- The paper demonstrates that negative sample reinforcement (NSR) enhances LLM reasoning by suppressing incorrect answers and reallocating probability mass.
- It details experiments using Pass@k metrics on Qwen2.5-Math-7B and Qwen3-4B, showing NSR outperforms traditional methods like PPO.
- The study introduces Weighted-REINFORCE, a balanced approach combining PSR and NSR to improve performance while preserving output diversity.
The Surprising Effectiveness of Negative Reinforcement in LLM Reasoning
Understanding Reinforcement Learning with Verifiable Rewards
The paper introduces an innovative perspective on reinforcement learning within LMs, focusing on reinforcement learning with verifiable rewards (RLVR). RLVR utilizes a binary system where rewards are either positive (+1) for correct responses or negative (-1) for incorrect ones. This approach is particularly promising for training LMs in tasks that necessitate complex reasoning, such as mathematical problems, where outcomes can be automatically verified.
RLVR is conceptually straightforward and offers notable sample efficiency, allowing models to scale their behaviors during inference. The paper decomposes RLVR into two main components: Positive Sample Reinforcement (PSR), which rewards correct answers, and Negative Sample Reinforcement (NSR), which penalizes incorrect ones.
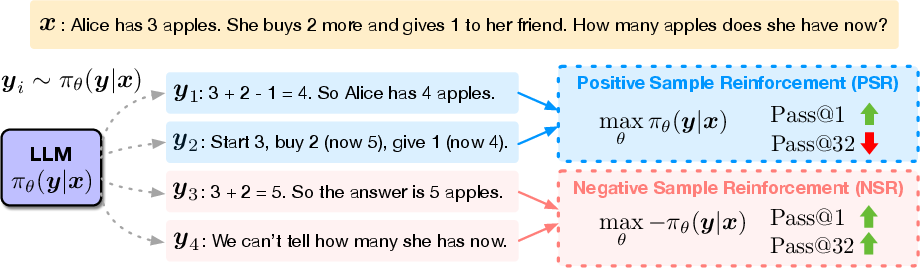
Figure 1: Decomposing learning signals in RLVR into positive and negative reward components. Positive Sample Reinforcement (PSR) increases the likelihood of correct responses but reduces output diversity for large k. Negative Sample Reinforcement (NSR) redistributes probability mass and preserves diversity.
Experimental Setup and Findings
