- The paper introduces SSRL, a framework that leverages LLMs as implicit world models to simulate search tasks in reinforcement learning without external search engines.
- It demonstrates that repeated sampling notably boosts predictive performance, narrowing performance gaps between small and large models.
- Empirical results reveal that SSRL improves training efficiency by up to 5.5× and enhances sim-to-real transfer, making RL training more cost-effective and robust.
Self-Search Reinforcement Learning: Leveraging LLMs as Implicit World Models for Search-Driven RL
Introduction
This paper introduces Self-Search Reinforcement Learning (SSRL), a framework that enables LLMs to act as efficient simulators for agentic search tasks in reinforcement learning (RL) by leveraging their internalized world knowledge. SSRL eliminates the need for costly interactions with external search engines during training, instead relying on the LLM's parametric knowledge and structured prompting to simulate the search process. The work systematically quantifies the intrinsic search capabilities of LLMs, explores scaling laws for repeated sampling, and demonstrates that SSRL-trained models can serve as robust, cost-effective environments for RL agent training with strong sim-to-real transfer properties.
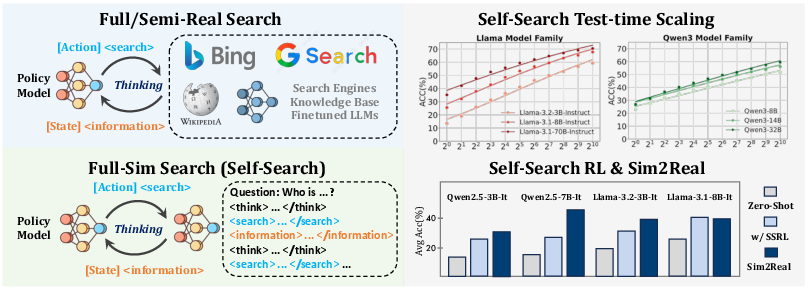
Figure 1: Comparison of prior methods relying on external sources (left) and the proposed full-sim search paradigm (right), where the policy model generates information internally. SSRL further boosts results, especially for sim-to-real generalization.
Quantifying Intrinsic Self-Search Capabilities
