- The paper introduces Rank-R1, a method that integrates reinforcement learning via GRPO to enhance reasoning in LLM-based document rerankers.
- It employs a novel modified Setwise prompting approach and achieves comparable results with just 18% of the data required for fine-tuning.
- Experimental results on both in-domain and out-of-domain datasets demonstrate that Rank-R1 significantly surpasses traditional zero-shot methods.
Detailed Summary of "Rank-R1: Enhancing Reasoning in LLM-based Document Rerankers via Reinforcement Learning"
Introduction
Rank-R1 introduces an LLM-based reranker designed to enhance reasoning capabilities by integrating RL through a method that leverages Group Relative Policy Optimization (GRPO). The primary aim is to improve document ranking tasks traditionally handled by LLMs, specifically by incorporating reasoning processes that were previously overlooked due to the absence of high-quality annotated reasoning data. This work hypothesizes that effective reasoning improves relevance assessment, thereby advancing ranking capabilities. Evaluations on datasets like TREC DL and BRIGHT demonstrate the method’s superior efficacy, particularly against zero-shot and traditional fine-tuning methods.
Methodology
LLM Reranking
The core mechanism behind Rank-R1 is its modified Setwise prompting approach. Unlike traditional Setwise prompts that directly request identification of the most relevant document, Rank-R1 modifies these prompts to encourage reasoning by including instructions adapted from DeepSeek-R1-Zero. This aims to unlock a higher reasoning potential of LLMs, facilitating a more informed document selection process.
Reinforcement Learning with GRPO
GRPO is utilized to optimize the reasoning process in LLMs, building on instruction-tuned models. This choice circumvents the need for extensive human-annotated reasoning data, using only relevance assessments to guide learning. The objective function of GRPO focuses on increasing rewards associated with accurate document relevance predictions while maintaining output format fidelity. This is achieved without additional external reasoning data, enhancing both reasoning quality and reranking effectiveness.
Experimental Settings and Datasets
Experiments were conducted using the MS MARCO passage ranking dataset for training, with evaluations on TREC-DL19, DL20 (in-domain), and the BRIGHT dataset (out-of-domain). The BRIGHT benchmark especially challenges LLMs with domains requiring sophisticated reasoning, such as biology and mathematics. Initial document retrieval was performed using BM25, with Rank-R1 subsequently reordering the top 100 documents.
Results
In-Domain Effectiveness
Rank-R1 demonstrates comparable effectiveness to supervised fine-tuning approaches when tested on in-domain datasets like TREC-DL19 and DL20. Significantly, Rank-R1 achieves these results using only 18% of the data required for fine-tuning, showcasing its data efficiency. The introduction of reasoning instructions elevates the performance of zero-shot methods, particularly evident in smaller models where incorporating reasoning processes results in substantial effectiveness gains.
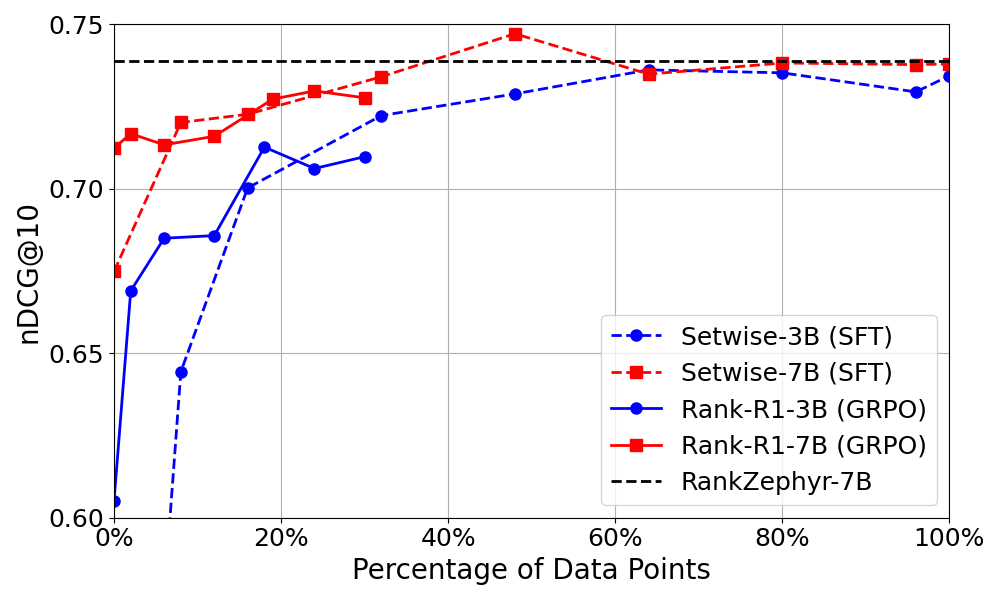
Figure 1: Data efficiency comparison between Setwise SFT and Rank-R1.
