Rethinking Sample Polarity in Reinforcement Learning with Verifiable Rewards
Abstract: Large reasoning models (LRMs) are typically trained using reinforcement learning with verifiable reward (RLVR) to enhance their reasoning abilities. In this paradigm, policies are updated using both positive and negative self-generated rollouts, which correspond to distinct sample polarities. In this paper, we provide a systematic investigation into how these sample polarities affect RLVR training dynamics and behaviors. We find that positive samples sharpen existing correct reasoning patterns, while negative samples encourage exploration of new reasoning paths. We further explore how adjusting the advantage values of positive and negative samples at both the sample level and the token level affects RLVR training. Based on these insights, we propose an Adaptive and Asymmetric token-level Advantage shaping method for Policy Optimization, namely A3PO, that more precisely allocates advantage signals to key tokens across different polarities. Experiments across five reasoning benchmarks demonstrate the effectiveness of our approach.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper studies how to better train large “reasoning” AIs (models that solve math, code, and science problems) using a style of practice called reinforcement learning with verifiable rewards (RLVR). In RLVR, the model tries many solutions on its own, and a simple checker says whether each final answer is right or wrong. The paper asks: how should we learn differently from right answers (positive samples) and wrong answers (negative samples)? Based on new insights, the authors create a training method called A3PO that improves the model’s reasoning skills across several tough benchmarks.
Key Questions
The paper focuses on a few simple questions:
- What different roles do correct attempts (positive samples) and incorrect attempts (negative samples) play during training?
- What happens if we give more or less “learning strength” to positives or negatives overall (sample-level), or even to specific words/pieces in a solution (token-level)?
- Can we design a smarter trainer that uses these differences to get better results?
How They Did It (Methods in Everyday Language)
Think of training as coaching a student:
- The student (the AI) solves many practice problems by writing out steps (a “chain of thought”).
- A checker marks each final answer as right (positive) or wrong (negative). There’s no human teacher showing the solution; just a green check or a red X.
- The coach then updates the student: “Do more of this” (from positives) and “Avoid that” (from negatives).
Some key ideas explained simply:
- Sample polarity: Positive means a correct solution; negative means an incorrect one.
- Advantage: How strongly the coach updates the student from a particular example. Bigger advantage = stronger push to learn from it.
- Tokens: The tiny pieces of text (like words or word pieces) in the student’s solution.
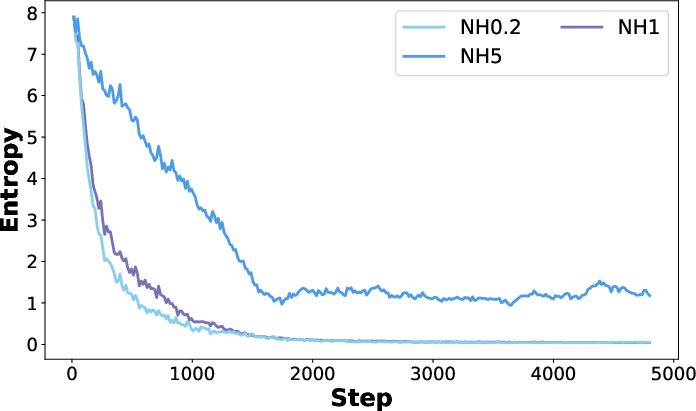
- Entropy: How spread out the student’s guesses are. High entropy = exploring many possibilities; low entropy = focusing on a few confident choices.
What they tried:
- Sample-level shaping: Give more or less learning strength to all positive examples or all negative examples to see how training behavior changes.
- Token-level shaping: Within a solution, adjust how much to learn from specific tokens. For example:
- High-entropy tokens are spots where the model is unsure (many options).
- High-probability tokens are choices the model is very confident about; low-probability tokens are long shots.
Their new method, A3PO:
- Adaptive: It changes how much it boosts certain tokens over time.
- Asymmetric: It treats positives and negatives differently on purpose.
- Early in training, it boosts:
- Low-probability tokens in correct solutions (to encourage learning new, less obvious but correct steps).
