- The paper's main contribution is its empirical evaluation of reward formulations, showing that format rewards significantly improve query formatting in RL-tuned LLM search agents.
- The study reveals that general-purpose LLMs paired with robust search engines yield superior training dynamics compared to reasoning-specialized models, with scaling benefits evident.
- Results indicate that data scaling enhances multi-hop question answering, underscoring the importance of sufficient training data to induce effective search behavior.
RL for Reasoning-Search Interleaved LLM Agents: An Empirical Study
The paper "An Empirical Study on Reinforcement Learning for Reasoning-Search Interleaved LLM Agents" (2505.15117) presents a comprehensive empirical analysis of key design considerations for training LLM-based search agents using RL. The study focuses on reward formulation, the choice of the underlying LLM, and the role of the search engine in the RL process, providing actionable insights for building and deploying effective LLM-based search agents in real-world applications.
Reward Design for LLM Search Agents
The paper investigates the impact of different reward formulations on the RL training process. It examines the effectiveness of format rewards, which incentivize adherence to the agentic action format, and intermediate retrieval rewards, which encourage outcome-relevant retrievals. The findings indicate that incorporating a format reward significantly improves performance, especially when training from a base LLM, as it helps the model learn to issue correctly formatted search queries. In contrast, intermediate retrieval rewards do not yield consistent performance improvements, suggesting that the outcome reward alone is sufficient to encourage effective query formulation. "1" illustrates the empirical analyses on format reward and intermediate retrieval reward.
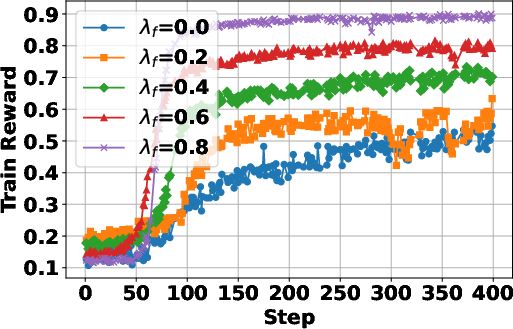
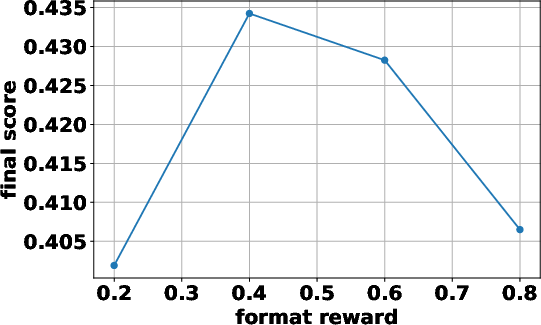
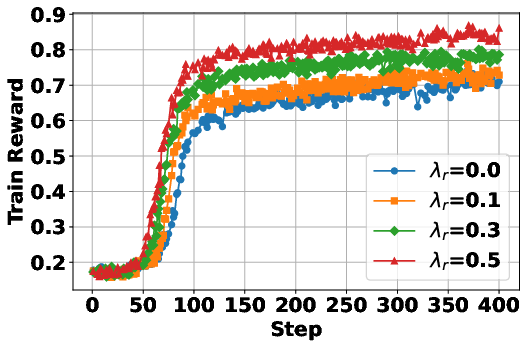
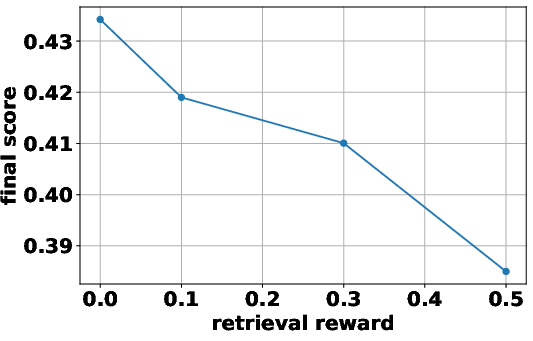
Figure 1: Empirical analyses on format reward and intermediate retrieval reward.
The paper introduces a format reward to the original reward function rϕ(x,y), resulting in
$r_{\phi}(x, y) =
\begin{cases}
1 & \text{if } a_{\text{pred} = a_{\text{gold} \land f_{\text{format}(y) = \text{True}, \
1 - \lambda_f & \text{if } a_{\text{pred} = a_{\text{gold} \land f_{\text{format}(y) = \text{False}, \
\lambda_f & \text{if } a_{\text{pred} \neq a_{\text{gold} \land f_{\text{format}(y) = \text{True}, \
0 & \text{if } a_{\text{pred} \neq a_{\text{gold} \land f_{\text{format}(y) = \text{False}, \
\end{cases}$
where fformat(⋅) verifies whether the response y follows the correct reasoning-action-observation format and λf is a reward when the LLM generates an incorrect answer in the correct format.
