- The paper introduces a novel self-play strategy using variational problem synthesis to maintain policy entropy during RLVR training.
- It generates diverse training datasets by synthesizing new problems from correct model solutions to enhance reasoning capability.
- Empirical results show significant Pass@k performance gains, with up to 22.8% improvement on AIME benchmarks.
Beyond Pass@1: Self-Play with Variational Problem Synthesis Sustains RLVR
Introduction
The paper presents a novel approach, "Self-Play with Variational Problem Synthesis" (SvS), designed to enhance the performance of Reinforcement Learning with Verifiable Rewards (RLVR) in training LLMs for complex reasoning tasks. Standard RLVR improves Pass@1 but often reduces policy entropy, leading to decreased model diversity and limit Pass@k performance improvements. The SvS strategy aims to sustain training diversity and improve Pass@k by enriching training datasets with variational problems generated from the model’s own solutions.
Methodology
The SvS strategy involves a cyclical training process comprising three main stages: original problem solving, variational problem synthesis, and synthetic problem solving.
- Original Problem Solving: The policy attempts to solve problems from the original dataset. Correct solutions lead to identifying challenging problems, which serve as seeds for generating variational problems.
- Variational Problem Synthesis: Correct solutions to challenging problems are used to synthesize new problems that maintain the same answers but vary structurally. This process ensures data diversity without additional verification efforts.
- Synthetic Problem Solving: The policy solves these synthesized problems, promoting exploration and maintaining policy entropy.
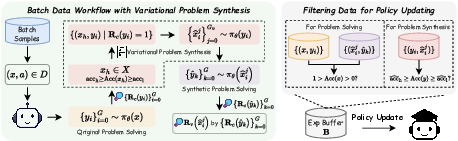
Figure 1: The data workflow of our SvS in a training iteration, comprising original problem solving, variational problem synthesis, synthetic problem solving, and policy update data filtering.
Additionally, reward shaping is employed to ensure these problems remain challenging and accurately assess the policy’s reasoning capabilities.
Results
Experiments conducted on various LLMs (3B to 32B parameters) across 12 benchmarks demonstrate that SvS consistently outperforms traditional RLVR methods, showing an average absolute Pass@32 improvement of 18.3% and 22.8% on the AIME24 and AIME25 benchmarks, respectively.
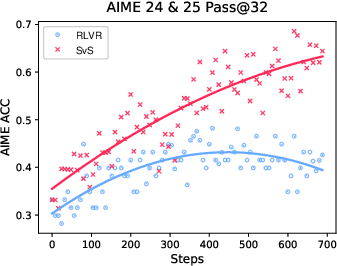
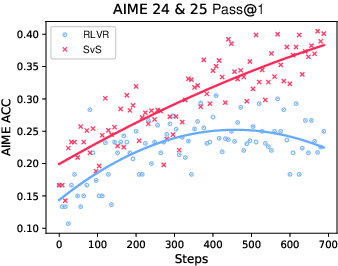
Figure 2: Superior efficiency and effectiveness of SvS strategy on competition-level AIME benchmarks.
The SvS framework sustains entropy throughout training (Figure 3) and enhances Pass@k performance even as k increases to 1024 (Figure 4), indicating an expansion of the model’s reasoning boundaries.
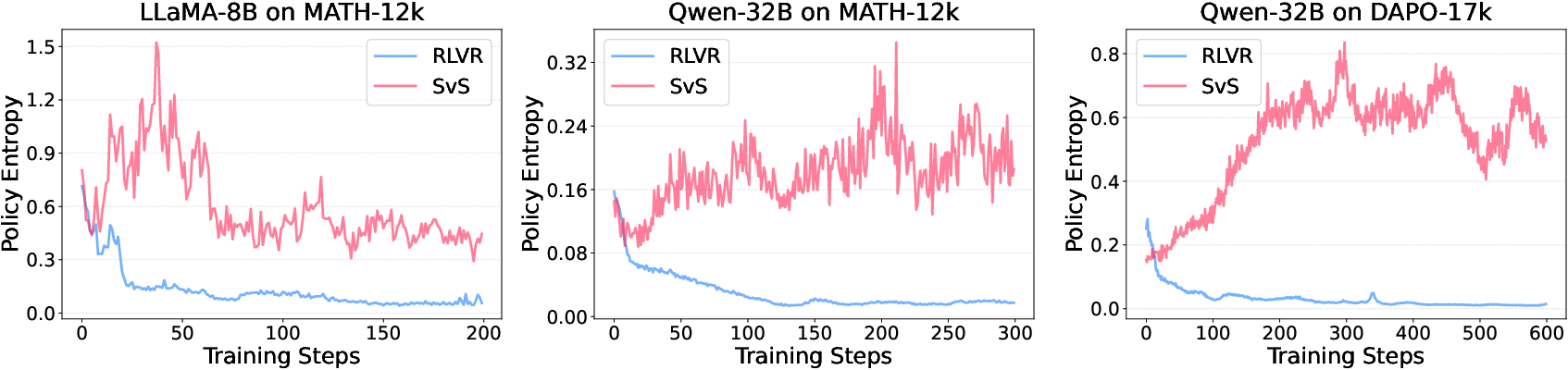
Figure 3: Policy entropy trajectories during training, displaying stability with SvS strategy across models.