The authors conducted extensive experiments using mathematical reasoning datasets to test the effectiveness of PSR and NSR. Two models, Qwen2.5-Math-7B and Qwen3-4B, were trained using only PSR or NSR. The results were evaluated using Pass@k metrics, which measure the probability of producing at least one correct response in k independent trials.
Remarkably, NSR alone showed a robust performance across all tested k values, often surpassing other methods like PPO and GRPO, which explicitly reinforce correct responses. NSR's approach indirectly reinforces correct answers by suppressing incorrect ones and shifting probability mass toward plausible alternatives.
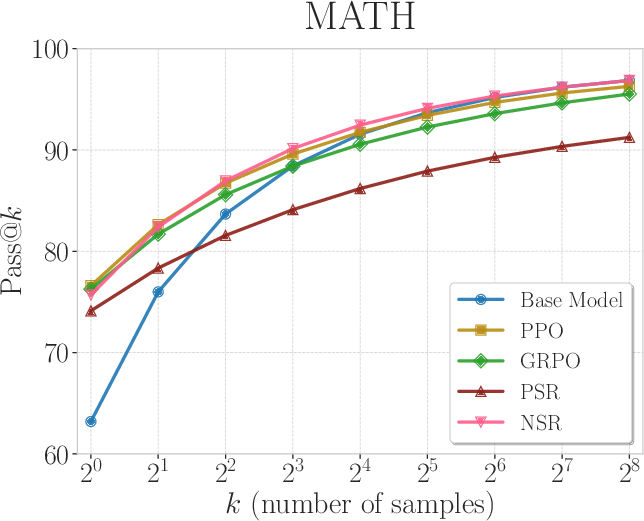
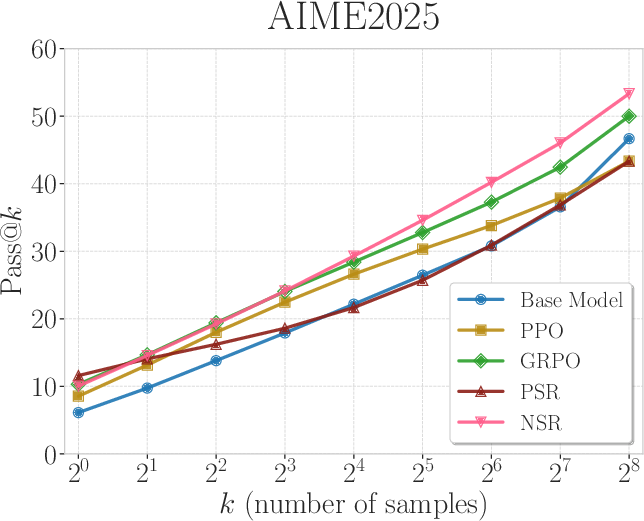
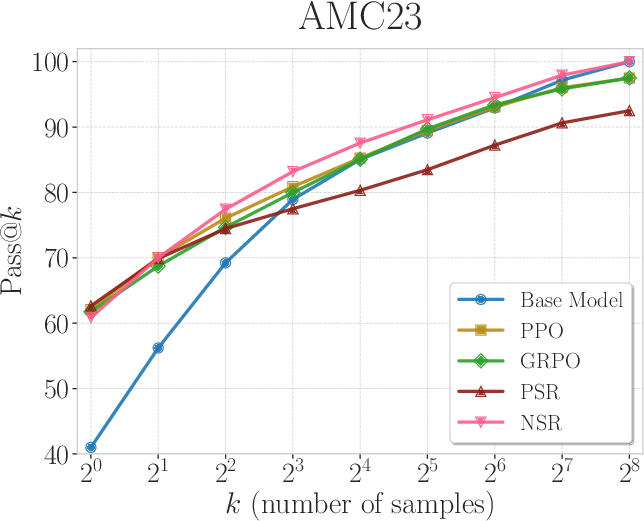
Figure 2: Pass@k curves of Qwen2.5-Math-7B trained with PPO, GRPO, PSR, and NSR. NSR is comparable to other methods across different k values and outperforms them at k=256.
This indirect method enhances the exploration capabilities of the model, maintaining performance even at large k values. Conversely, PSR was observed to improve Pass@$1$, but its output diversity decreased at higher k values.
Gradient Analysis and Insights
The paper explores a token-level gradient analysis to understand the mechanisms behind NSR's effectiveness. NSR's gradients work by demoting the probabilities of incorrect responses and reallocating them to other candidates based on their current probability.
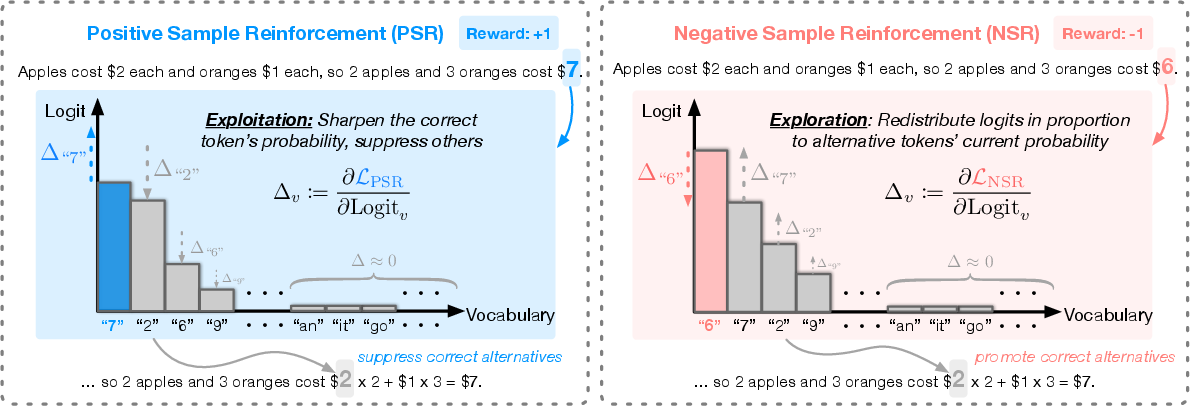
Figure 3: Gradient dynamics of PSR and NSR under a math word problem example. NSR promotes exploration on alternative correct paths and preserves diversity.
This approach preserves high-confidence priors while promoting exploration, allowing the model to refine its knowledge without introducing entirely new behaviors aggressively. The analysis identifies NSR's implicit regularization against overfitting, making it a promising strategy for preserving reasoning diversity.