The authors first establish a rigorous evaluation protocol for measuring the upper bound of LLMs' self-search abilities. The core metric is pass@k, which quantifies the probability that at least one of k sampled responses contains the correct answer. The study spans a diverse set of benchmarks, including general QA (Natural Questions, TriviaQA), multi-hop QA (HotpotQA, Musique, Bamboogle, 2WikiMultiHopQA), and web browsing (BrowseComp), and evaluates multiple model families (Qwen2.5, Llama3, Qwen3) across a wide parameter range.
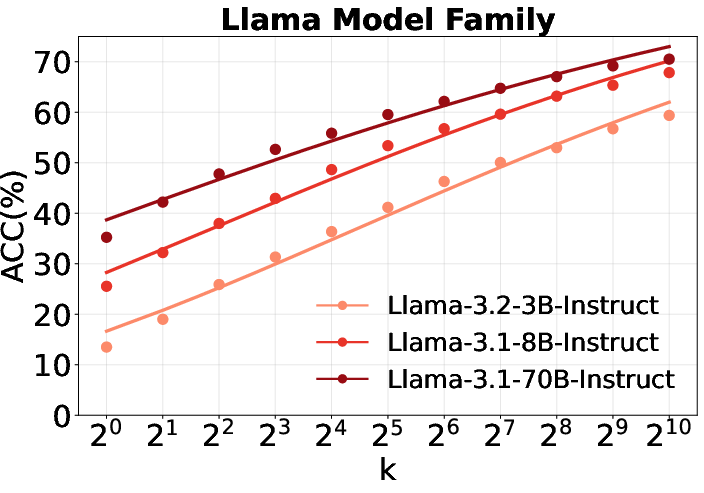
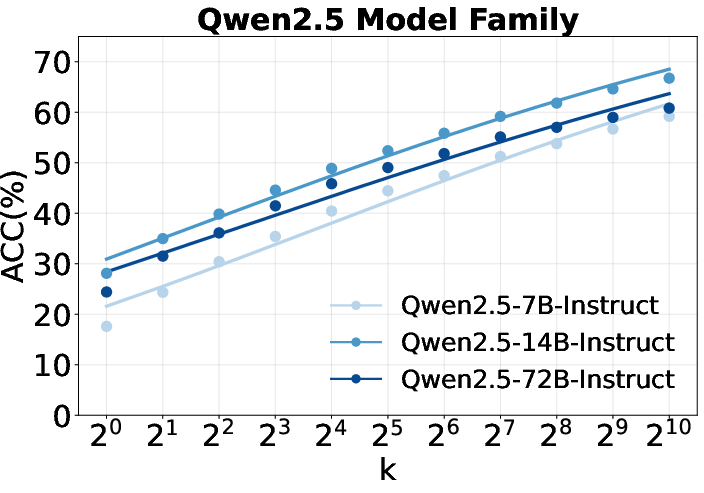
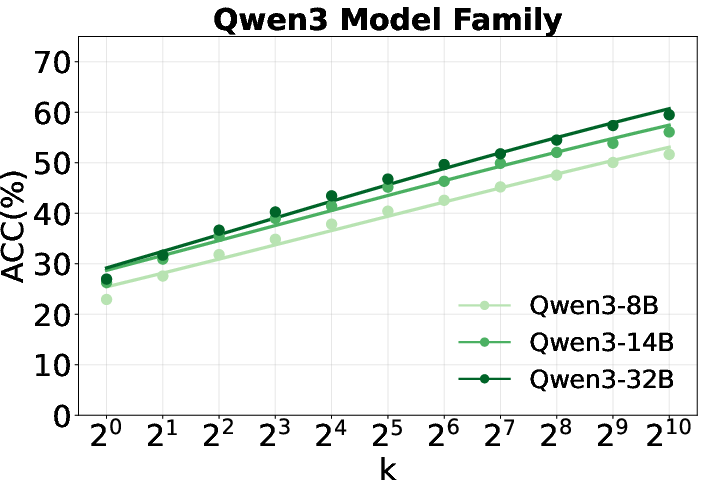
Figure 2: Scaling curves of repeated sampling for Qwen2.5, Llama, and Qwen3 families, showing predictive performance gains as sample size increases.
Key findings include:
- Predictive performance improves with sample size: All model families exhibit strong scaling behavior, with pass@k increasing monotonically as k grows. For example, Llama-3.1-8B-Instruct achieves 87.2% accuracy on Bamboogle at pass@1024, a 150% improvement over pass@1.
- Performance gap narrows with more sampling: Smaller models can approach the performance of much larger models via repeated sampling, consistent with recent scaling law literature.
- Llama outperforms Qwen for world knowledge: Contrary to trends in mathematical reasoning, Llama models demonstrate superior self-search performance on knowledge-intensive tasks, indicating that reasoning and knowledge priors are not strongly correlated.
Analysis of Reasoning and Sampling Strategies
The paper provides a detailed analysis of various strategies for eliciting knowledge from LLMs:
- Inefficient utilization of thinking tokens: Increasing the number of "thinking" tokens (i.e., longer chain-of-thought) does not improve self-search performance and is less token-efficient than short-CoT in this context.
