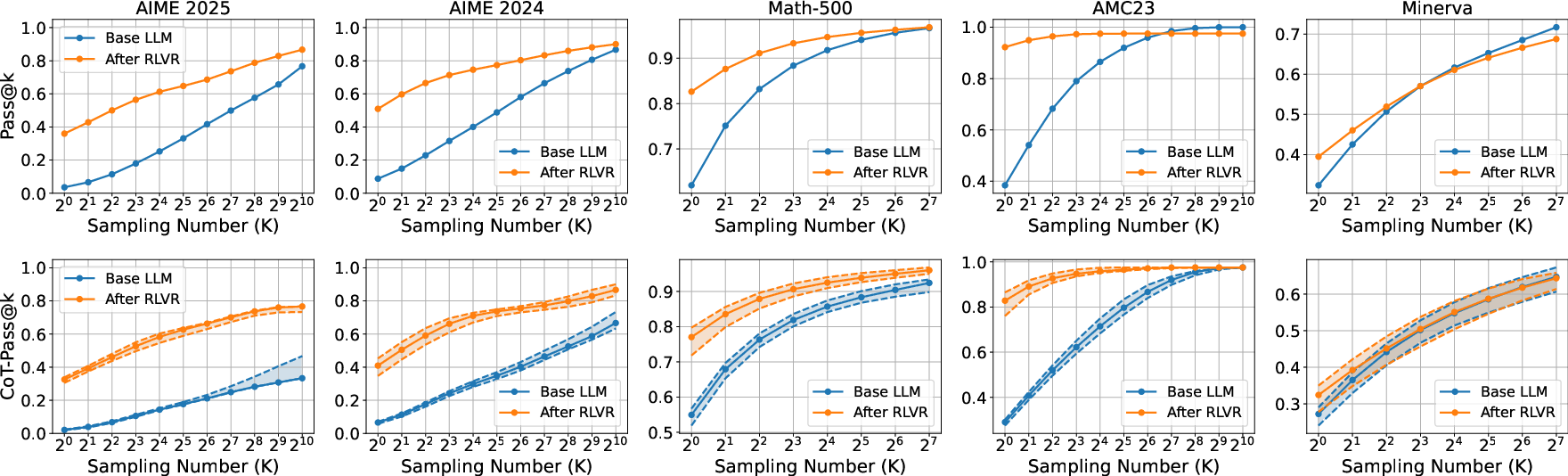
- The paper demonstrates that RLVR incentivizes correct chains-of-thought, leading to significantly enhanced logical reasoning in LLMs.
- It introduces a novel theoretical framework distinguishing RLVR from traditional reinforcement learning methods, emphasizing stable advantage estimation.
- Empirical results on benchmark datasets confirm that RLVR-tuned models achieve superior CoT-Pass@K scores, validating their improved reasoning capability.
Reinforcement Learning with Verifiable Rewards and Reasoning in LLMs
Introduction and Motivation
The paper "Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs" (2506.14245) explores how RLVR can enhance the reasoning capabilities of LLMs. It identifies a critical flaw in traditional metrics, like Pass@K, which focus on final answers without assessing the logical correctness of reasoning paths or chains of thought (CoTs). The paper posits that RLVR, distinct from traditional reinforcement learning methods, inherently promotes logical integrity by focusing on both the correctness of reasoning paths and final outputs.
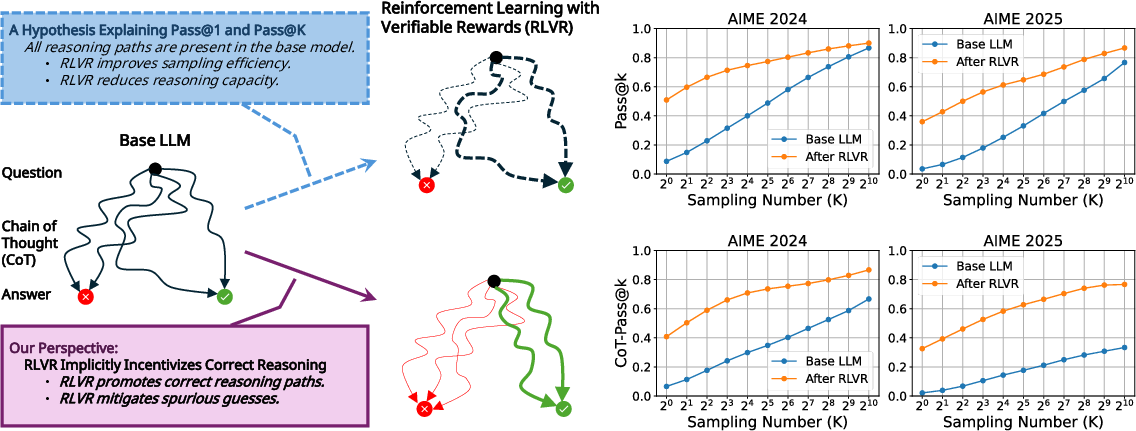
Figure 1: An illustration of RLVR's method encouraging accurate reasoning in base LLMs and varying reasoning paths activated by distinct explanation frameworks.