Weighted-REINFORCE: A Balanced Approach
To balance the strengths of PSR and NSR, the authors propose Weighted-REINFORCE, a modification that adjusts the weight of positive samples in the learning process. This method successfully combines the benefits of both approaches, achieving strong performance on diverse reasoning benchmarks while preserving diversity.
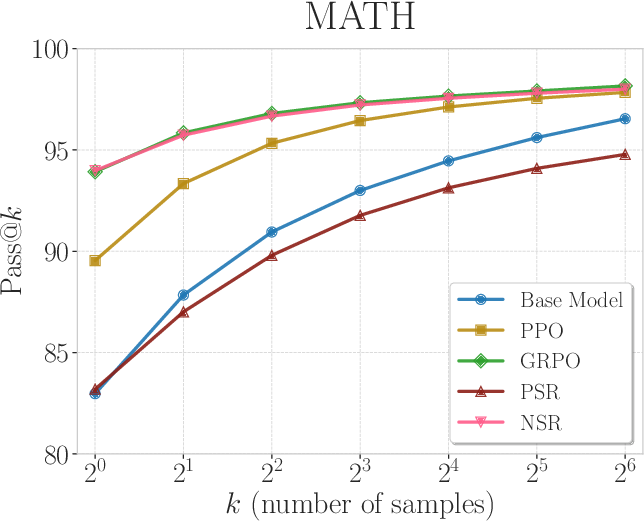
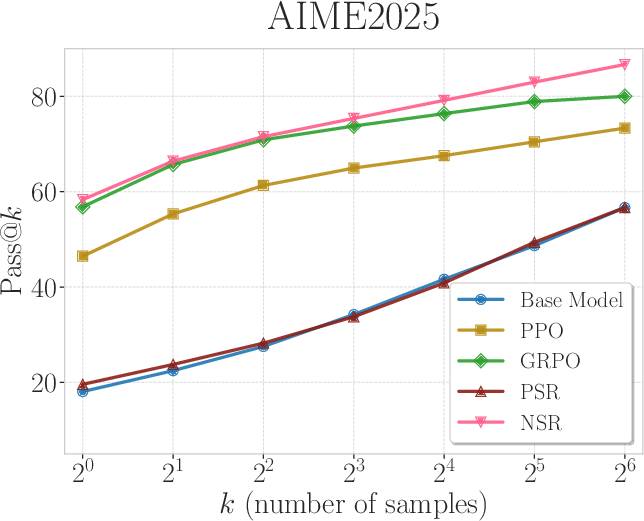
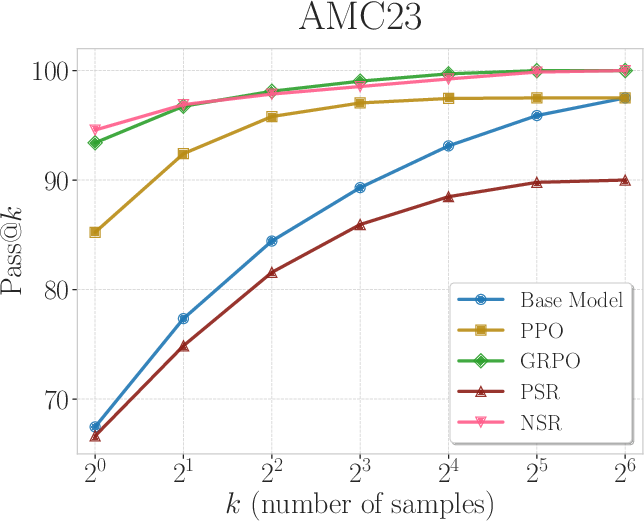
Figure 4: Pass@k curves of Qwen3-4B (non-thinking mode) trained with PPO, GRPO, PSR, and NSR. NSR consistently performs competitively across varying k values, while PSR does not improve the base model.
Implications and Future Directions
The insights from this paper have significant implications for LLM training and reasoning capabilities. They suggest a paradigm shift towards emphasizing negative reinforcement, which could lead to more robust models with enhanced exploratory behaviors.
Future research could explore the application of NSR in diverse settings and investigate how such strategies can be adapted for tasks with dense and nuanced rewards. Overall, the findings highlight the potential of negative reinforcement strategies in refining and improving AI reasoning processes.
Conclusion
The paper offers valuable insights into the role of negative sample reinforcement in LLM reasoning. It demonstrates that NSR alone is a potent mechanism for enhancing performance across the Pass@k spectrum by maintaining output diversity. The proposed Weighted-REINFORCE provides a balanced approach, combining the strengths of both PSR and NSR, opening new avenues for research in reinforcement learning strategies.