- The paper introduces Rearank, a listwise reranking agent that leverages reinforcement learning to integrate reasoning into passage ranking.
- The model employs reinforcement learning with data augmentation to achieve performance comparable to GPT-4 despite limited labeled data.
- Experimental results show enhanced in-domain and out-of-domain performance along with improved, transferable reasoning capabilities.
REARANK: Reasoning Re-ranking Agent via Reinforcement Learning
Introduction
The paper "REARANK: Reasoning Re-ranking Agent via Reinforcement Learning" introduces Rearank, a novel approach leveraging a LLM optimized for listwise passage reranking. By incorporating reasoning before reranking, Rearank not only enhances performance but also improves interpretability. The strategy relies on reinforcement learning (RL) and data augmentation techniques to efficiently train with minimal labeled data, achieving notable results on standard information retrieval benchmarks.
Methodology
The central innovation of Rearank is its use of listwise reranking, guided by reasoning and trained under an RL framework. This differs from traditional reranking methods by utilizing reinforcement signals to adjust the list order based on reasoning processes, which are explicitly generated during reranking tasks.
Listwise Re-ranking Agent: The task involves receiving a set of retrieved passages in response to a query and finding the optimal permutation of these passages. This process is modeled as a Markov Decision Process within an RL framework where the permutation of passages that maximizes the ranking function is identified.
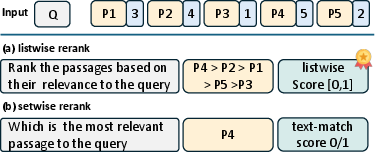
Figure 1: Listwise vs. Setwise Reranking. Setwise reranking yields binary scores (0 or 1); listwise reranking offers richer, continuous scores between 0 and 1.
Reinforcement Learning Approach: The RL method trains an LLM to optimize listwise reranking using a consistent reinforcement signal. This is achieved with the Grouped Policy Optimization (GRPO) algorithm, which samples multiple outputs for each query and evaluates them using a composite reward function. This methodology enables robust learning from only 179 labeled training samples.
Experimental Results
In-Domain and OOD Performance: Rearank demonstrates significant improvements over existing baselines in both in-domain (e.g., TREC-DL) and out-of-domain (OOD) benchmarks. Remarkably, it achieves performance levels comparable to GPT-4, even surpassing it on reasoning-intensive tasks such as the BRIGHT benchmark, despite far less training data.
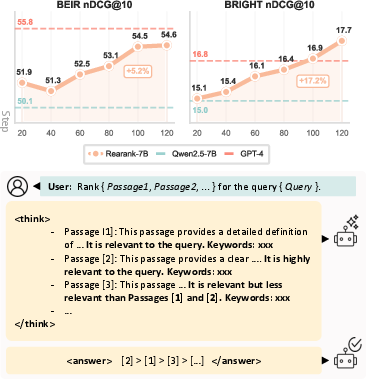
Figure 2: (Top) Average rerank results on popular benchmarks (BM25 top 100); performance improves with RL training; (Bottom) Rearank inference example.
Evaluation and Analysis
Reward Signal Curves: Detailed analysis indicates that the normalized reward signal offers the most stable and informative reinforcement signal, enhancing the RL training process. The model's reasoning capabilities are affected and can transfer to other reasoning tasks, such as mathematical problem-solving.
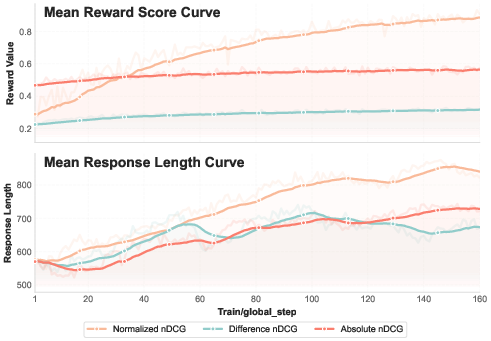
Figure 3: (Top) Reward evolving curve (Bottom) Response length curve.
Reasoning Patterns and Transferability: The reasoning abilities learned in Rearank are transferable, showing improvements in related reasoning tasks. The paper highlights that structured and interpretable reasoning processes are part of what differentiates Rearank's effectiveness from less specialized models.

Figure 4: Reasoning patterns: Before- vs. After-RL training under identical prompt and query.
Conclusion
Rearank demonstrates the effective integration of reasoning and LLMs using RL to enhance passage reranking tasks. This framework not only matches but sometimes surpasses models like GPT-4 on demanding benchmarks with minimal labeled data. The study provides a blueprint for developing efficient, interpretable, and highly capable reranking agents, suggesting promising directions for future research in improving AI reasoning capabilities and application scope.