- The paper introduces Search-R1, which integrates reinforcement learning with search engine interactions to enable iterative reasoning.
- It uses retrieved token loss masking and outcome-based rewards to stabilize training and improve accuracy on QA tasks by up to 24%.
- Experimental results on multiple datasets demonstrate that both base and instruct models benefit, achieving significant performance gains.
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Introduction
The paper introduces Search-R1, a reinforcement learning (RL) framework designed to enhance LLMs by enabling effective interaction with search engines. This is an effort to address the challenges LLMs face in integrating up-to-date external knowledge, particularly crucial for reasoning and text generation tasks.
Approach
Reinforcement Learning Integration
Search-R1 adopts reinforcement learning techniques to optimize the reasoning trajectories of LLMs, incorporating search engine interactions within the decision-making process. By modeling search engines as part of the RL environment, Search-R1 enables multi-turn query generation and retrieval, essential for complex problem-solving.
Key Innovations
- Interleaved Reasoning and Search: Search-R1 allows LLMs to perform iterative reasoning in conjunction with search engine calls, adapting its retrieval strategies dynamically based on the complexity of the tasks.
- Retrieved Token Masking: The framework employs loss masking for retrieved tokens during optimization to stabilize RL training, preventing unintended learning dynamics from influencing performance.
- Outcome-Based Reward Function: The reward design is straightforward, relying on outcome-based metrics rather than complex intermediate reward structures, thereby simplifying the training process.
Experimental Setup
The efficacy of Search-R1 is validated through experiments on seven question-answering datasets. The framework shows significant performance improvements of 24% for Qwen2.5-7B and 20% for Qwen2.5-3B over existing retrieval-augmented generation (RAG) methods.
Results and Analysis
Search-R1 demonstrated superior performance across both in-domain and out-of-domain datasets compared to multiple baselines including Chain-of-Thought (CoT) reasoning and RAG:
- Qwen2.5-7B: Achieved an average improvement of 24% relative to baseline methods.
- Qwen2.5-3B: Noticed a 20% improvement across evaluation metrics.
Comparative Study of RL Methods
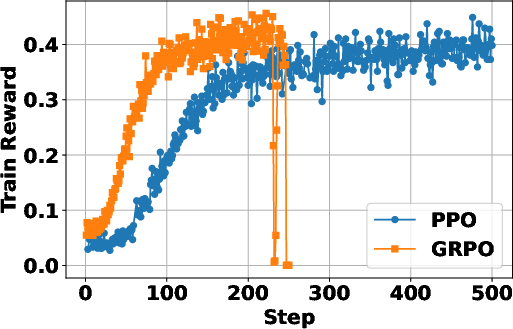
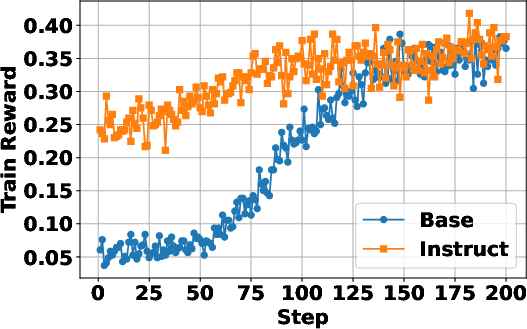
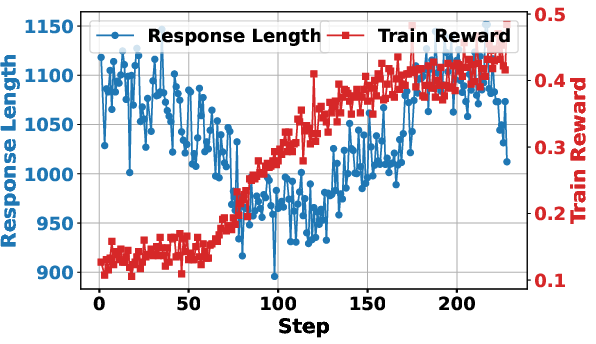
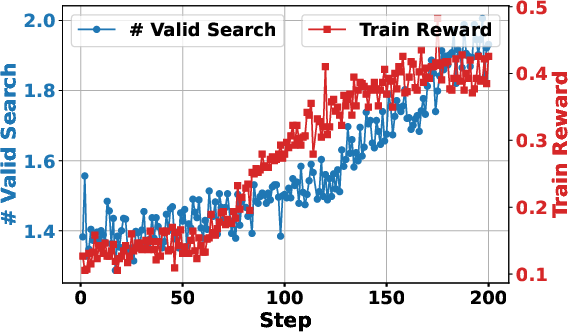
Figure 1: (a) GRPO converges faster but may exhibit instability post-convergence, while PPO maintains stable optimization at a slower rate.