Theoretical Framework
The paper introduces a theoretical foundation distinguishing RLVR from traditional RL methods. The key assumption of RLVR is its focus on correct CoTs that lead to consistent reinforcement of logical reasoning over mere correct answers. The authors argue:
- Logical Coherence: Correct CoTs have higher probabilities to induce correct answers compared to incorrect CoTs. This is captured by the probability inequality:
P(Ans Correct | CoT Correct)>P(Ans Correct | CoT Incorrect)
- Stable Advantage Estimation: A larger group size for stable advantage estimation in RLVR benefits consistent policy updates.
The theorem developed suggests that RLVR effectively increases the likelihood of generating correct CoTs, hinting at an innate ability to embed logical reasoning into the learning process.
Empirical Validation
The empirical analysis includes an in-depth study of the CoT-Pass@K metric across various benchmark datasets. Using the LLM-as-a-CoT-Judge paradigm, the paper reassesses the performance of RLVR-tuned models against their base counterparts:
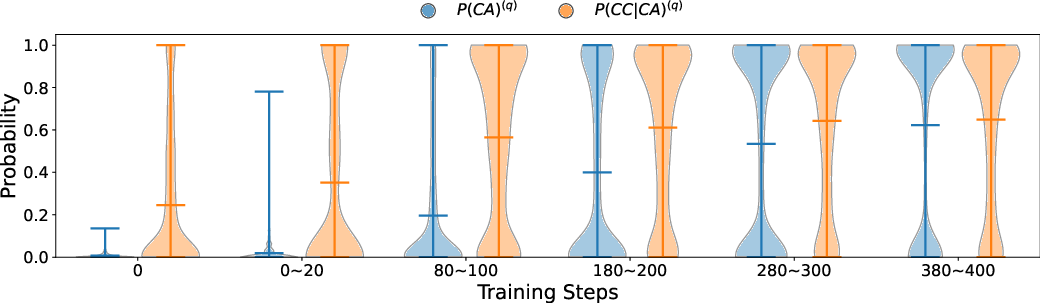
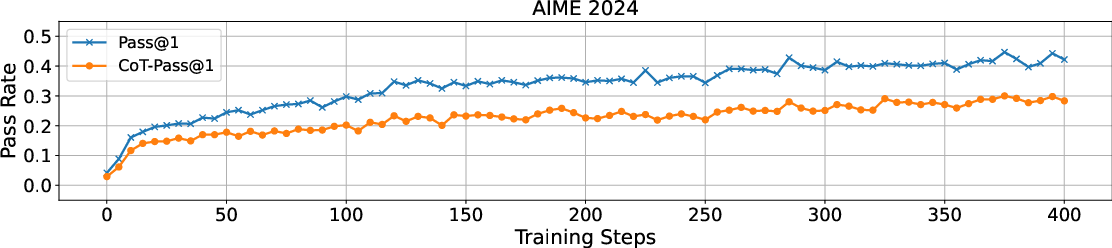
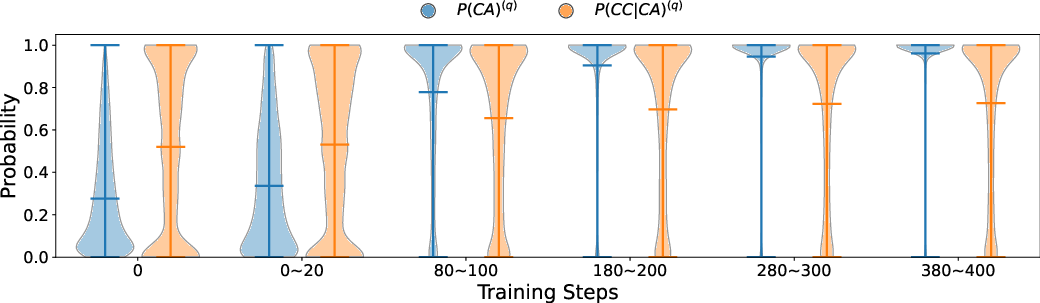
Figure 3: Training dynamics reflecting consistent improvement in incentivized reasoning capabilities in RLVR-tuned models.
Discussions and Implications
The paper acknowledges limitations in using automated verifiers for CoT correctness due to possible false positives/negatives, emphasizing the need for improved verification mechanisms. Importantly, it stresses the significance of live, evolving benchmarks to avoid contamination and accurately gauge the reasoning capacities cultivated by RLVR.
Future directions highlighted include the development of lightweight verifiers for more robust CoT evaluation and the potential of RLVR scaling to match or potentially exceed the transformative progress witnessed with traditional scaling in LLM pre-training.
Conclusion
The investigation into RLVR presented by this paper provides a compelling perspective on enhancing LLM reasoning abilities. By redefining evaluation metrics and emphasizing logical coherence, RLVR showcases its capacity to incentivize correct reasoning pathways. This work lays a solid foundation for advancing LLMs towards genuine logical reasoning alignment and further exploration of RLVR as a pivotal methodology in AI development.