Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Abstract: Reinforcement Learning with Verifiable Rewards (RLVR) has recently demonstrated notable success in enhancing the reasoning performance of LLMs, particularly on mathematics and programming tasks. Similar to how traditional RL helps agents explore and learn new strategies, RLVR is believed to enable LLMs to continuously self-improve, thus acquiring novel reasoning abilities beyond those of the corresponding base models. In this study we critically examine the current state of RLVR by systematically probing the reasoning capability boundaries of RLVR-trained LLMs across various model families, RL algorithms, and math, coding, and visual reasoning benchmarks, using pass@k at large k values as the evaluation metric. Surprisingly, we find that the current training setup does not elicit fundamentally new reasoning patterns. While RLVR-trained models outperform their base models at small k (e.g., k = 1), the base models achieve a higher pass@k score when k is large. Coverage and perplexity analyses show that the observed reasoning abilities originate from and are bounded by the base model. Treating the base model as an upper bound, our quantitative analysis shows that six popular RLVR algorithms perform similarly and remain far from optimal in leveraging the potential of the base model. By contrast, we find that distillation can introduce new reasoning patterns from the teacher and genuinely expand the model's reasoning capabilities. Overall, our findings suggest that current RLVR methods have not yet realized the potential of RL to elicit truly novel reasoning abilities in LLMs. This highlights the need for improved RL paradigms, such as continual scaling and multi-turn agent-environment interaction, to unlock this potential.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at a popular way to train LLMs called “Reinforcement Learning with Verifiable Rewards” (RLVR). People often think RLVR helps models learn brand‑new ways to reason, especially for math and coding. The authors test that belief and ask a simple question: does RLVR really teach models new reasoning skills, or does it just make them pick good answers more efficiently from what they already know?
What questions are the researchers asking?
They focus on two main questions, explained in everyday language:
- Does RLVR actually give LLMs new reasoning abilities that go beyond what their original “base” versions can do?
- If not, then what exactly does RLVR change in the model?
How did they study it?
The authors tested many models, tasks, and training methods across math, coding, and visual reasoning. Their key tool is a simple idea called “pass@k.”
- What is pass@k? Imagine you give a model up to k tries to solve a problem. If any try is correct, the model “passes” that problem. For example, pass@1 is like one shot. Pass@128 is like giving the model 128 chances and counting it as solved if it gets it right at least once.
- Why use large k? A single try (pass@1) can underestimate what a model is capable of. With more tries, you test the model’s “upper bound” (its full potential) more fairly. If a base model can eventually find a correct path with enough tries, that means it had the ability all along—it just needed more sampling.
- Verifiable rewards: In math, the final numeric answer must match the truth. In code, the program must pass unit tests. These automatic checks make RL training scale without human grading.
- Checking for lucky guesses: The team filtered out easy-to-guess math questions and manually inspected chains of thought (the model’s step-by-step reasoning) to confirm that correct answers came from valid reasoning, not just random luck.
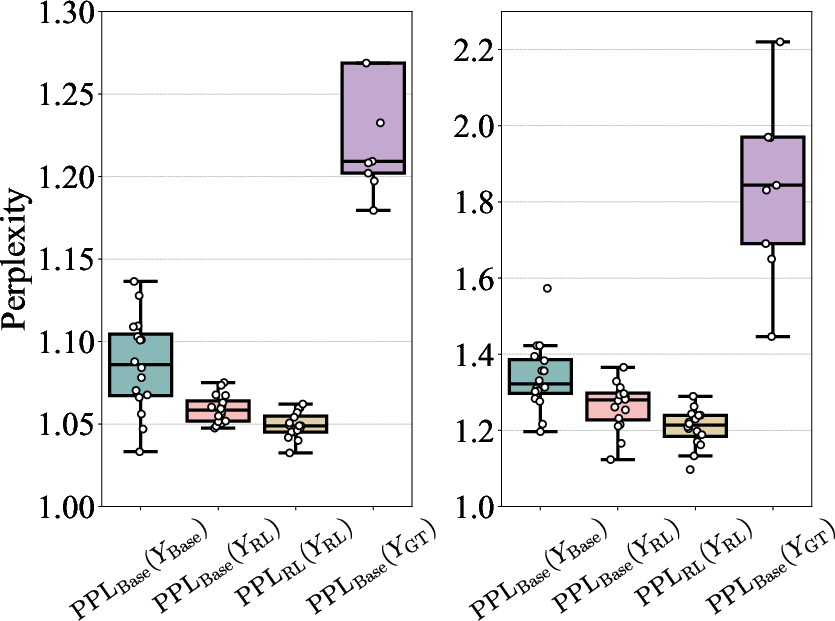
- Perplexity analysis: Perplexity is a measure of “how surprising” a response is to a model. Low perplexity means the model thinks the response is likely. The team used this to see if RL-trained reasoning paths were already likely under the base model’s distribution.