- High-probability tokens in incorrect solutions (to correct confident-but-wrong habits).
- Later, it gradually reduces these boosts so the model stabilizes and doesn’t over-explore forever.
Main Findings and Why They Matter
Main behaviors they discovered:
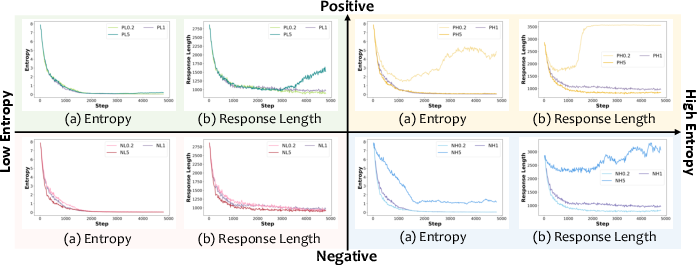
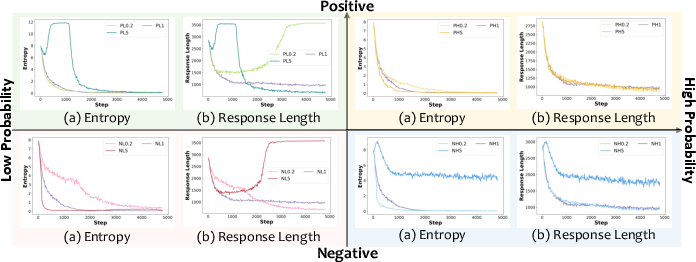
- Positive samples “sharpen” what the model already does well:
- The model becomes more confident in known-good reasoning paths.
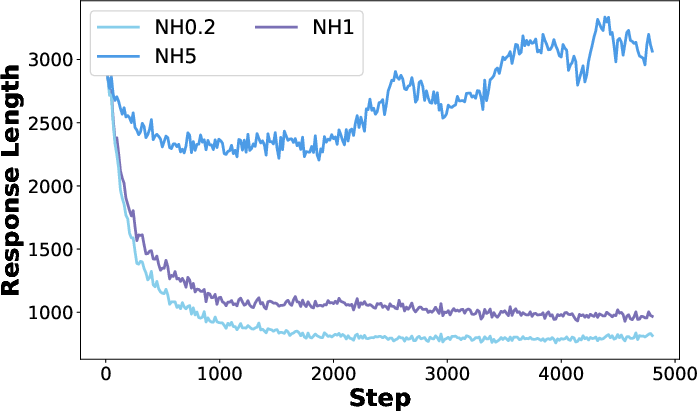
- Entropy drops (less exploring), and answers get shorter (more direct).
- Negative samples drive “discovery”:
- The model explores new reasoning paths and keeps entropy higher (more exploring).
- Answers get longer (it tries more steps).
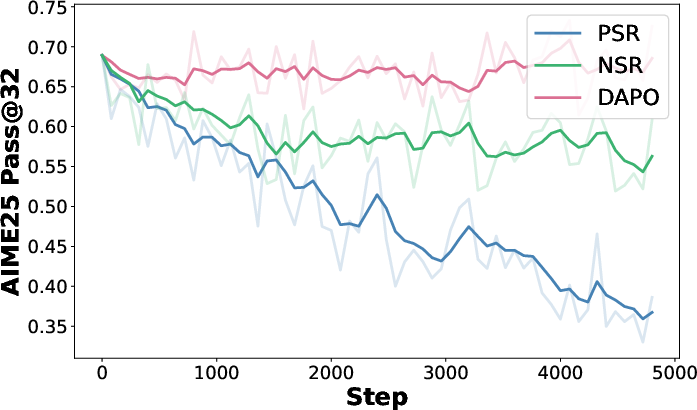
- Using only positives or only negatives hurts performance:
- Only positives can make the model overconfident and narrow-minded.
- Only negatives can make the model wander or even produce nonsense over time.
- Both are needed for strong, general reasoning.
