging and analytics.
- Policy/Government (Procurement & Assurance of AI Systems)
- Procurement criteria and audit trails using self-verification signals.
- Sector: Public Policy; Compliance
- Workflow/Product: Require vendors to provide self-verification F1 and confidence-weighted aggregation performance; log last-token scores for auditability of automated decisions (e.g., document processing).
- Assumptions/Dependencies: Tasks must have clear verifiers (e.g., form consistency checks, arithmetic validation); privacy-preserving logging.
- Daily Life (Consumer Tools)
- Math/homework assistants with built-in self-check.
- Sector: Education
- Workflow/Product: Tutor apps display a confidence bar from last-token scores; if low, show alternate solutions or ask the student to confirm steps; auto-grade simple verifiable answers.
- Assumptions/Dependencies: Verifiable tasks (numeric/structured answers); UX exposing uncertainty.
- Personal finance and spreadsheet helpers.
- Sector: Finance
- Workflow/Product: Verify calculations (budgets, interest, tax rules) with self-rewarding confidence; flag low-confidence results for manual review.
- Assumptions/Dependencies: Deterministic formulas; configured thresholds.
- Travel and planning assistants checking constraints.
- Sector: Consumer Software
- Workflow/Product: Verify whether generated itineraries satisfy constraints (budget, time windows) and surface confidence; re-run if low confidence.
- Assumptions/Dependencies: Clear constraint verifiers; consistent formatting of outputs.
Long-Term Applications
- Cross-domain, general reasoning with robust self-verification
- Sector: Software; Education; Finance; Legal/Compliance; Healthcare (administrative)
- Product: Extend LaSeR to tasks with structured or programmatic verifiers (code synthesis tests, logic puzzles, rule compliance, contract clause checks, healthcare claims coding).
- Assumptions/Dependencies: Domain-specific verifiers; careful scope control (avoid medical diagnosis/clinical decisions without rigorous validation).
- Unified “dual-role” LLMs acting as both generator and reward model across enterprise pipelines
- Sector: Enterprise AI
- Product: Platform-level APIs where models return solutions and calibrated self-rewarding scores; orchestration uses these scores for routing, retries, and human-in-the-loop triage.
- Assumptions/Dependencies: Organizational standards for thresholds; monitoring and drift detection; periodic recalibration.
- On-device and edge deployment with compute-efficient self-verification
- Sector: Mobile/Edge AI; Robotics
- Product: Small models equipped with LaSeR for local reasoning tasks (sensor data interpretation with verifiable checks, lightweight planners); minimize network calls to external verifiers.
- Assumptions/Dependencies: Access to logits; memory/compute constraints; tasks with deterministic checks.
- Safety, governance, and certification using self-verification signals
- Sector: Policy; Safety Engineering
- Product: Develop standards for reporting last-token self-rewarding calibration; define confidence thresholds for automated actions; certify models for classes of verifiable tasks.
- Assumptions/Dependencies: Standardized benchmarks; legally and ethically vetted use-cases; independent evaluation.
- Data engine and curriculum learning driven by self-rewarding scores
- Sector: Research; MLOps
- Product: Use scores to select hard/easy examples, prioritize mislabeled data, and curate fine-tuning sets; build auto-curriculum pipelines for reasoning tasks.
- Assumptions/Dependencies: Stable calibration; tools for data selection and continuous training.
- Hybrid verification stacks combining LaSeR with external PRMs/generative verifiers
- Sector: Software
- Product: Two-tier systems—use self-rewarding for fast gating; escalate uncertain cases to strong external verifiers; distill high-capacity verifiers into the model via LaSeR-style training.
- Assumptions/Dependencies: Integration infrastructure; domain-appropriate verifiers; distillation recipes.
- Adaptive token and constant strategies to further reduce overhead
- Sector: Research
- Product: Learn or auto-tune the special token z_c and c_ref per model/domain; explore architectures that expose the last-token distribution without extra inference.
- Assumptions/Dependencies: Access to model internals; experiments validating no-loss approximations.
- Multi-agent systems with confidence-weighted collaboration
- Sector: Software; Robotics
- Product: Use LaSeR scores to weight agent votes, assign tasks, or trigger negotiation loops; improve collective reasoning with fewer iterations.
- Assumptions/Dependencies: Agent frameworks; reliable cross-agent calibration; coordination protocols.
- Alternative to large reward models in training pipelines
- Sector: ML Infrastructure
- Product: Reduce need for 72B-class reward models by training models to self-reward; save cost and simplify ops.