In terms of RL methods, PPO was shown to provide more stable training dynamics compared to GRPO, which, although faster, tended to suffer from post-convergence instability.
Base vs. Instruct Models
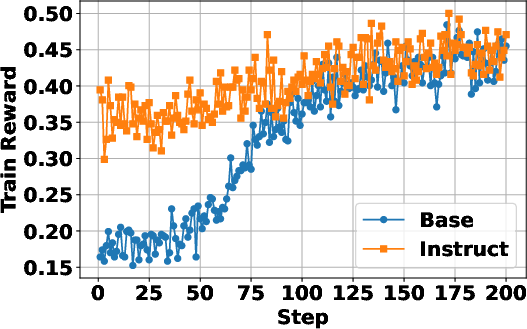
Figure 2: Instruction-tuned models show faster convergence, yet both base and instruct models achieve similar final performance.
Both base and instruction-tuned models benefit from Search-R1, with instruct models converging faster but ultimately reaching similar performance levels post-training.
Token Loss Masking Study
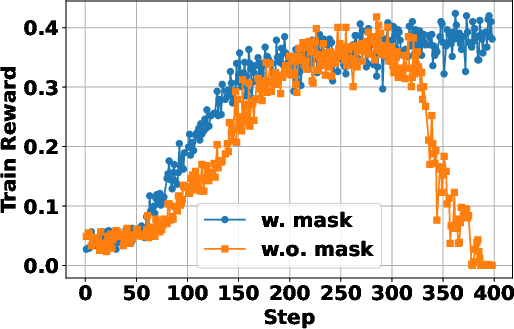
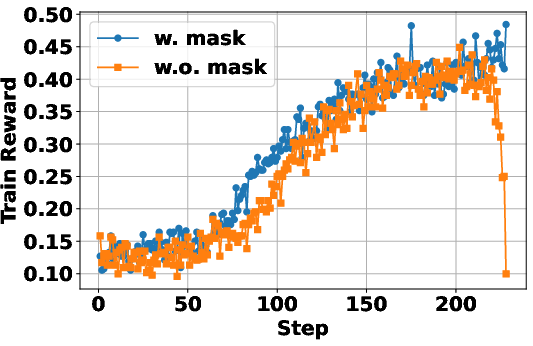
Figure 3: Training with retrieved token loss masking greatly stabilizes the learning process and improves final performance outcomes.
The application of token loss masking for retrieved content was critical for stabilizing the optimization process, ensuring only LLM-generated tokens were affected by the policy gradient updates.
Implications and Future Work
This research underscores the potential of RL frameworks like Search-R1 in enhancing LLM functionalities. By integrating a real-time search component, models can effectively augment the knowledge available at inference time, which is particularly crucial for tasks with rapidly evolving information.
Looking ahead, expanding the framework to involve more varied retrieval strategies and exploring more sophisticated reward mechanisms could provide deeper insights. Moreover, integrating multimodal data sources via a similar RL paradigm could broadly extend the applicability of these findings.
Conclusion
Search-R1 represents a significant advance in bridging the gap between internal reasoning capabilities of LLMs and their need for up-to-date external knowledge. It offers a robust framework for augmenting the reasoning processes of LLMs through dynamic interaction with search engines, thereby setting a foundation for future exploration in RL-based retrieval-augmented learning architectures.