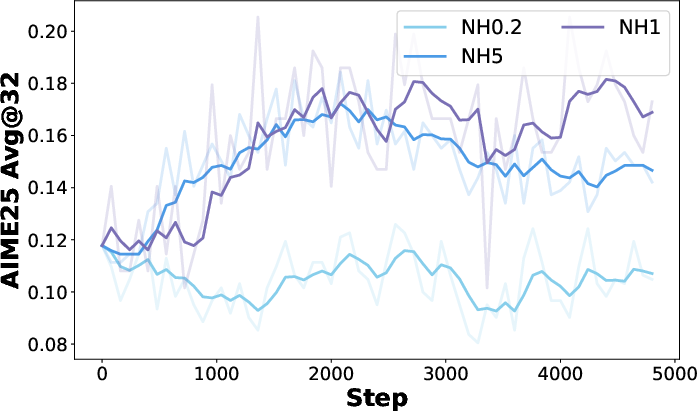
What happens when they change learning strength:
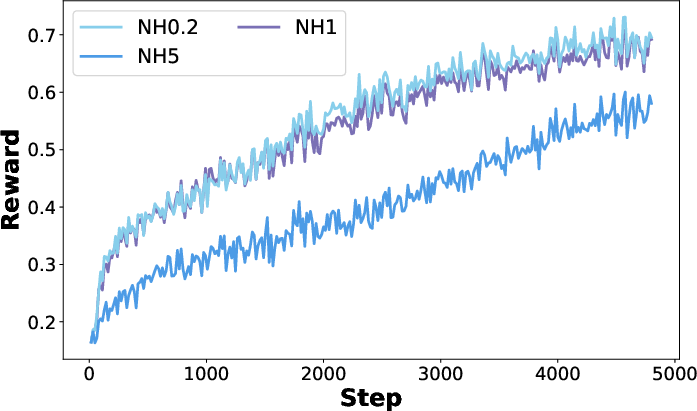
- If you weigh positives too much: faster improvement on training problems, but less exploration and weaker generalization.
- If you weigh negatives too much: more exploration, but slower improvement.
- The ratio between positive and negative strength matters more than their absolute size. A balanced ratio works best.
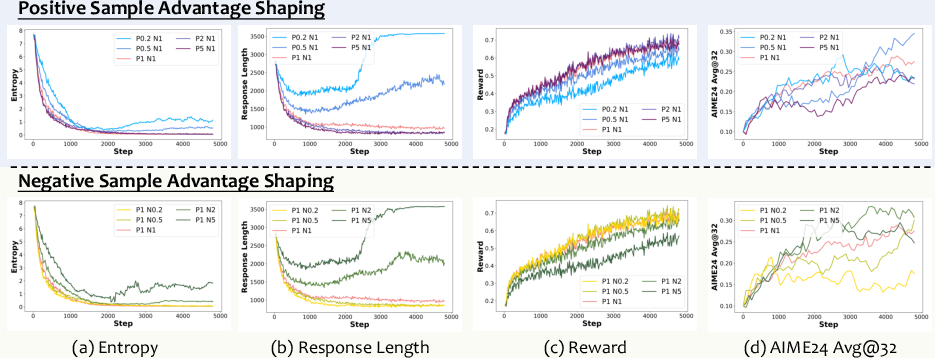
What happens when they target specific tokens:
- In positives:
- Pushing on high-entropy (uncertain) tokens speeds up focusing the model (reduces entropy), since it clarifies tough decision points.
- Pushing low-probability (rare but correct) tokens encourages exploration and can broaden the model’s skills.
- In negatives:
- Penalizing high-probability (confident but wrong) tokens raises entropy and helps the model reconsider bad habits.
- Penalizing low-probability wrong tokens narrows the model’s focus (less useful for exploration).
Results of their new method (A3PO):
- Across three different base models and five reasoning benchmarks (including AIME24/25, MATH500, GPQA, LiveCodeBench), A3PO consistently beats standard methods.