Out-of-Domain Generalization
On the BRIGHT dataset, which demands enhanced reasoning abilities, Rank-R1, particularly with a 14B model, notably surpasses zero-shot and supervised ranking methods. This underscores the benefits of incorporating reasoning into LLM-based ranking tasks, enhancing their adaptability to diverse and complex queries that traditional methods may struggle with. The performance also highlights the potential of large-scale models when paired with effective reasoning paradigms.
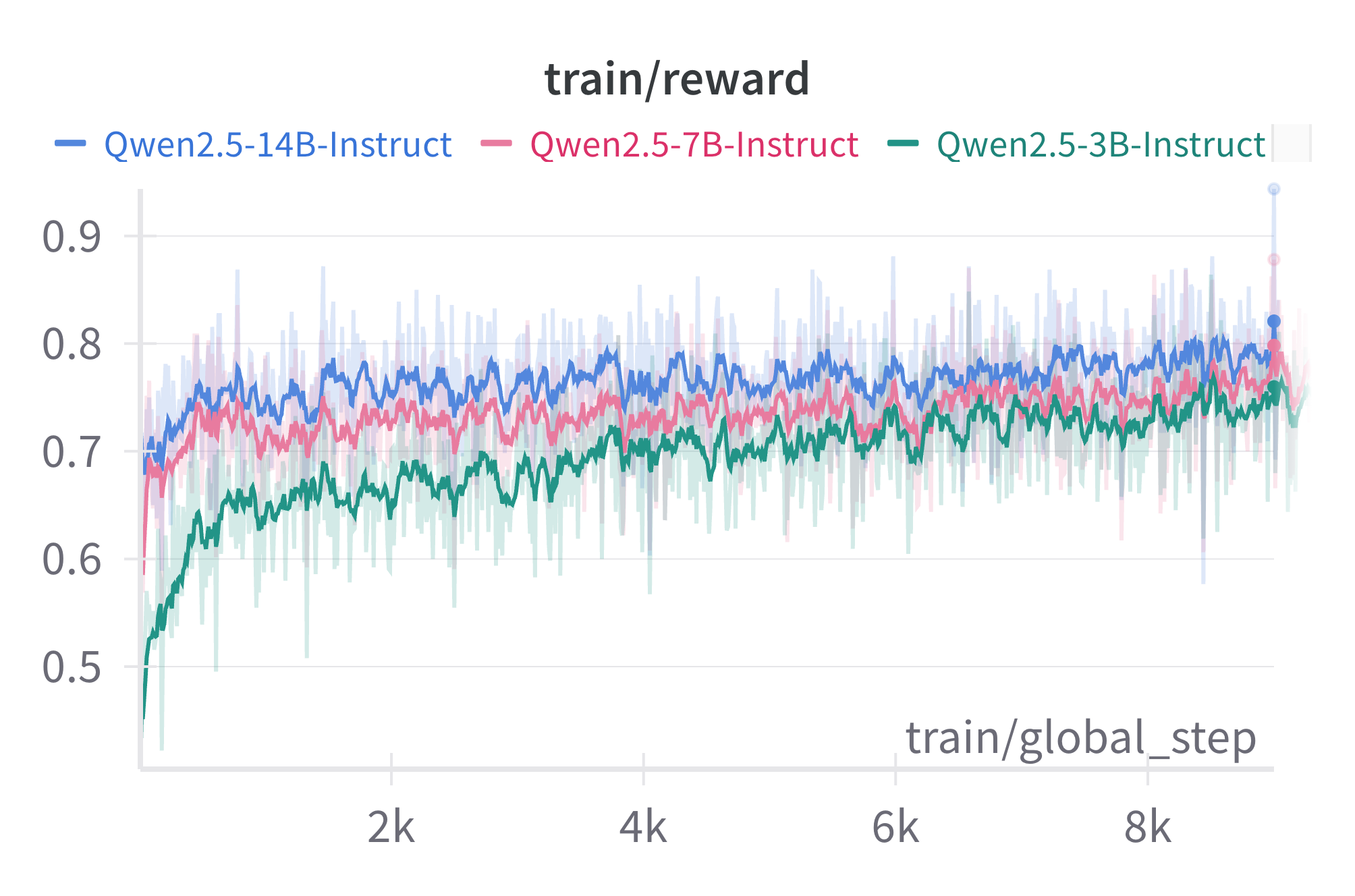
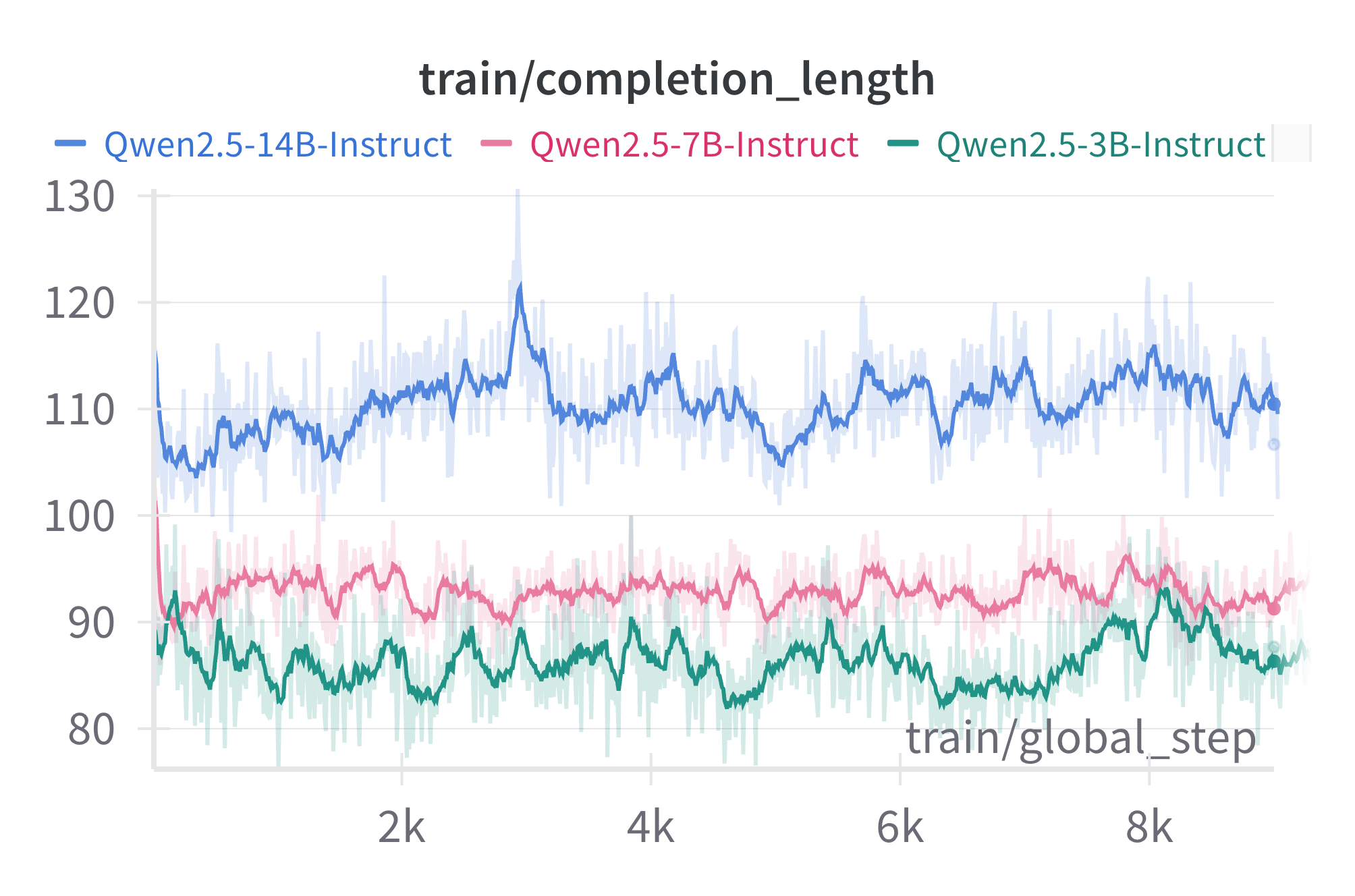
Figure 2: Rewards (top) and model completion length (bottom) obtained during GRPO training.
Implications and Future Directions
The Rank-R1 model illustrates notable improvements in both in-domain and cross-domain ranking tasks through its sophisticated reasoning capabilities, facilitated by GRPO. Its efficiency and adaptability suggest promising directions for incorporating RL-based reasoning in LLMs for tasks requiring nuanced decision-making and relevance comprehension. Future research could explore further optimization of RL parameters or integration with other advanced LLM frameworks to extend these advantages across more varied IR tasks.
Conclusion
Rank-R1 significantly advances the capability of LLM-based document ranking by embedding reasoning into the reranking process, thus bridging the gap between raw retrieval power and intelligent selection that mirrors human-like reasoning. By leveraging RL, particularly GRPO, Rank-R1 demonstrates substantial improvements with reduced data requirements, offering a path forward in efficient and effective document reranking methodologies.
This paper and its contributions can be accessed through its open-source code available at the provided GitHub repository.