- The paper demonstrates that minimalist RL techniques using selective sample filtering can match state-of-the-art methods in LLM reasoning tasks.
- It shows that the RAFT algorithm leverages rejection sampling to train with only positively rewarded samples, enhancing efficiency.
- The study highlights variants like Reinforce-Rej which improve KL efficiency and training stability, paving the way for future research.
Minimalist Approaches to LLM Reasoning: Insights from Reinforcement and Rejection Sampling
Reinforcement Learning (RL) has gained prominence as a compelling method for enhancing LLMs in tasks requiring complex reasoning. The paper "A Minimalist Approach to LLM Reasoning: from Rejection Sampling to Reinforce" explores the effectiveness of RL, focusing on mathematical reasoning tasks. This summary explores the methodologies, experimental findings, and implications of the minimalist approaches proposed in the paper.
Methodological Approaches
The paper scrutinizes several RL-style algorithms, particularly GRPO, and proposes alternatives like RAFT and Reinforce-Rej. Notably, the RAFT algorithm employs rejection sampling to train models using only positively rewarded samples, contrasting with GRPO, which utilizes all generated samples with reward normalization techniques to mitigate gradient variance.
RAFT and RAFT++
RAFT, leveraging a simple rejection sampling baseline, capitalizes on using only positive samples for training. It involves generating multiple responses for each prompt, evaluating them against a reward function, and iteratively refining the model using the best-performing samples.
GRPO and Reinforce
GRPO differs from traditional Reinforce by integrating reward normalization techniques to reduce the variance of updates. This approach involves sampling multiple responses per prompt and normalizing the rewards to focus training on the relative advantage of responses.
Reinforce-Rej
Motivated by the insights gained from comparing RAFT and GRPO, the researchers propose Reinforce-Rej. This variant filters both entirely incorrect and entirely correct responses, enhancing the model's KL efficiency and stability during training while remaining simpler and less resource-intensive compared to other RL methods.
Experimental Evaluation
The paper presents extensive experiments using math reasoning benchmarks with models such as Qwen2.5-Math-7B-base and LLaMA-3.2-3B-instruct. These experiments aim to evaluate the performance of various RL algorithms.

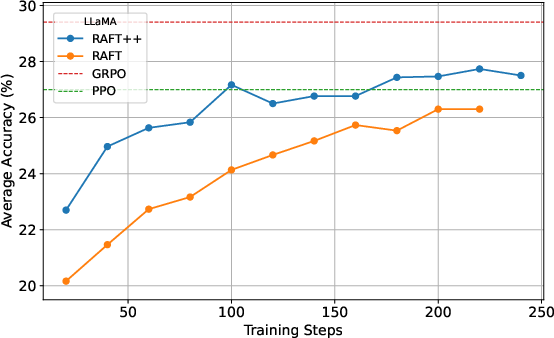
Figure 1: The learning dynamics of RAFT and RAFT++, initialized from Qwen2.5-Math-7B-base and LLaMA-3.2-3B-instruct.
The experimental results demonstrate that RAFT and RAFT++ achieve performance closely paralleling state-of-the-art RL approaches like GRPO, with surprisingly small performance gaps. RAFT++, enhanced by importance sampling and clipping techniques, showed improved training stability and convergence speed during early iterations.
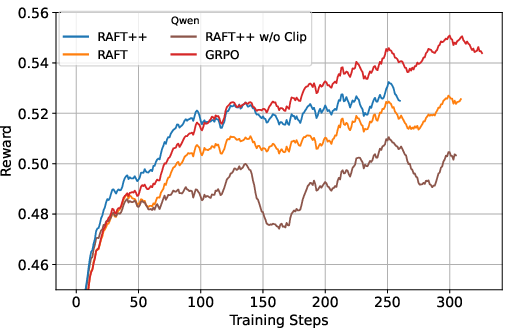
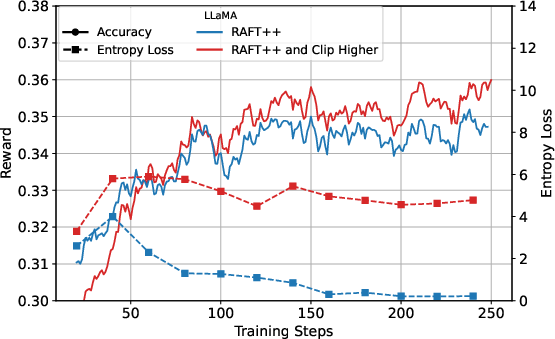
Figure 2: The training reward curves of RAFT, RAFT++, and GRPO, highlighting the effects of clipping and sampling strategies.