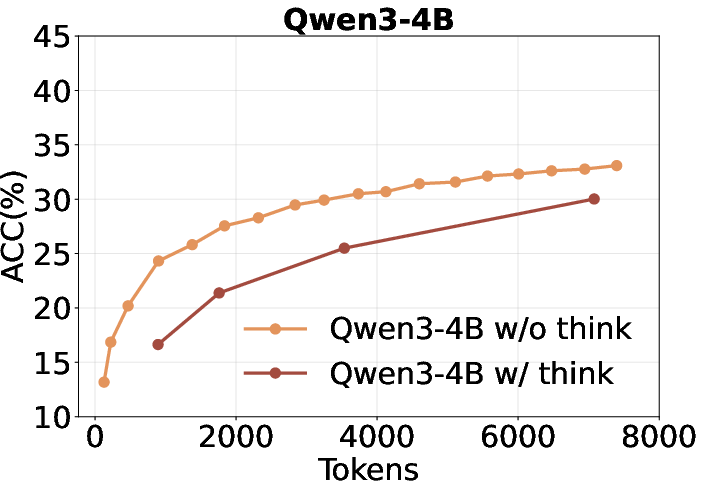
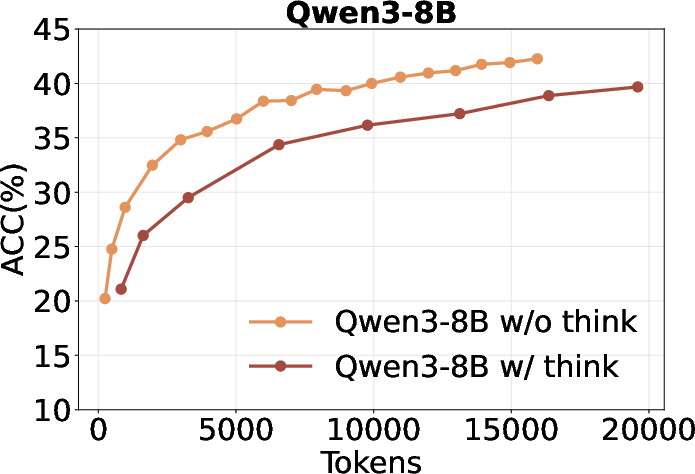
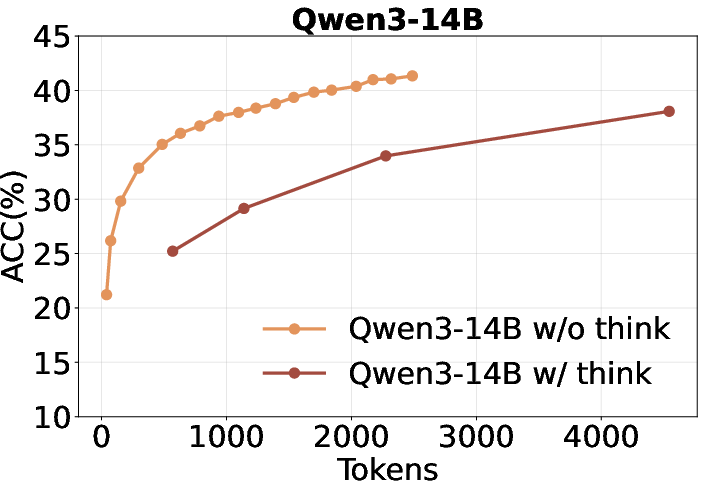
Figure 3: Qwen3 performance with and without forced-thinking, showing no benefit from longer reasoning chains.
- Multi-turn and reflection-based self-search are suboptimal: Multi-turn self-search and reflection (e.g., "Aha Moment" style prompting) do not outperform naive repeated sampling under a fixed token budget.