Influence of the Underlying LLM
The study examines how the characteristics of the backbone LLM influence RL dynamics. It considers factors such as model scale and type (general-purpose vs. reasoning-specialized). The results show that general-purpose LLMs outperform reasoning-specialized LLMs in RL settings, likely due to the latter’s weaker instruction-following capabilities at the early stages of training. Furthermore, scaling up the backbone model generally enhances final performance, although with diminishing returns. This suggests that while larger models are beneficial, the effectiveness of the search agent also depends on other factors, such as the quality of the search engine and the training process. The scaling laws observed in LLMs also apply when LLMs are RL-tuned as search agents. "(Figure 2)" demonstrates the impact of the underlying LLM on the performance of the search agents.
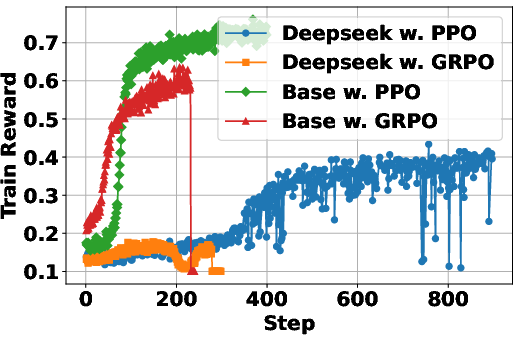
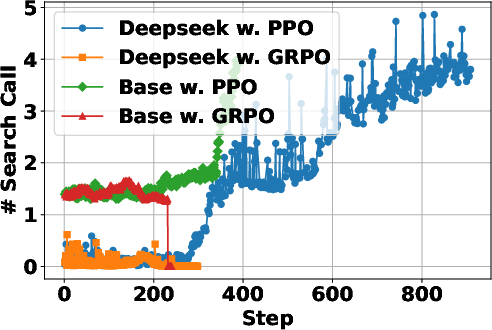
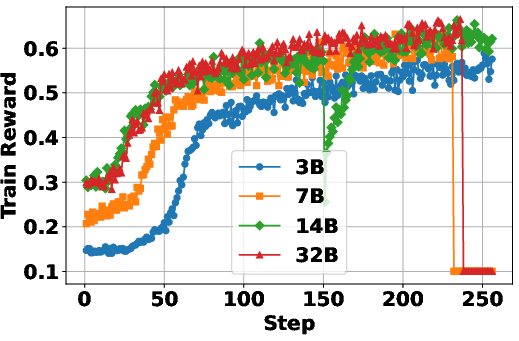
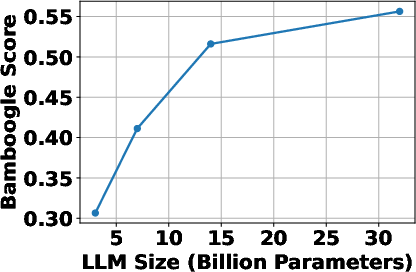
Figure 2: The study of underlying pretrained LLM for development of LLM-based search agents with RL.
The Role of the Search Engine
The paper highlights the critical role of the search engine in shaping RL training dynamics and the robustness of the trained agent during inference. It finds that the quality of the search engine used during training strongly influences RL dynamics. Training with a non-informative search engine leads the agent to avoid retrieval altogether, while a weak engine results in frequent but less efficient search calls. In contrast, strong engines yield more stable learning and better downstream performance. At inference time, the search agent is generally robust to diverse retrieval systems, and stronger search engines consistently lead to better downstream performance. "(Figure 3)" illustrates the effect of search engine choice on RL training dynamics.