Ablation Studies
To understand the impact of individual design choices, the paper conducts ablation studies focusing on sample filtering and reward normalization. The findings suggest that rejecting fully incorrect samples provides notable performance improvements, while mean-zero normalization contributes negligible benefits. The ablation clearly delineates the core strengths of GRPO from sample selection, rather than from normalization per se.
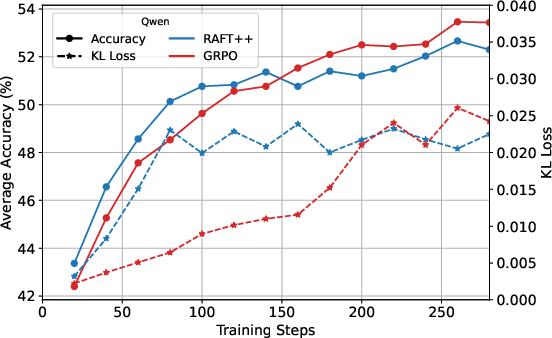
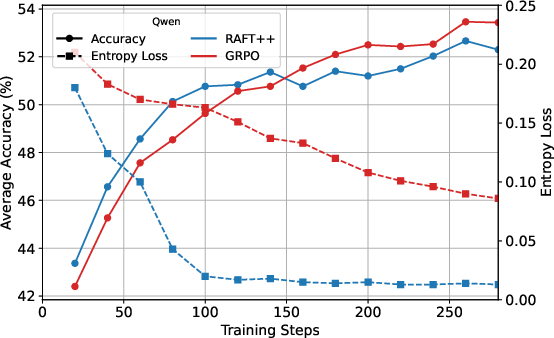
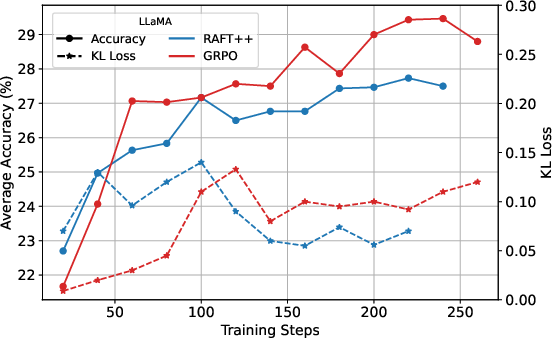
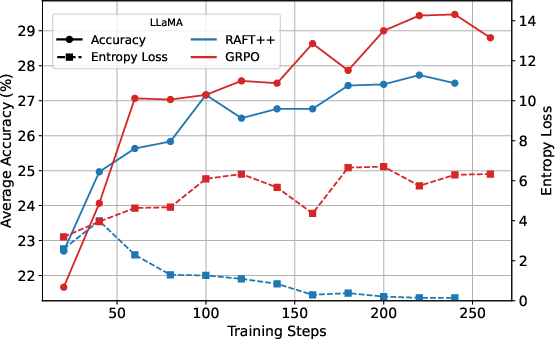
Figure 3: KL loss and policy entropy loss during training for RAFT++ and GRPO, illustrating RAFT++'s rapid entropy decline and eventual stabilization.
Implications and Future Directions
The paper's insights underscore the significance of selective sample utilization in RL-based LLM training. By advocating for minimalist approaches such as RAFT and Reinforce-Rej, the authors suggest that future research in LLM post-training should emphasize methodical sample filtering over algorithmic complexity.
The research highlighted by this paper expands the horizons for RL applications, propelling approaches that maintain simplicity and feasibility without sacrificing performance. This perspective encourages future investigations into the optimization of LLMs through strategic selection and representation of data, fostering both theoretical developments and practical implementations in AI.