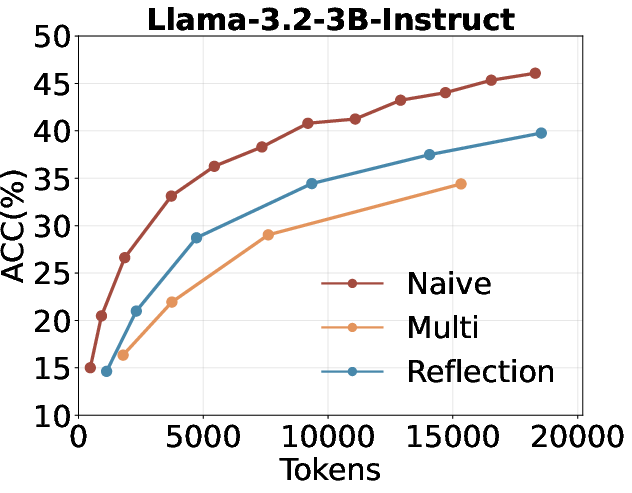
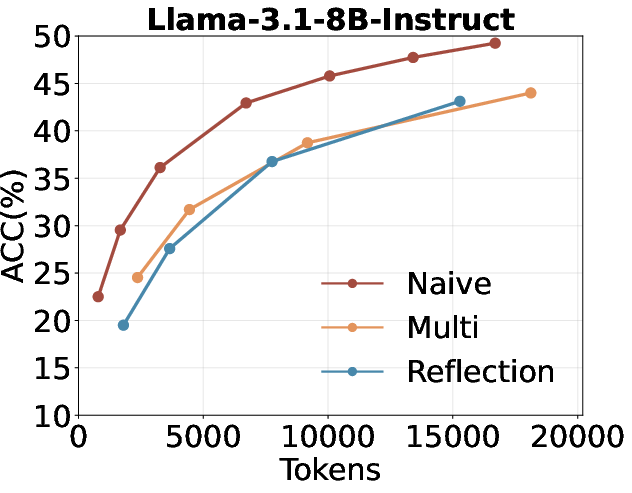
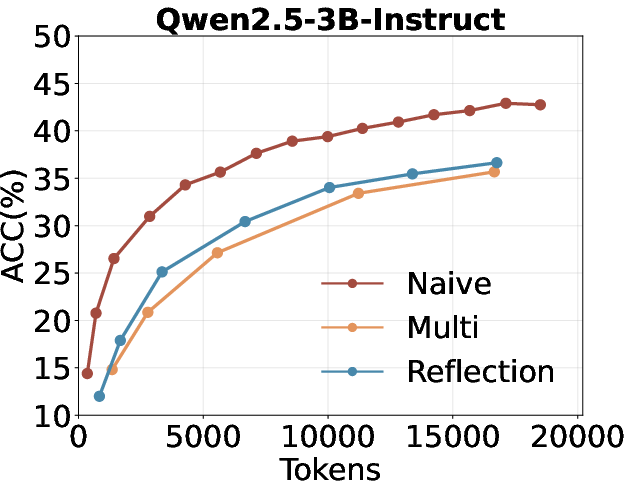
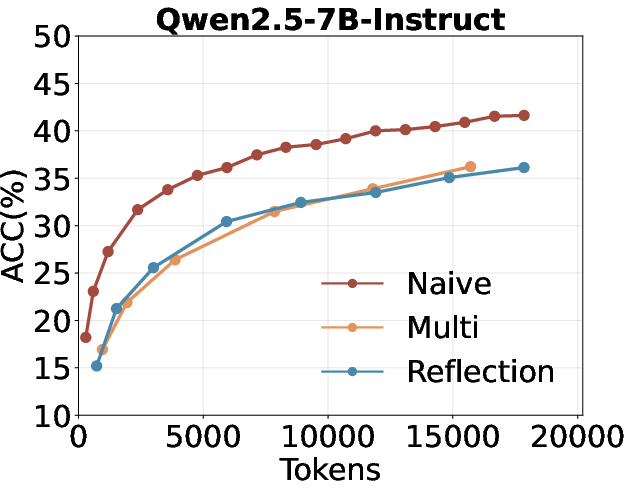
Figure 4: Comparison of repeated sampling, multi-turn self-search, and self-search with reflection under the same token budget.
- Majority voting is insufficient: Majority voting over sampled responses yields only marginal improvements, highlighting the challenge of reliably selecting the correct answer from a set of plausible candidates.