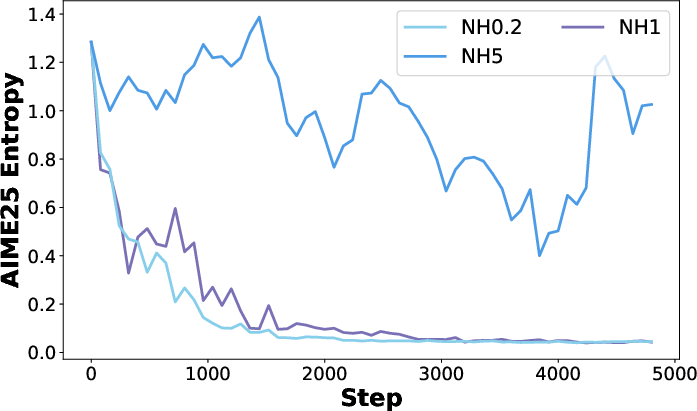
- A3PO keeps useful exploration longer, avoids getting stuck too soon, and achieves higher accuracy on validation tests (which shows better real-world generalization).
Implications and Impact
Why this matters:
- Training reasoning AIs isn’t just about copying correct answers; it’s about balancing “get better at what works” with “try new ideas.” This paper shows how positives and negatives play different, complementary roles.
- By carefully and differently boosting certain parts of correct and incorrect solutions—and changing that boost over time—A3PO teaches models to both explore and converge, leading to stronger, more general reasoning skills.
- These ideas can help future AI systems solve harder problems more reliably, from math and science to code and beyond.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following items summarize what remains unresolved and where further research could concretely extend, validate, or challenge the paper’s findings.
- Scalability to larger models and longer contexts: Assess whether polarity dynamics and A3PO gains hold for significantly larger LRMs (e.g., 32–70B+) and longer CoT horizons, including memory/compute trade-offs.
- Generalization beyond text-only reasoning: Extend analyses and methods to vision–LLMs and multimodal tasks; measure whether polarity effects persist with visual/verifiable rewards.
- Agent-based and interactive settings: Evaluate RLVR polarity dynamics and A3PO in tool-use, search, and multi-step agent environments where verification may be delayed or partial.
- OOD and adversarial generalization: Test on distribution-shifted and adversarial benchmarks to verify the claim that negative samples better preserve generalization.
- Reward design beyond binary signals: Study robustness of A3PO and polarity dynamics under noisy verifiers, partial credit, graded rewards, and learned reward models (RMs) with errors.
- Theoretical guarantees: Provide convergence and stability analysis for asymmetric token-level advantage shaping under clipping; characterize conditions that avoid mode collapse or reward hacking.
- Hyperparameter sensitivity and auto-scheduling: Systematically analyze sensitivity to A3PO’s hyperparameters (ρ+, ρ−, α+, α−, τ⁺, τ⁻, ε_low, ε_high) across models/datasets; develop adaptive/learned schedules rather than fixed linear decay.
- Token selection strategy: Replace fixed top/bottom 20% token heuristics with uncertainty-calibrated or learned selectors; evaluate per-sample, per-step adaptation and its impact on stability.
- Token-type awareness: Investigate whether shaping should treat token classes differently (e.g., math operators, numerals, code syntax vs natural language tokens), and quantify per-class contributions to training dynamics.
- Sampling strategy interactions: Quantify how temperature, top-p, beam/tree search, and group size k affect polarity dynamics and A3PO’s performance; derive guidelines for joint tuning.
- Group size and rollout budget: Analyze how the number of rollouts per prompt and positive/negative ratio allocation impact sharpening vs discovery and final accuracy under fixed compute budgets.
- Length–accuracy trade-offs: Determine when longer chains induced by negative samples help vs hurt; design mechanisms to target an optimal reasoning depth given latency or token budgets.
- Detection and mitigation of reward hacking/mojibake: Develop diagnostics and safeguards (e.g., entropy/consistency monitors, verifier-aware constraints) and demonstrate that A3PO reduces these failure modes across models/tasks.
- Semantic measures of “sharpening” vs “discovery”: Replace n-gram proxies with semantic/structural metrics (e.g., reasoning graphs, step equivalence classes, program ASTs) to more rigorously quantify novelty.
- Calibration and uncertainty: Evaluate how entropy modulation affects calibration (ECE, Brier score), confidence reporting, and risk-sensitive decision-making in reasoning tasks.