- Assumptions/Dependencies: Tasks amenable to verifiable rewards; sufficient performance compared to large RMs in target domains.
- Operations analytics and A/B testing using unified self-verification metrics
- Sector: MLOps
- Product: Standardize dashboards tracking accuracy, Pass@K, and self-verification F1; run A/B tests with confidence-weighted routing.
- Assumptions/Dependencies: Logging; experiment management; stable calibration under distribution shifts.
Notes on feasibility across applications:
- Performance relies on verifiable tasks (rule-based or programmatic checks). For open-ended or subjective tasks, self-rewarding may not correlate with “correctness.”
- Requires model APIs that expose next-token probabilities/logits and allow specifying a reserved special token.
- The c_ref approximation and KL coefficient β_v must be tuned; stability may vary across architectures and domains.
- Calibration should be monitored; thresholds should be set cautiously, especially in safety-critical settings.
Glossary
- Advantage function: A function in policy gradient methods that measures the relative value of an action compared to a baseline under a given state. "where is the advantage function measuring the relative value of the action (i.e., token ) compared to the baseline value under state (i.e., sequence )."
- Chain-of-thought reasoning: The practice of producing intermediate reasoning steps before a final judgment to improve verification and accuracy. "This paradigm has demonstrated stronger verification performance than scalar reward models, as it enables the LLM verifier to conduct deliberate chain-of-thought reasoning before arriving at the final judgment."
- Closed-form solution: An explicit analytical expression for the solution of an optimization objective without iterative computation. "we theoretically reveal that the closed-form solution to the RL objective of self-verification can be reduced to a remarkably simple form: the true reasoning reward of a solution is equal to its last-token self-rewarding score, which is computed as the difference between the policy model's next-token log-probability assigned to any pre-specified token at the solution's last token and a pre-calculated constant, scaled by the KL coefficient."
- Deterministic verifier: A rule-based evaluator that deterministically checks whether a final extracted answer matches the ground truth. "By rewarding reasoning paths based on the consistency between final outcomes and ground-truth answers through a deterministic verifier, RLVR incentivizes LLMs to produce more deliberate reasoning chains while effectively mitigating the risk of reward hacking~\citep{reward_hacking}."
- Generative verifiers: LLM-based verifiers that generate critiques and judgments in natural language to assess solution correctness. "(2) Generative Verifiers: Recent studies have explored the potential of training LLMs to perform natural language critiques of reasoning solutions generated by the LLM generators, and then to judge their final outcomes~\citep{generative_verifiers, LLM-critic-catch-math-bugs, deepcritic, genprm}."
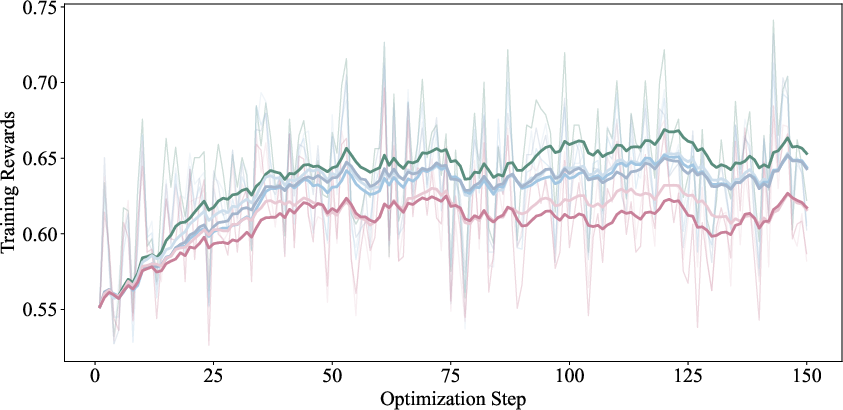
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that estimates baseline value from group-average rewards and computes relative advantages per token. "Group Relative Policy Optimization~(GRPO)~\citep{deepseekmath} estimates the baseline value as the average reward within a sampled group for the same problem, and computes the relative advantage for each token in sequence as"
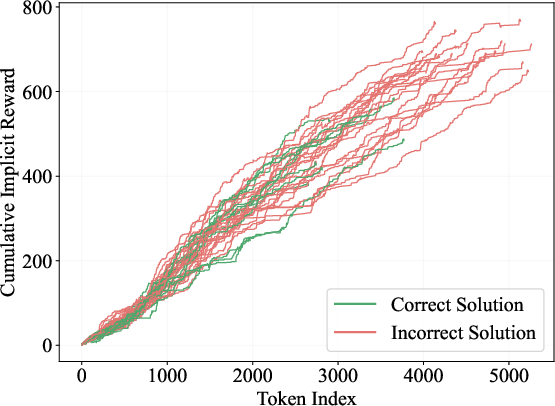
- Implicit reward: The scaled log-probability ratio between the policy and reference models that characterizes the alignment-induced reward signal. "$\beta \log \frac{\pi_{\boldsymbol{\theta}(\boldsymbol{y}|\boldsymbol{x})}{\pi_{ref}(\boldsymbol{y}|\boldsymbol{x})}$ is termed as the implicit reward, which has been used in prior works~\citep{emulated_finetuning,lm_proxy} to analyze the behavioral shift induced by the alignment process."