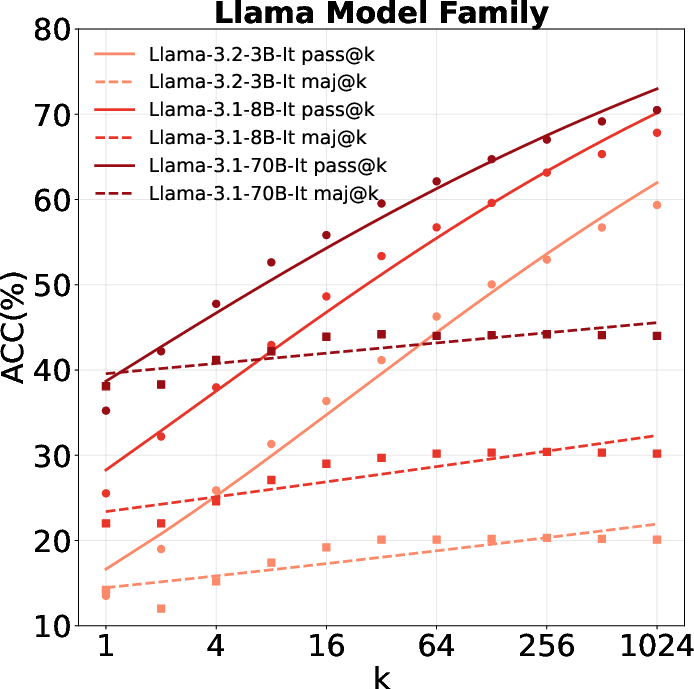
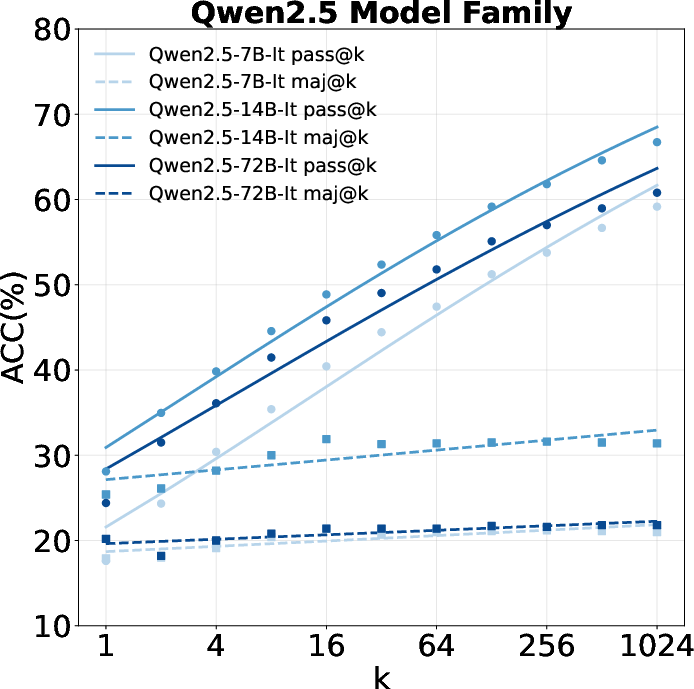
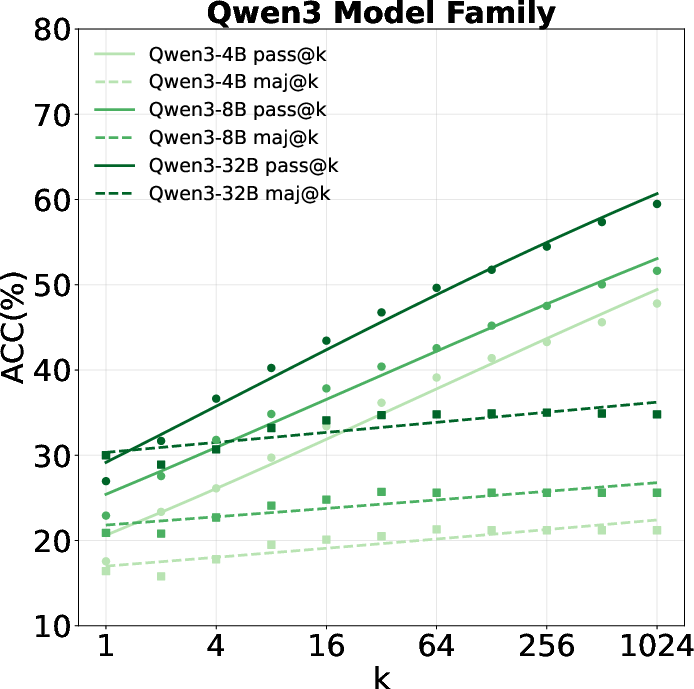
Figure 5: Majority voting results across model families, showing limited gains over pass@k.