- Interaction with clipping and trust-region constraints: Compare A3PO’s clipping bounds to PPO-style KL penalties; explore adaptive clipping/penalties and their effect on stability and generalization.
- Process supervision compatibility: Extend A3PO to step-level verifiable rewards (process rewards), studying token-level shaping at intermediate steps and its effect on final correctness.
- Cost/efficiency analysis: Quantify training and inference overhead introduced by token-level shaping, including profiling and ablations to establish cost–benefit trade-offs.
- Cross-lingual robustness: Examine polarity dynamics and mojibake risks in multilingual settings, including tokenization effects (BPE vs sentencepiece) and language-specific failure modes.
- Reproducibility and standardization: Clarify code, configs, and seeds; provide standardized evaluation scripts and benchmark splits to enable direct replication of polarity analyses and A3PO results.
Glossary
- A3PO: An adaptive and asymmetric token-level advantage shaping algorithm for policy optimization in RLVR that emphasizes different token types over training. Example: "A3PO maintains higher entropy"
- Advantage shaping: Modifying advantage values (e.g., by scaling or weighting) to steer learning dynamics. Example: "advantage shaping~\citep{PSRNSR}"
- AIME24: A competitive mathematics benchmark (American Invitational Mathematics Examination 2024) used to evaluate reasoning. Example: "AIME24, AIME25, and MATH500"
- AIME25: A competitive mathematics benchmark (American Invitational Mathematics Examination 2025) used to evaluate reasoning. Example: "AIME25 Pass@32"
- Chain-of-thought: Step-by-step reasoning trajectories generated by a model. Example: "long chain-of-thought reasoning trajectories"
- Clip higher mechanism: A clipping variant that allows larger upward policy updates, used to retain certain beneficial tokens. Example: "which can be attributed to its clip higher mechanism"
- Clipping bounds: Limits on the policy ratio to stabilize updates (as in PPO-style objectives). Example: "clipping bounds that constrain policy updates."
- DAPO: An RLVR method that uses both positive and negative samples with modified clipping to improve reasoning. Example: "include DAPO, which utilizes both types of samples"
- Discovery: A metric quantifying novel content in rollouts to assess exploration. Example: "Discovery: The proportion of n-grams in the current rollout"
- Entropy: A measure of uncertainty in the model’s output distribution; higher entropy indicates broader exploration. Example: "leads to a rapid decline in model entropy"
- Fork Tokens: A token-weighting heuristic emphasizing high-entropy branching points during training. Example: "DAPO w/ Fork Tokens"
- GPQA: A graduate-level question answering benchmark for assessing advanced reasoning. Example: "GPQA"
- GRPO (Group Relative Policy Optimization): A policy optimization method computing advantages from groups of rollouts without a learned value network. Example: "Group Relative Policy Optimization (GRPO)"
- Importance sampling: A technique to reweight samples from a different distribution to reduce bias in updates. Example: "importance sampling~\citep{CISPO}"
- LiveCodeBench: A benchmark for code-related reasoning and generation tasks. Example: "LiveCodeBench"
- Loss aggregation: The strategy for combining per-token or per-sample losses during optimization. Example: "loss aggregation~\citep{GMPO,GSPO}"
- MATH500: A math reasoning benchmark with 500 problems used for evaluation. Example: "MATH500"
- Mojibake: Garbled or nonsensical text due to encoding or generation issues; here, denotes corrupted outputs during training. Example: "mojibake output"
- N-gram: A contiguous sequence of n tokens used to analyze pattern overlap and novelty in rollouts. Example: "n-gram perspective."
- NSR (Negative Sample Reinforcement): Training that reinforces learning using only negative (incorrect) samples. Example: "PSR and NSR"
- Pass@k: An evaluation metric measuring the probability of at least one correct answer in k sampled attempts. Example: "improves Pass@k metrics."