- Inference-time scaling: Techniques that improve performance at inference by aggregating or weighting multiple generated solutions. "Experiments show that our method not only improves the model's reasoning performance but also equips it with remarkable self-rewarding capability, thereby boosting its inference-time scaling performance."
- KL coefficient: A scalar that scales the KL-related term and, in this work, the self-rewarding score. "scaled by the KL coefficient."
- Kullback–Leibler (KL) divergence: A measure of divergence between probability distributions used as a regularization term in RL objectives. "$\mathcal{D}_{\text{KL}$ is the Kullback–Leibler (KL) divergence loss regularizing the distance between two model distributions."
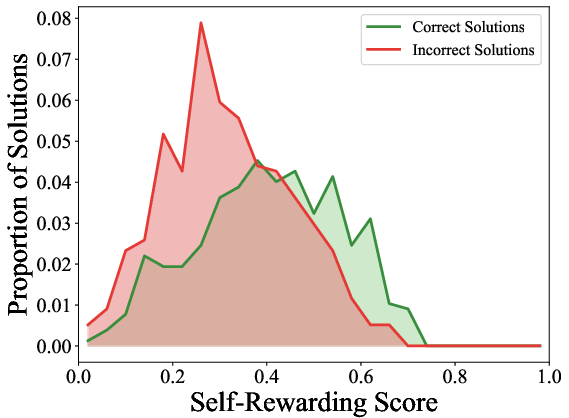