SSRL: Self-Search Reinforcement Learning
RL Objective and Training
SSRL formulates the RL objective such that the policy model πθ both generates queries and retrieves information from its own parameters, eliminating the need for external search engines. The reward function combines outcome accuracy and a format-based reward to enforce structured reasoning (think/search/information/answer tags). Information masking is applied to prevent the model from simply copying retrieved content, encouraging deeper engagement with the reasoning process.
Empirical Results
- SSRL outperforms external search-based RL: SSRL-trained models consistently surpass baselines trained with external search engines (e.g., Search-R1, ZeroSearch) across all benchmarks and model sizes.
- Instruction-tuned models excel at internal knowledge utilization: Instruction-tuned variants outperform base models in self-search settings, but the trend reverses when external information is available.
- Larger models and SSRL yield better self-search: Larger models benefit more from SSRL, with improved decomposition and self-reflection strategies.
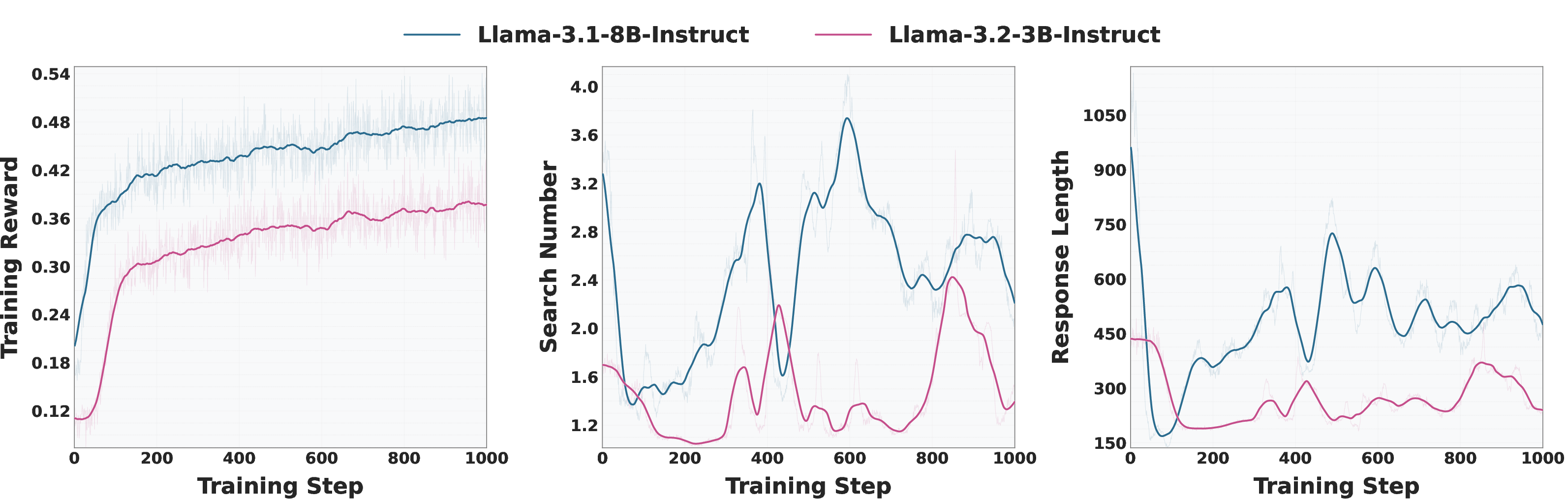
Figure 6: Training curves for Llama-3.2-3B-Instruct and Llama-3.1-8B-Instruct, showing reward, response length, and number of searches.
- SSRL is more efficient and robust than ZeroSearch: SSRL achieves a 5.5× reduction in training time and exhibits stable reward growth without collapse.