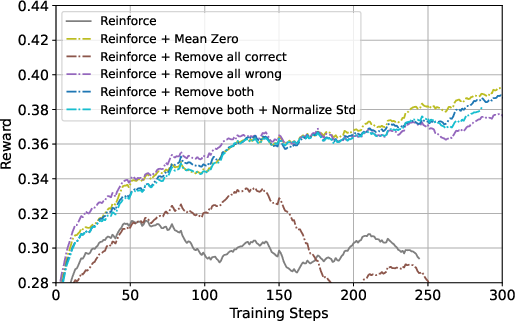
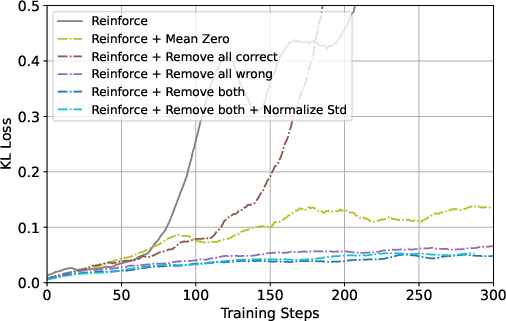
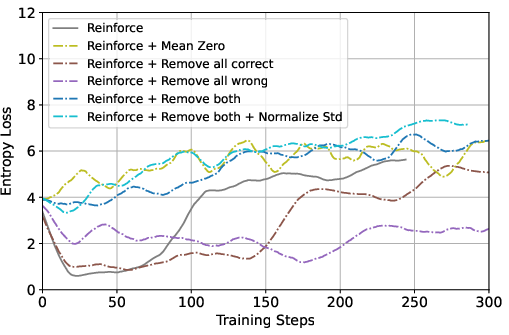
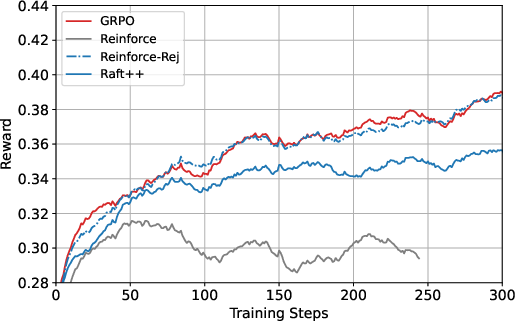
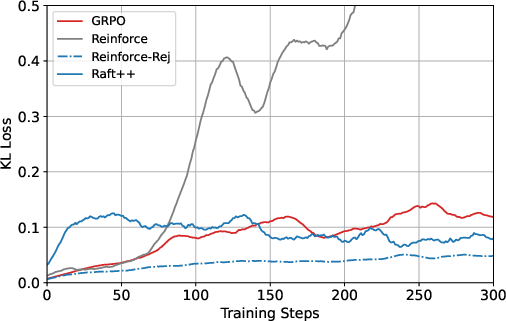
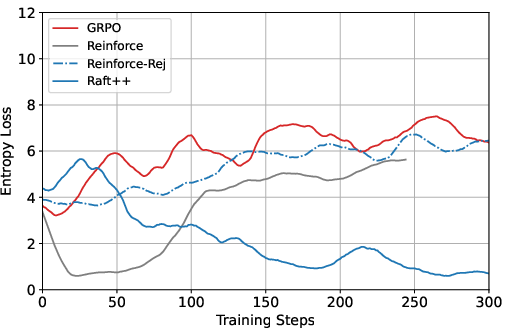
Figure 4: Ablation study results comparing GRPO with various Reinforce-based variants.
Conclusion
In conclusion, "A Minimalist Approach to LLM Reasoning" challenges the assumption that complex reinforcement methodologies are necessary for reasoning tasks. By demonstrating the efficacy of simple and interpretable algorithms like RAFT and Reinforce-Rej, the research provides new pathways for optimizing LLM reasoning. Future work can build on these insights, refining the interaction between RL algorithms and LLMs, potentially leading to more efficient, scalable, and interpretable AI systems.