What did they find, and why does it matter?
Here are the main findings, explained simply:
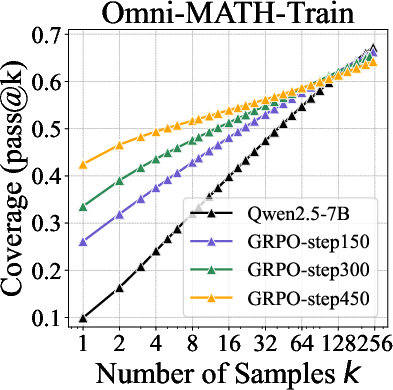
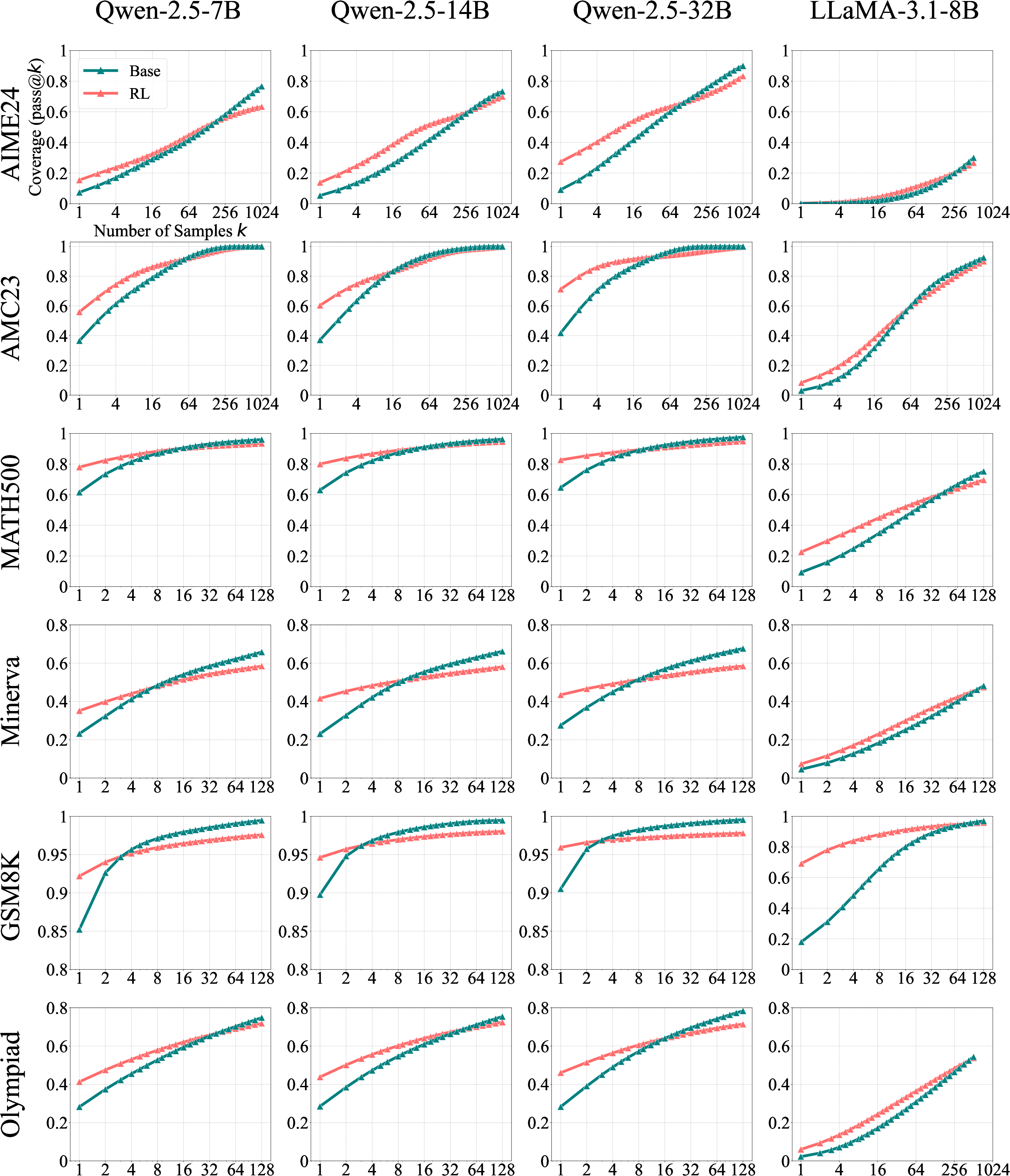
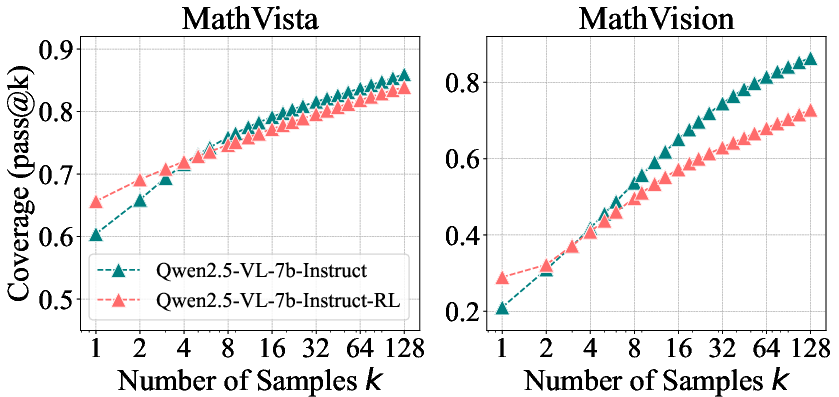
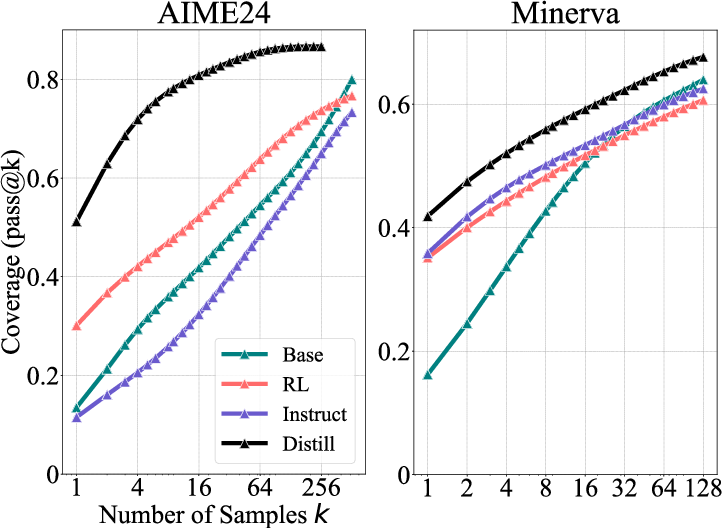
- RLVR boosts accuracy when you only allow a few tries. With pass@1 or other small k values, RL‑trained models often beat their base versions. This means RLVR makes the model “aim” better—it samples correct answers more efficiently.