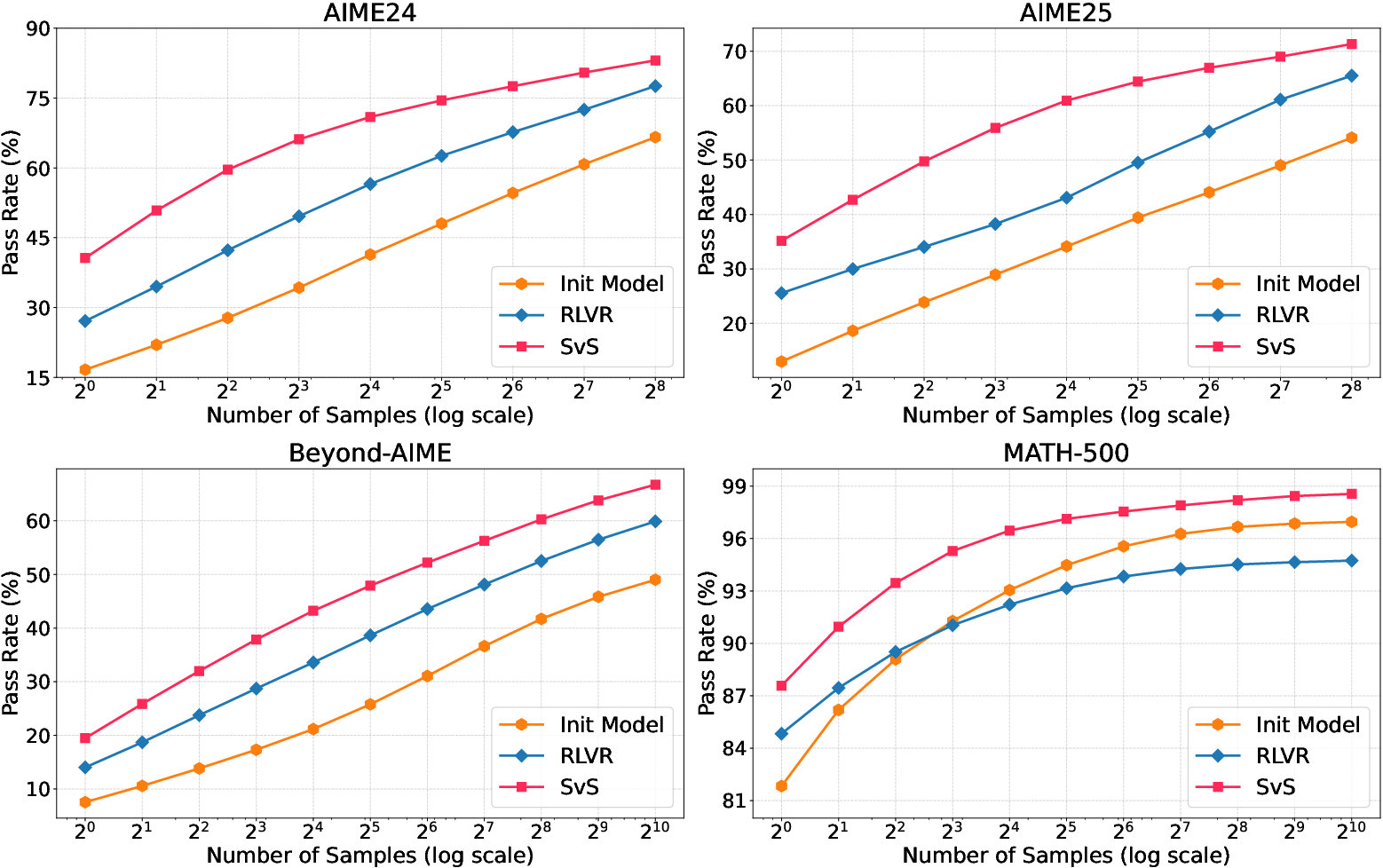
Figure 4: Scaled-up Pass@k performance, showcasing significant gains on benchmarks with larger maximum response tokens.
Analysis
The SvS strategy maintains a stable policy entropy trajectory during RLVR training, facilitating sustained model exploration and mitigating the problem of training collapse seen in standard approaches. This maintenance of entropy correlates with improved exploration and higher reasoning capability thresholds as observed in Pass@k performance increments.
Conclusion
The self-play paradigm of SvS, through online problem augmentation without external guidance, effectively enhances the RLVR training of LLMs. This strategy not only consistently improves problem-solving metrics across various scales and benchmarks but also augments the problem diversity and maintains model engagement with challenging problem landscapes. Future work could explore integrating SvS with other RLVR algorithms to further explore its generalizability and potential in other reasoning-intensive domains.