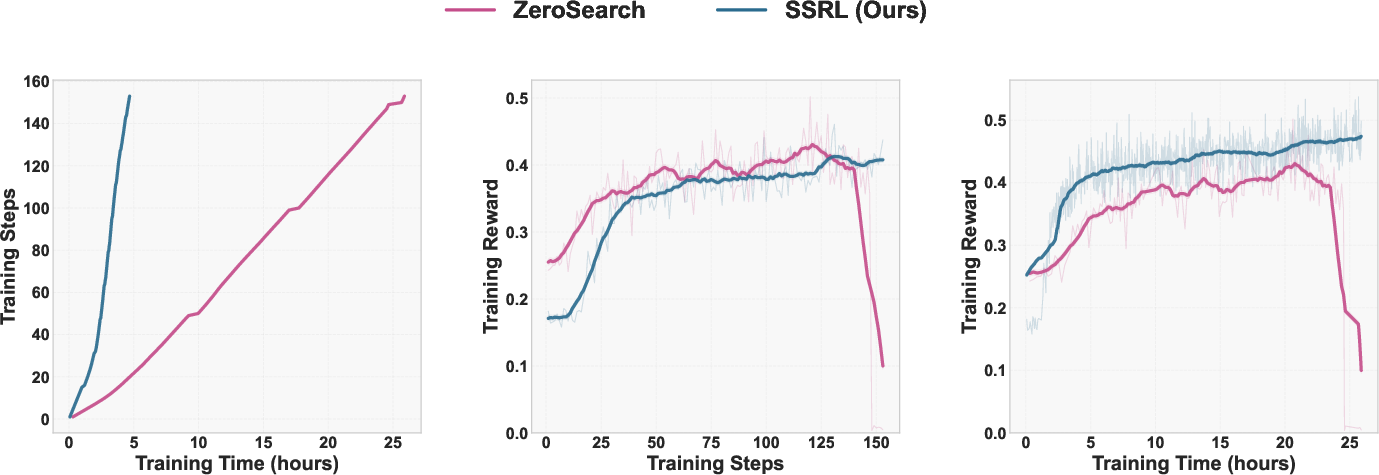
Figure 7: Training efficiency comparison between SSRL and ZeroSearch.
Sim2Real Generalization
A critical contribution is the demonstration of robust sim-to-real transfer: SSRL-trained models, when deployed with real search engines at inference, maintain or improve performance with fewer online searches compared to baselines. An entropy-guided strategy further reduces external search frequency by 20–42% without sacrificing accuracy.
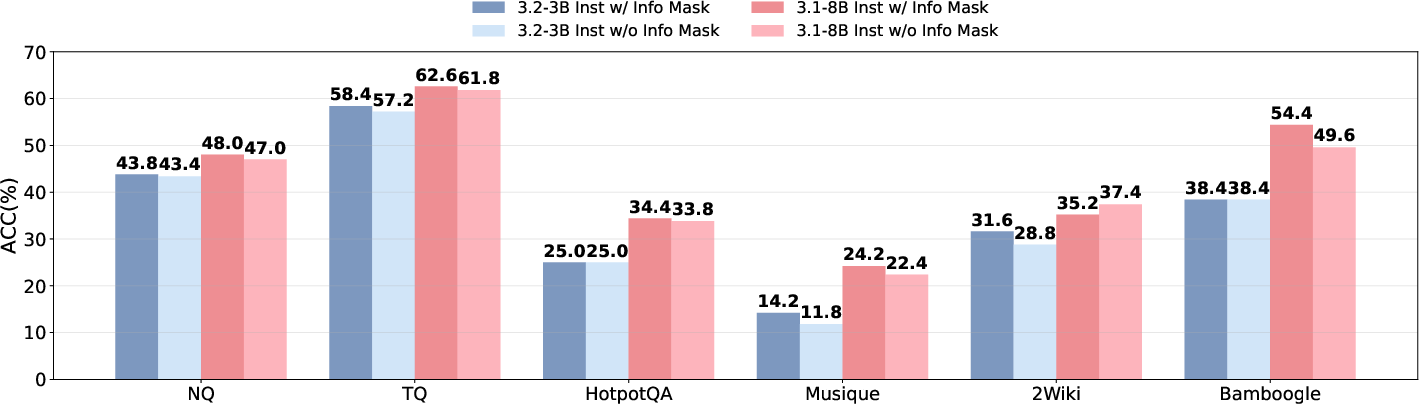
Figure 8: Performance with and without information mask, showing consistent gains from masking.