- Last-token self-rewarding score: The scaled log-probability ratio for a pre-specified token at the final response token, serving as a self-verification signal. "We refer the term $r_{s}=\beta_{v} \log \frac{\pi_{\boldsymbol{\theta}(z_{c}|\boldsymbol{x},\boldsymbol{y})}{\pi_{ref}(z_{c}|\boldsymbol{x},\boldsymbol{y})}$ to the last-token self-rewarding score, since it depends on the log-probability distributions of the last token in ."
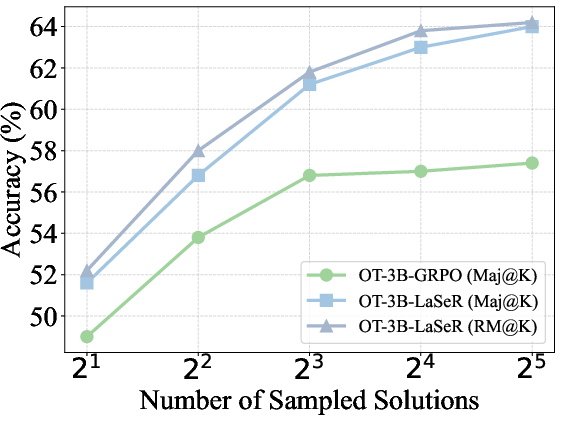
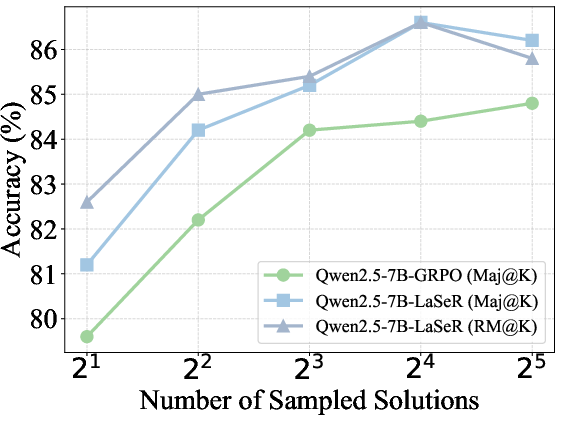
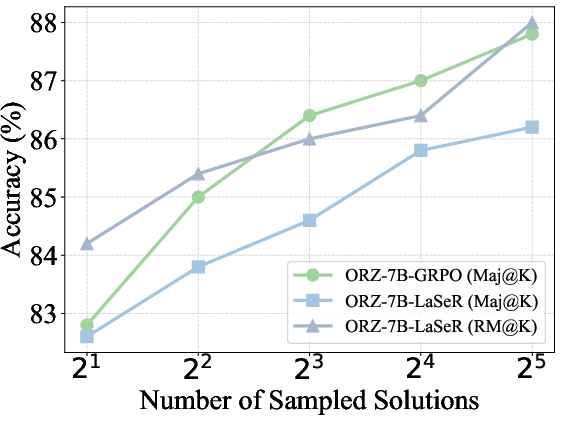
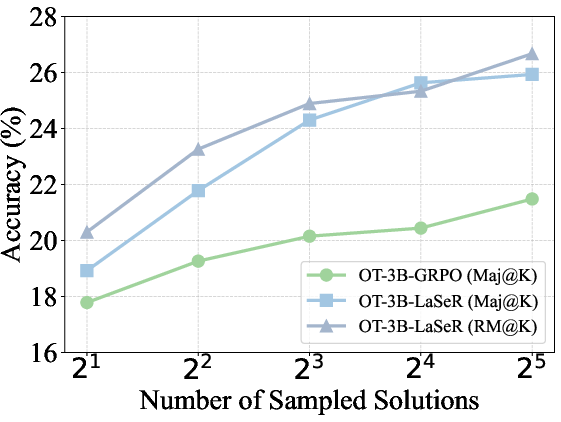
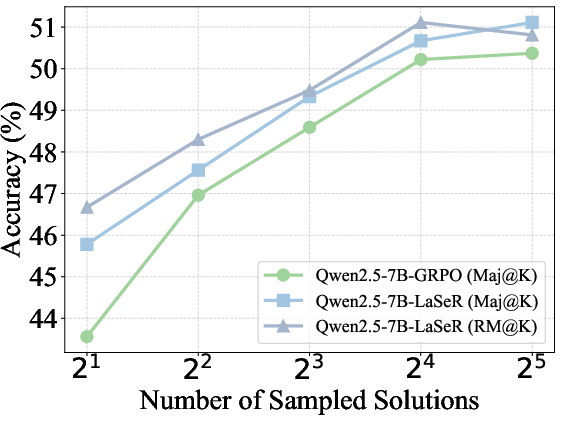
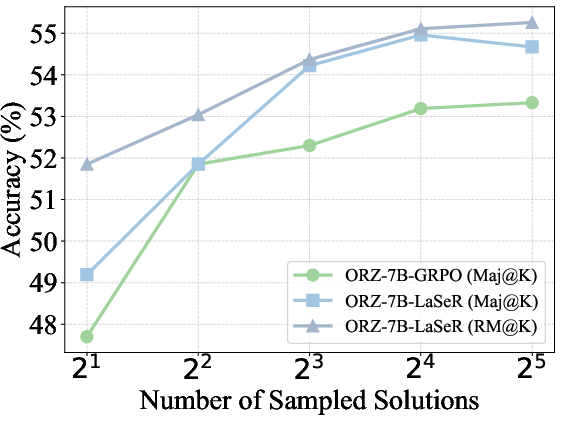
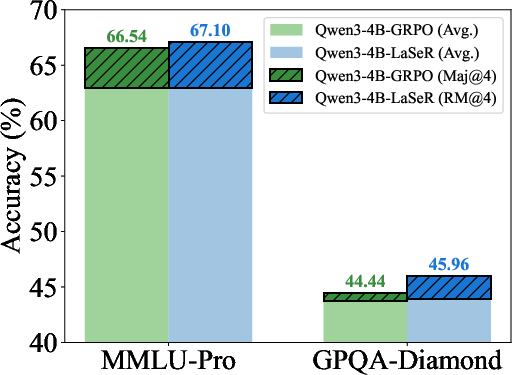
- Majority voting (Maj@K): Selecting the final answer based on the majority among K sampled solutions. "The majority voting (Maj@K) and weighted majority voting (RM@K) results on MATH500 and OlympiadBench."