- Policy: The model’s conditional distribution over next tokens/actions given the context. Example: "policy model"
- Policy Optimization: Algorithms and objectives for improving a policy’s parameters (e.g., PPO-style methods). Example: "Policy Optimization"
- Polarity-level advantage shaping: Scaling advantages differently for positive vs. negative samples to control exploration-exploitation balance. Example: "Polarity-level Advantage Shaping"
- PSR (Positive Sample Reinforcement): Training that reinforces learning using only positive (correct) samples. Example: "PSR and NSR"
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL paradigm where rewards are computed by verifiable checks (e.g., correct final answers) rather than learned reward models. Example: "Reinforcement learning with verifiable rewards (RLVR)"
- Reward hacking: Exploiting the reward signal (e.g., guessing answers) without genuine reasoning or desired behavior. Example: "the model exhibits reward hacking"
- Rollout: A generated trajectory/output sequence sampled from the policy. Example: "self-generated rollouts"
- Sharpening: A metric indicating the reinforcement of previously correct patterns in current rollouts. Example: "Sharpening: The proportion of n-grams in the current rollout"
- Token-level advantage shaping: Adjusting advantages at the token granularity based on features like entropy or probability. Example: "token-level advantage shaping"
- Training-inference engine mismatch: A discrepancy between training-time weighting/constraints and inference-time behavior that can harm performance. Example: "training-inference engine mismatch"
- Value network: A learned function approximator estimating expected returns, often avoided in GRPO-like methods. Example: "learned value network"
- Verifiable binary rewards: Deterministic pass/fail rewards derived from checking the final answer’s correctness. Example: "verifiable binary rewards"
- Zero-RL: A setting or technique that reduces reliance on learned RL components (e.g., value networks) while optimizing policies. Example: "enabling scalable reasoning through zero-RL."
Practical Applications
Practical Applications of “Rethinking Sample Polarity in Reinforcement Learning with Verifiable Rewards”
Below are actionable applications derived from the paper’s findings on sample polarity in RLVR and the proposed A3PO method. Each item is grouped by deployment horizon and summarizes sector fit, potential tools/products/workflows, and key assumptions or dependencies.
Immediate Applications
- Polarity-aware RLVR training recipe for reasoning LLMs
- What: Adopt both positive and negative rollouts instead of single-polarity training; tune their relative advantage ratio (e.g., start near 0.5× positive : 1× negative) to balance reward growth and exploration.
- Sectors: software/AI platforms, MLops, model training services.
- Tools/Workflows: training scripts with polarity-level advantage scaling; schedulers for entropy/length targets; evaluation dashboards tracking entropy and Pass@k.
- Assumptions/Dependencies: access to verifiable reward tasks (e.g., math checkers, code unit tests); multi-sample rollouts per prompt; sufficient compute.
- Integrate A3PO into RLVR pipelines to improve generalization
- What: Use A3PO’s adaptive, asymmetric token-level advantage shaping (upweight low-prob tokens in positive rollouts and high-prob tokens in negative rollouts early; decay over time) to maintain exploration and reduce mode collapse.
- Sectors: model training toolchains, cloud ML services, foundation model labs.
- Tools/Workflows: A3PO plugin/module for TRL/DeepSpeed/Accelerate; config for token-level shaping thresholds and decay; CI-style training gates on validation accuracy and entropy.
- Assumptions/Dependencies: token-level probabilities and entropy available at train time; stable decays to avoid training–inference mismatch; benchmark coverage resembling target domains.
- Reward hacking and mode-collapse mitigation in base-model RLVR
- What: Counter base models’ tendency to “guess answers” or collapse by mixing polarities and token-level shaping to keep entropy healthy and outputs sufficiently long during early training.
- Sectors: AI safety/reliability, platform QA.
- Tools/Workflows: early-warning monitors for reward spikes with falling entropy/length; automatic rebalancing of polarity and token shaping.
- Assumptions/Dependencies: robust telemetry (entropy, response length), rollback mechanisms if reward hacking is detected.
- Token-level shaping heuristics as drop-in regularizers
- What: Apply simple heuristics distilled from the analysis when A3PO is not implemented: boost low-probability positive tokens and high-probability negative tokens early; taper with a schedule.
- Sectors: research teams, smaller labs lacking full A3PO integration.