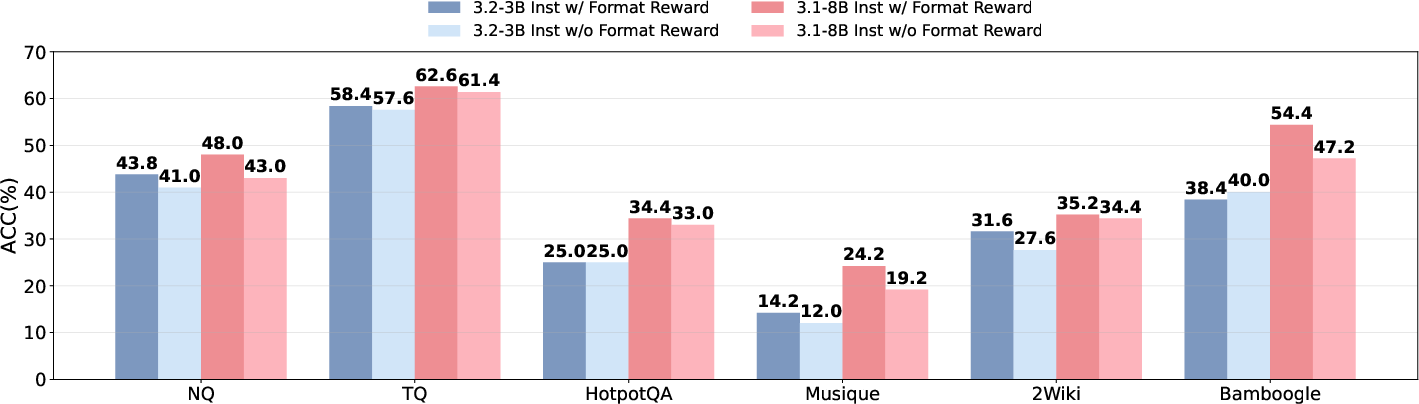
Figure 9: Performance with and without format reward, highlighting the importance of structured output.
Test-Time RL and Algorithmic Variants
The paper evaluates unsupervised RL (TTRL) and multiple RL algorithms (GRPO, PPO, DAPO, KL-Cov, REINFORCE++). TTRL yields substantial gains (up to 59% improvement) over GRPO in some settings, but introduces biases that hinder adaptation to real environments. On-policy self-search (i.e., using the current policy as the information provider) is essential; freezing the information provider leads to rapid performance collapse.
Implementation Considerations
- Prompting: Structured prompts with explicit tags for thinking, searching, information, and answer are critical for both training and inference.
- Reward modeling: Combining outcome and format rewards, with information masking, is necessary for stable and effective training.
- Resource requirements: SSRL enables fully offline RL training, dramatically reducing the cost associated with external API calls.
- Scaling: The approach is robust across model sizes and families, with repeated sampling and SSRL closing the gap between small and large models.
- Deployment: SSRL-trained models can be seamlessly integrated with real search engines at inference, supporting sim-to-real transfer and hybrid search strategies.
Implications and Future Directions
The findings have significant implications for the design of scalable, cost-effective RL agents:
- LLMs as world models: LLMs can serve as implicit simulators of world knowledge, supporting RL training without external data sources.
- Reducing hallucination: SSRL reduces reliance on external search and mitigates hallucination by grounding reasoning in internalized knowledge.
- Sim-to-real transfer: Skills acquired via self-search transfer robustly to real-world settings, enabling efficient agent deployment.
- Algorithmic generality: The framework is compatible with a range of RL algorithms and can be extended to other domains (e.g., math, code, embodied agents).
Open questions remain regarding the limits of internal knowledge, optimal strategies for answer selection, and the integration of self-search with external retrieval in dynamic environments.
Conclusion
This work establishes that LLMs possess substantial untapped capacity as implicit world models for search-driven RL. SSRL provides a principled framework for eliciting and refining this capability, outperforming external search-based baselines and enabling robust sim-to-real transfer. The approach paves the way for more autonomous, scalable, and cost-effective LLM agents, with broad implications for RL, agentic reasoning, and knowledge-intensive applications.