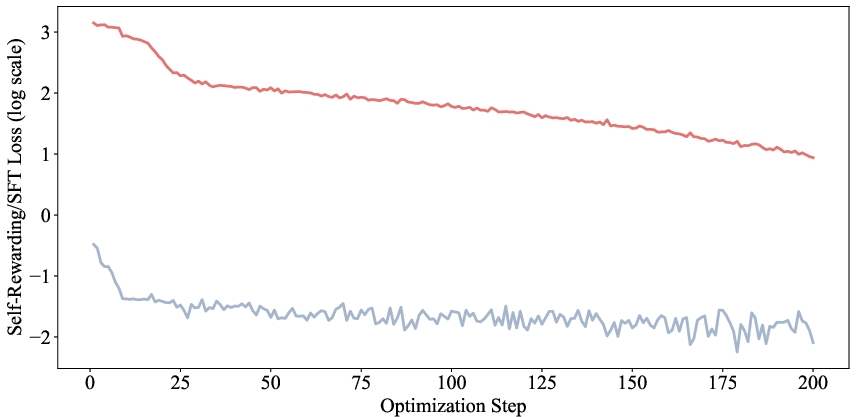
- Mean Squared Error (MSE) loss: A regression objective minimizing the squared difference between predicted and target rewards. "we replace the explicit RL optimization for self-verification with a simple Mean Squared Error (MSE) loss."
- Outcome-supervised Reward Models (ORMs): Reward models trained with supervision based solely on final outcomes. "Outcome-supervised Reward Models~(ORMs)~\citep{gsm8k,qwen2.5-math} and Process-supervised Reward Models~(PRMs)~\citep{prm800k,math-shepherd,skywork-o1,implicitprm} are two representative approaches."
- Partition function: A normalization constant summing over reference probabilities weighted by exponentiated rewards in the RL solution. "where $Z(\boldsymbol{x})=\sum_{\boldsymbol{y} \pi_{ref}(\boldsymbol{y}|\boldsymbol{x}) \exp (\frac{1}{\beta}r_{v}(\boldsymbol{x},\boldsymbol{y}))$ is a partition function."
- Policy Gradient: A class of RL methods that update the policy via gradients of expected rewards. "Policy Gradient~\citep{rl_introduction} is a widely adopted algorithm to optimize the objective of Eq.~(\ref{eq: RL}), which updates the policy model via the estimated gradient"
- Policy model: The LLM being optimized to generate solutions under a policy distribution. "We denote $\pi_{\boldsymbol{\theta}$ as the target policy model to be optimized, and $\pi_{\text{ref}$ as the reference model from which $\pi_{\boldsymbol{\theta}$ is initialized."
- Process-supervised Reward Models (PRMs): Reward models that provide fine-grained feedback by evaluating intermediate reasoning steps. "Outcome-supervised Reward Models~(ORMs)~\citep{gsm8k,qwen2.5-math} and Process-supervised Reward Models~(PRMs)~\citep{prm800k,math-shepherd,skywork-o1,implicitprm} are two representative approaches."
- Reference model: A fixed model used to regularize the policy via KL divergence and to compute probability ratios. "and $\pi_{\text{ref}$ as the reference model from which $\pi_{\boldsymbol{\theta}$ is initialized."
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL paradigm that uses verifiable, often binary, rewards based on final answer correctness to train LLM reasoning. "Reinforcement Learning with Verifiable Rewards (RLVR) has recently emerged as a core paradigm for enhancing the reasoning capabilities of LLMs."
- Reward hacking: Exploiting weaknesses in the reward function to obtain high reward without truly solving the problem. "while effectively mitigating the risk of reward hacking~\citep{reward_hacking}."
- Self-rewarding: A capability where the model derives an internal reward signal (e.g., from last-token probabilities) to assess its own solution. "Experiments show that our method not only improves the model's reasoning performance but also equips it with remarkable self-rewarding capability"
- Self-verification: The model’s ability to evaluate the correctness of its own outputs without external ground truth. "prior studies incorporate the training of model's self-verification capability into the standard RLVR process"
- Supervised Fine-Tuning (SFT) loss: A cross-entropy loss used to train models to predict specific tokens given labels, applied here for verification tokens. "An alternative to train the self-verification capability is to optimize the following supervised fine-tuning (SFT) loss by maximizing the next-token probability of the token or based on the context :"
- Test-time inference: Generating model outputs when ground-truth answers are unavailable, necessitating verification signals. "a limitation of standard RLVR is its inability to continue providing verification signals for model outputs in scenarios where ground truth answers are unavailable, such as during test-time inference~\citep{TTRL}."
- Verifier-based rewards: Rewards computed by a verifier (often rule-based) that indicate correctness of final answers. "an additional MSE loss between the verifier-based rewards () and the last-token self-rewarding scores ()"
- Weighted majority voting (RM@K): Aggregating multiple solutions by weighting each vote according to a reward model or self-rewarding score. "We compare majority voting results with (RM@K) and without (Maj@K) weighting by the last-token self-rewarding scores"
Collections
Sign up for free to add this paper to one or more collections.