- The paper reveals that RL benefits on Qwen2.5 models may result from memorization due to data contamination rather than true reasoning.
- It demonstrates through metrics like partial-prompt accuracy that spurious rewards inflate performance on contaminated benchmarks.
- Using the clean RandomCalculation dataset, the study shows that only properly aligned rewards lead to stable, genuine reasoning improvements.
Reasoning or Memorization? Unreliable Results of Reinforcement Learning Due to Data Contamination
Introduction
LLMs have increasingly relied on reinforcement learning (RL) to enhance their mathematical reasoning capabilities. Recent works suggest that RL methods, even those using seemingly random reward signals, can significantly improve LLM performance, especially on challenging mathematical benchmarks like MATH-500. However, this research paper investigates a critical confounding factor: the potential contamination of these datasets with training data, which skews the evaluation of RL enhancements. The Qwen2.5 model family, trained on extensive web-scale corpora, serves as a subject for examining the effects of data contamination. This study argues for clean, uncontaminated benchmarks to assess RL-driven improvements accurately.
Data Contamination Analysis
To discern whether the Qwen2.5 models benefit from genuine reasoning improvements or simple memorization due to contaminated datasets, the authors introduce metrics assessing data leakage. The key metrics include the partial-prompt completion rate and the partial-prompt answer accuracy. These metrics evaluate the ability of models to complete and answer questions when only provided with partial input.
Tests conducted on datasets like MATH-500 demonstrate that Qwen2.5 can regenerate substantial portions of questions and yield correct answers despite limited input. For instance, when presented with only 40% of a MATH-500 problem, Qwen2.5-Math-7B was able to regenerate and solve 39.2% of instances correctly. Such findings suggest that Qwen2.5 may not always be learning to reason through RL, but rather recalling memorized solutions.
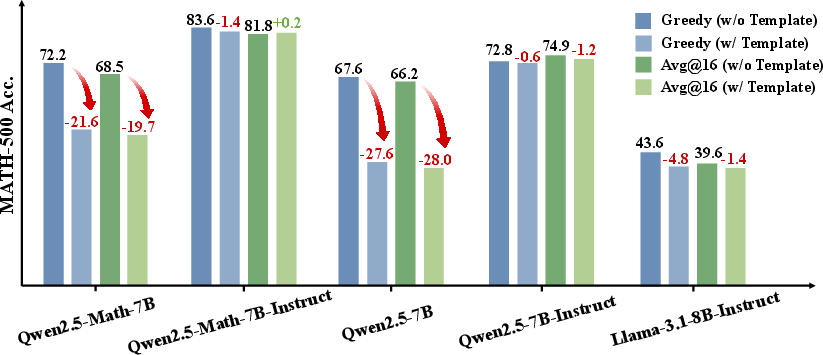
Figure 1: Accuracy (\%) of Qwen and Llama models on the MATH-500 dataset under different generation configurations, using original questions as prompts.
Reinforcement Learning with Verifiable Rewards (RLVR)
The paper evaluates RLVR applied to the Qwen2.5 series, using both contaminated datasets like MATH-500 and a newly introduced clean dataset, RandomCalculation. The RandomCalculation dataset comprises newly generated math problems that have not been seen by the model before, serving as a control to accurately gauge the impact of RLVR on reasoning rather than memorization.
Experiments using RLVR with correct and spurious (random, inverted) reward signals reveal significant insights. On the clean RandomCalculation dataset, only properly aligned rewards lead to stable performance improvements, while spurious rewards result in instability and negligible gains in problem-solving accuracy. Conversely, on contaminated datasets, spurious reward signals can lead to apparent improvements due to the model simply recalling memorized solutions.