- Tools/Workflows: token-weighting hooks in loss computation; annealing schedules tied to training steps.
- Assumptions/Dependencies: minimal code changes to compute token-level weights; careful tuning to avoid instability.
- Domain-specific RLVR for code assistants with unit tests
- What: Train coding models using verifiable test suites; use A3PO to preserve exploration and discover novel fix strategies while still improving pass rates.
- Sectors: software engineering, DevEx tools.
- Tools/Workflows: test-harness verifiers; patch-generation agents; pass@k-driven RLVR loops; dashboards of entropy vs. test pass rate.
- Assumptions/Dependencies: adequate, reliable tests; sandboxed execution; scalable sampling of multiple rollouts per prompt.
- Math tutoring and assessment systems with verifiable answers
- What: RLVR on math problems with checkers; produce concise but correct chain-of-thought while avoiding premature shortening of reasoning (by balancing polarities).
- Sectors: education/edtech.
- Tools/Workflows: math verifiers, curated problem banks; student-level personalization via entropy/length controls; evaluation on AIME/MATH-style tasks.
- Assumptions/Dependencies: permission to use chain-of-thought during training; alignment with privacy/policy for educational data.
- MLOps metrics and diagnostics for RLVR dynamics
- What: Standardize monitoring beyond accuracy: entropy, response length, “sharpen” vs. “discovery” n-gram metrics to understand exploration vs. exploitation balance during training.
- Sectors: MLOps, eval platforms, governance.
- Tools/Workflows: metric collectors; n-gram novelty analyzers; model release gating using multi-metric criteria.
- Assumptions/Dependencies: storage for rollouts; reproducible sampling; accessible text traces for n-gram analysis.
- Best-practice guidance by base-model type
- What: Use the paper’s observations to set defaults: math-tuned vs. distilled vs. general pretrains respond differently to polarity weighting. Start with mixed-polarity for all; avoid single-polarity training.
- Sectors: applied research groups, enterprise model teams.
- Tools/Workflows: templated config profiles by base model category; automated sweeps of polarity ratios early in training.
- Assumptions/Dependencies: quick-turn pilots to validate per-model sensitivity; budget to run short ablations.
- Cost-efficient exploration control
- What: Maintain exploration with negative samples and targeted token shaping to reduce overtraining on familiar patterns—potentially lowering the need for excessive data or long runs.
- Sectors: startups, cost-constrained labs.
- Tools/Workflows: early stopping keyed to entropy plateaus; scheduled reduction of negative-token upweighting as validation gains stabilize.
- Assumptions/Dependencies: careful tracking of learn–explore trade-offs; no degradation of downstream alignment goals.
Long-Term Applications
- Multimodal RLVR with verifiable rewards
- What: Extend polarity-aware shaping to vision–language reasoning (e.g., geometry diagrams, chart QA) where correctness can be programmatically verified.
- Sectors: healthcare imaging QA, edu-visual reasoning, industrial inspection.
- Tools/Workflows: multimodal verifiers, synthetic visual math datasets, A3PO-style token (and modality) shaping.
- Assumptions/Dependencies: robust multimodal verifiers; scalable data generation; cross-modal token attribution.
- Planning and tool-using agents with verifiable subgoals
- What: Train search/code/solver agents where intermediate steps are verifiable (tests, solver checks); use A3PO to avoid brittle scripts and broaden feasible strategies.
- Sectors: software robotics, data engineering, analytics pipelines.
- Tools/Workflows: orchestration frameworks (e.g., LangChain-like), subgoal checkers, polarity-aware sampling for branches (“fork tokens”).
- Assumptions/Dependencies: reliable subgoal validators; latency budget for multi-rollout sampling; safe tool sandboxes.
- Theorem proving and formal methods assistants
- What: Couple RLVR with proof checkers (Lean/Coq/Isabelle) as verifiers; leverage negative-sample-driven exploration to discover novel proof paths while sharpening known lemmas.
- Sectors: formal verification, safety-critical software.
- Tools/Workflows: proof-environment integrations; subgoal shaping; novelty metrics beyond n-grams (proof-state space novelty).