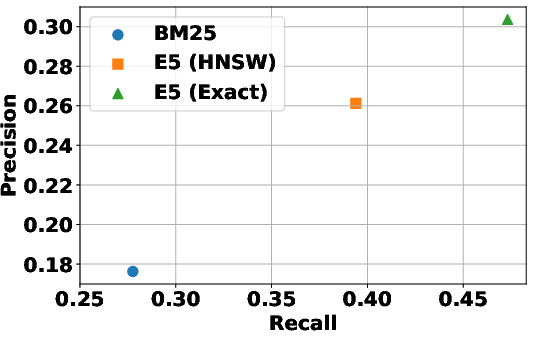
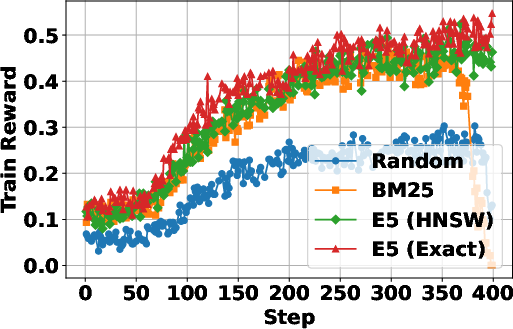
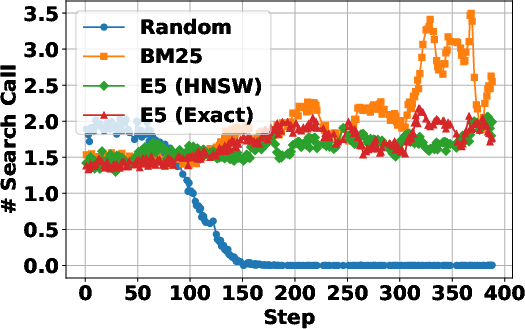
Figure 3: Effect of Search Engine Choice on RL Training Dynamics.
The LLM learns to interact with the search engine and receives positive reward feedback while it solves problems using the retrieved relevant information.
A strong search engine provides more relevant results, leading to consistent positive outcome rewards, and consequently, the LLM learns to solve problems with fewer search calls.
Data Scaling Effects in RL Training
The study investigates the impact of training data size on the RL process, revealing that increasing the size of the training dataset generally leads to improved performance, particularly on more complex multi-hop question answering tasks. Smaller datasets lead to faster convergence and higher training rewards, likely due to overfitting. The paper also finds that a certain amount of training data is needed to induce search behavior. "(Figure 4)" shows the data scaling effects in RL training for search agents.
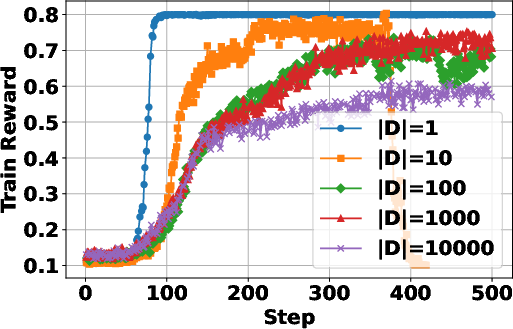
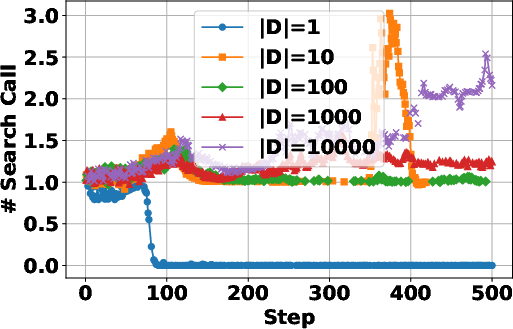
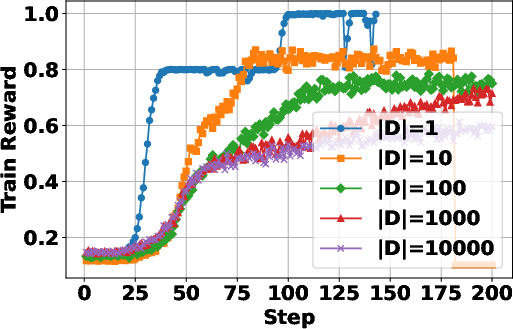
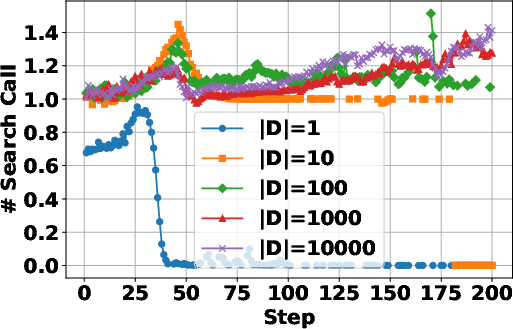
Figure 4: Data scaling effects in RL training for search agents.
Conclusion
The empirical study provides valuable insights into the design and training of LLM-based search agents using RL. The findings highlight the importance of reward formulation, the choice of the underlying LLM, and the quality of the search engine in achieving optimal performance. The study suggests that future research should explore more advanced reward modeling techniques and study agentic behaviors acquired through RL in broader scenarios. These efforts will pave the way for the development of more capable and reliable LLM-based agents for real-world applications.