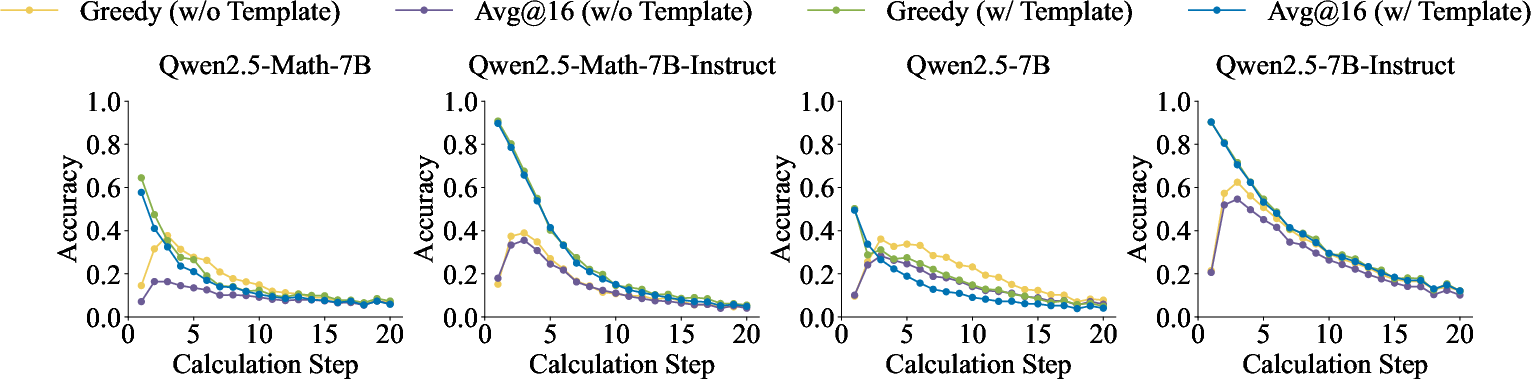
Figure 2: Performance of the Qwen2.5 series models on the RandomCalculation datasets under different configurations.
Detailed Analysis of Reward Configurations
The study further explores the effects of different reward configurations on model outputs. By measuring the similarity between model responses before and after RL using token-level KL divergence, the paper substantiates the hypothesis that MATH-500's spurious gains arise primarily from memorization. High similarity scores between pre- and post-RL outputs corroborate that the model retrieves memorized answers, rather than genuinely learning novel reasoning processes from RL.
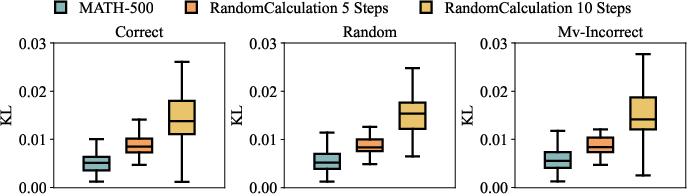
Figure 3: KL distance of model outputs before and after RL.
Implications and Recommendations
The research highlights the critical flaw of relying on contaminated datasets to evaluate the effectiveness of RL in enhancing reasoning capabilities of LLMs. The findings underscore the necessity to isolate genuine improvements in reasoning, contingent on the use of uncontaminated benchmarks. Consequently, the authors advocate for the adoption of leakage-free datasets, such as RandomCalculation, to ensure that evaluations reflect authentic advancements in mathematical reasoning.
Conclusion
The paper conclusively argues that the purported benefits of RL enhancements on Qwen2.5 series, demonstrated on contaminated datasets, are largely attributable to memorization rather than genuine reasoning capability improvements. This realization prompts a re-evaluation of benchmark datasets and calls for a more rigorous approach in future RL evaluations. The introduction of a clean dataset like RandomCalculation is a crucial step in enabling accurate assessments of LLMs' reasoning abilities when augmented by RL techniques.
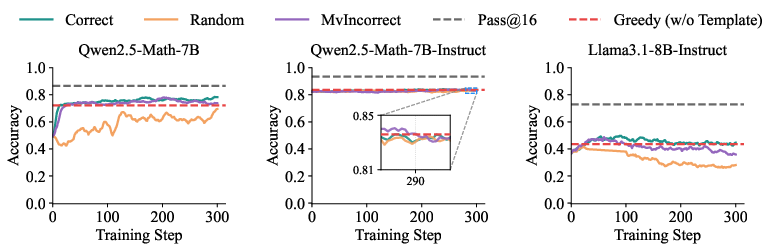
Figure 4: Accuracy on the MATH-500 for \qwenmathSevenB, \qwenmathSevenBInstruct, and \llamaEightBInstruct trained with RLVR under various reward signals.