- Assumptions/Dependencies: efficient proof-state sampling; scalable proof checkers; domain-specific token selection heuristics.
- Scientific reasoning and program synthesis with simulation-based verifiers
- What: Use simulators as verifiable reward sources (e.g., physics/chemistry constraints); A3PO to sustain exploration of hypothesis/program spaces.
- Sectors: materials discovery, computational biology, engineering design.
- Tools/Workflows: differentiable or batched simulators; safety filters; exploration schedulers tied to simulation uncertainty.
- Assumptions/Dependencies: faithful simulators; compute budget; robust interfaces from text-to-sim.
- Operations research and constrained optimization copilots
- What: Train models to propose schedules/routes/allocations verified by OR solvers; negative-sample weighting promotes discovery of feasible alternatives near constraint boundaries.
- Sectors: logistics, energy, manufacturing.
- Tools/Workflows: MILP/SAT verifiers; constraint-aware decoding; RLVR loops with feasibility/optimality checks.
- Assumptions/Dependencies: high-quality solver integration; cost to evaluate many candidate solutions; domain-specific constraints encoding.
- Compliance-by-construction assistants
- What: Use verifiable policy/compliance checkers (e.g., rule engines) as rewards to train assistants that propose compliant actions/documentation; A3PO to explore borderline cases without collapsing to boilerplate.
- Sectors: finance, legal, healthcare administration.
- Tools/Workflows: rules/verifier pipelines; audit logs tracking entropy and discovery; continuous policy updates as regulations change.
- Assumptions/Dependencies: up-to-date machine-checkable rules; governance for false negatives/positives in verifiers.
- Auto-tuning controllers for polarity and token shaping
- What: Build controllers that target a desired entropy/length band by adjusting positive:negative advantage ratios and token weights on the fly.
- Sectors: AutoML, training platform vendors.
- Tools/Workflows: closed-loop controllers; Bayesian/bandit search over shaping schedules; guardrails to prevent instability.
- Assumptions/Dependencies: robust online metrics; safe exploration policies; rollback on divergence.
- Standardized RLVR governance metrics
- What: Incorporate entropy, response length, sharpen/discovery, and Pass@k into procurement, model cards, and audits as indicators of generalization vs. memorization.
- Sectors: public-sector procurement, platform policy, AI governance.
- Tools/Workflows: compliance checklists; standardized reporting templates; third-party audit suites.
- Assumptions/Dependencies: consensus on thresholds; reproducibility across labs; acceptance by regulators.
- Enterprise-scale codebase modernization via RLVR
- What: Train code LLMs against large monorepos with broad unit/integration tests; negative-sample shaping to widen exploration for edge cases, then decay to consolidate improvements.
- Sectors: large software enterprises, cloud providers.
- Tools/Workflows: test orchestration farms; patch triage pipelines; staged rollout with canary repos.
- Assumptions/Dependencies: extensive, reliable tests; CI capacity; strong sandboxing and security.
- Calibration and uncertainty-aware reasoning
- What: Investigate whether polarity/entropy-aware training can yield better-calibrated confidence for safety-critical deployments (e.g., medical calculators with verifier-backed substeps).
- Sectors: healthcare, aviation, public safety.
- Tools/Workflows: calibration evals (ECE/Brier), verifier-backed prompts, abstention/deferral policies.
- Assumptions/Dependencies: domain verifiers that meaningfully reflect correctness; rigorous clinical/regulatory validation beyond current text-only scope.
Notes on feasibility:
- Core dependency across applications is the availability of reliable verifiable rewards (tests, solvers, checkers). Where such verifiers are partial or noisy, safeguards (simulation ensembles, human-in-the-loop adjudication, conservative thresholds) are needed.
- The paper’s experiments are text-only and do not cover agentic or multimodal settings; extensions require additional research and engineering.
- Compute and sampling budgets matter: RLVR typically relies on multiple rollouts per prompt; scaling strategies (importance sampling, grouped advantages, efficient verifiers) are crucial for cost control.
Collections
Sign up for free to add this paper to one or more collections.