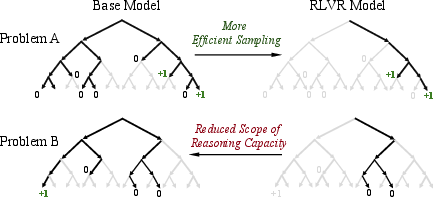
- But at large k, base models catch up and even surpass RL models. When you allow tens or hundreds of tries, base models solve as many or more problems than RL‑trained ones. In other words, the base model could already solve those problems—it just needed more sampling.
- RLVR doesn’t create truly new reasoning paths. The reasoning routes the RL‑trained models use are already inside the base models’ “bag of possibilities.” RLVR mainly reweights the model’s output toward rewarded paths, not inventing new ones.
- RLVR narrows exploration. RL training makes models focus on certain “good” paths, which improves efficiency but reduces how widely they explore. That can shrink the overall set of problems they can solve when you sample a lot (the “reasoning boundary”).
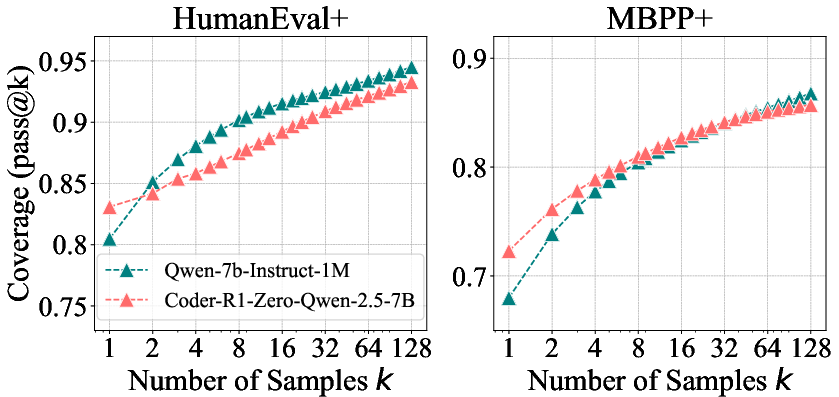
- This pattern holds across math, coding, and visual reasoning. It’s not just one model or one task—the same trend shows up broadly.
- Distillation is different and can add new knowledge. Distillation is like a student learning from a stronger teacher’s detailed solutions. The distilled model often shows a wider reasoning boundary than the base model, suggesting it truly learned new patterns, not just reweighted old ones.
- Different RL algorithms (like PPO, GRPO, RLOO) perform similarly. They all help sampling efficiency a bit, but none are close to the theoretical “upper bound” of what the base model could do with many tries.
- Longer RL training improves pass@1 but can shrink the high‑k boundary. Over time, the model gets better at quick wins but worse at broad exploration.
Why this matters: Many people hope RLVR will make models learn fundamentally new ways to think. This study suggests RLVR mostly helps models pick better from what they already can do, rather than expanding their real reasoning capabilities.
What does this mean for the future?
- RLVR alone may not be enough to push reasoning beyond the base model’s limits. It’s helpful for making models more efficient at finding correct answers quickly, but it may not unlock truly new skills.
- Distillation looks promising for adding new reasoning patterns. Learning from a stronger “teacher” model’s long, worked‑out solutions can genuinely expand a model’s abilities.
- We might need new training ideas. Since language is a huge “action space” (far bigger than games like Go or Atari), and RLVR starts from strong pretrained priors, exploration can get stuck inside what the base model already knows. Future methods should find ways to safely explore beyond the base model’s prior, or use alternative approaches that better inject new knowledge.
In short: RLVR acts like a coach that makes a student pick their best-known strategies faster. Distillation acts like a teacher who actually teaches new strategies. If we want LLMs to truly think in new ways, we’ll likely need more than just RLVR.
Collections
Sign up for free to add this paper to one or more collections.