- The paper introduces an adaptive clipping mechanism (PPO-lambda) that adjusts policy updates based on state importance, enhancing learning stability.
- It employs a Lagrangian formulation with a hyperparameter lambda to modulate clipping, leading to improved performance on Atari games and control tasks.
- Empirical results show that PPO-lambda outperforms traditional PPO in most scenarios, offering higher sample efficiency and more reliable policy updates.
An Adaptive Clipping Approach for Proximal Policy Optimization
This paper presents a novel approach for enhancing Proximal Policy Optimization (PPO) through an adaptive clipping mechanism designed to improve reinforcement learning performance. PPO is prevalent due to its simplicity and efficiency, utilizing first-order optimization methods. The proposed modification, termed PPO-λ, introduces a mechanism to adaptively control the clipping of policy updates based on a hyperparameter λ, aiming to address issues in traditional PPO where clipping might not always correspond to the importance of state information.
Introduction
Proximal Policy Optimization has been effective in various domains but presents limitations in adaptively adjusting policy updates according to state importance. PPO simplifies Trust Region Policy Optimization (TRPO) by employing a clipped surrogate objective to avoid large destructive policy updates. However, this clipping method in PPO can sometimes early eliminate important state updates and does not adapt to changing state importance throughout learning iterations.
Adaptive Clipping Mechanism
The key contribution of the paper is an adaptive clipping approach in policy learning that targets performance optimization at the state level. The method relies on a Lagrangian formulation allowing the adaptive adjustment of policy updates via a hyperparameter λ. This approach is designed to enhance policy reliability, particularly in states that traditional PPO might undervalue after multiple epochs of learning.





Figure 1: The snapshots of the first five steps taken in the Pong game when using the max pixel values of sampled frames.
Figure 2: The snapshots of the first five steps taken in the Pong game when using the mean pixel values of sampled frames.
Experimental Analysis
The empirical evaluation compares the performance of PPO-λ against standard PPO across both Atari game benchmarks and PyBullet control tasks, using average total rewards as the performance measure. In most scenarios, PPO-λ demonstrates superior or comparable performance to PPO, indicating its effectiveness in improving sample efficiency and final policy performance.
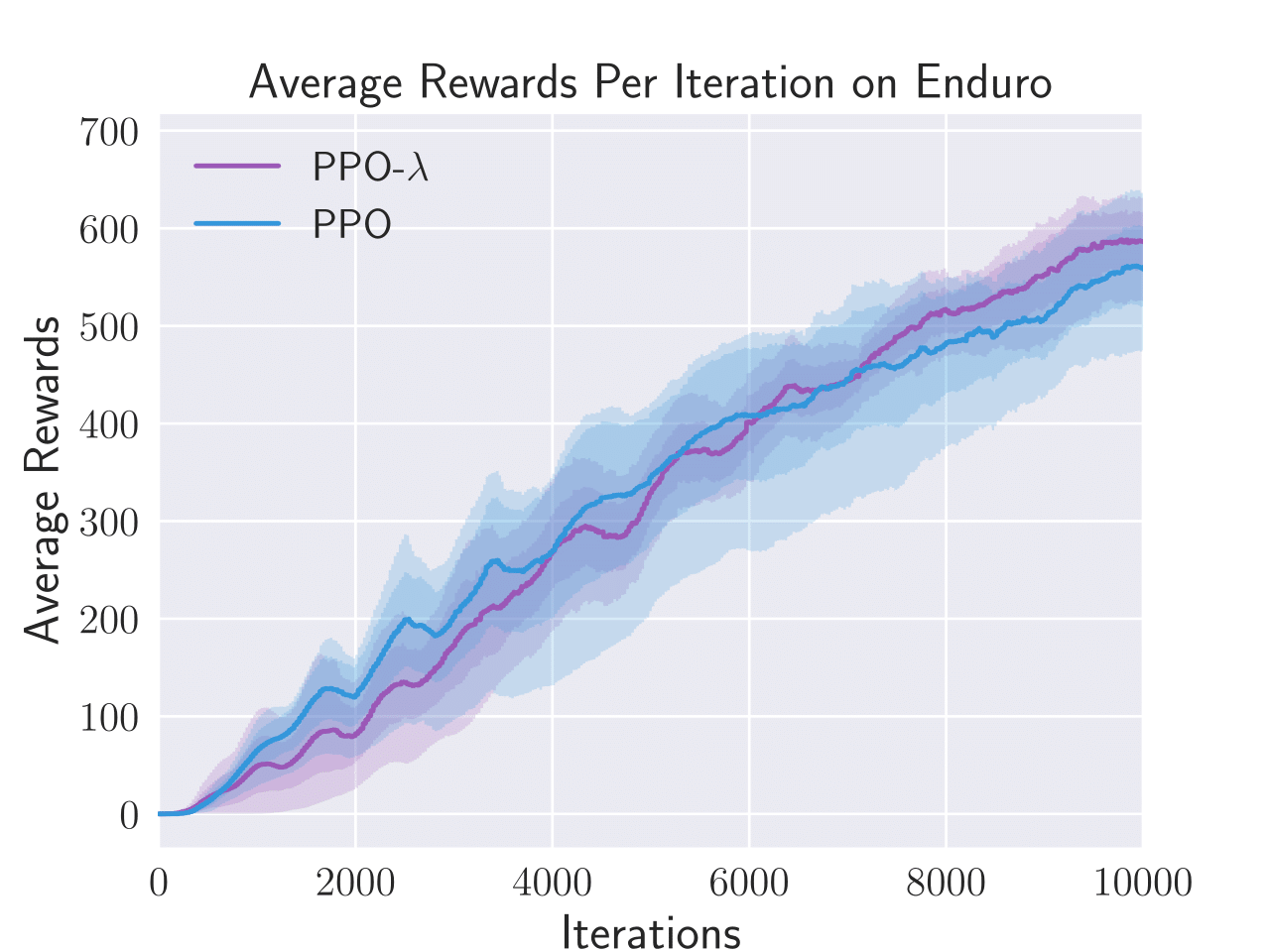
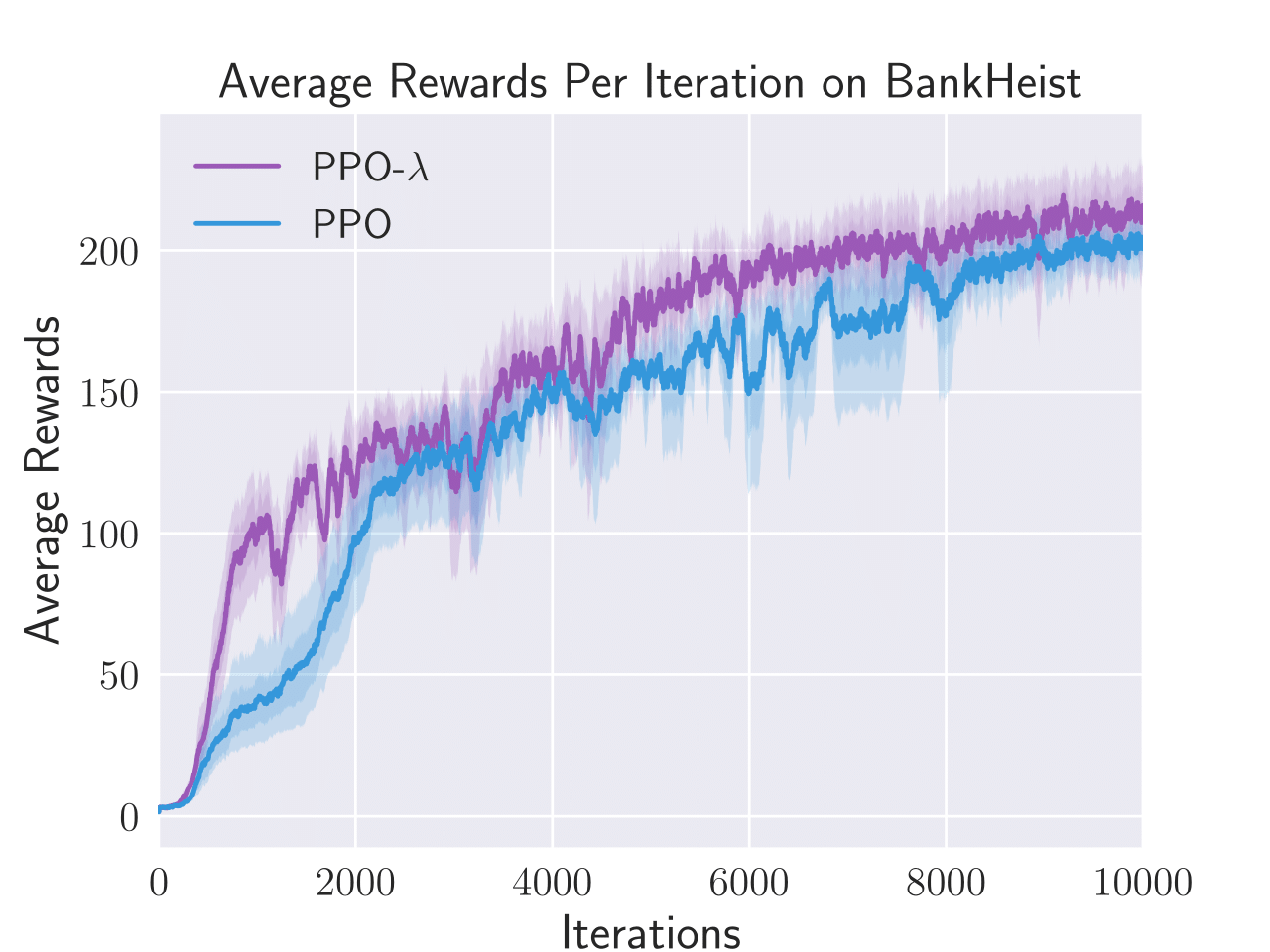
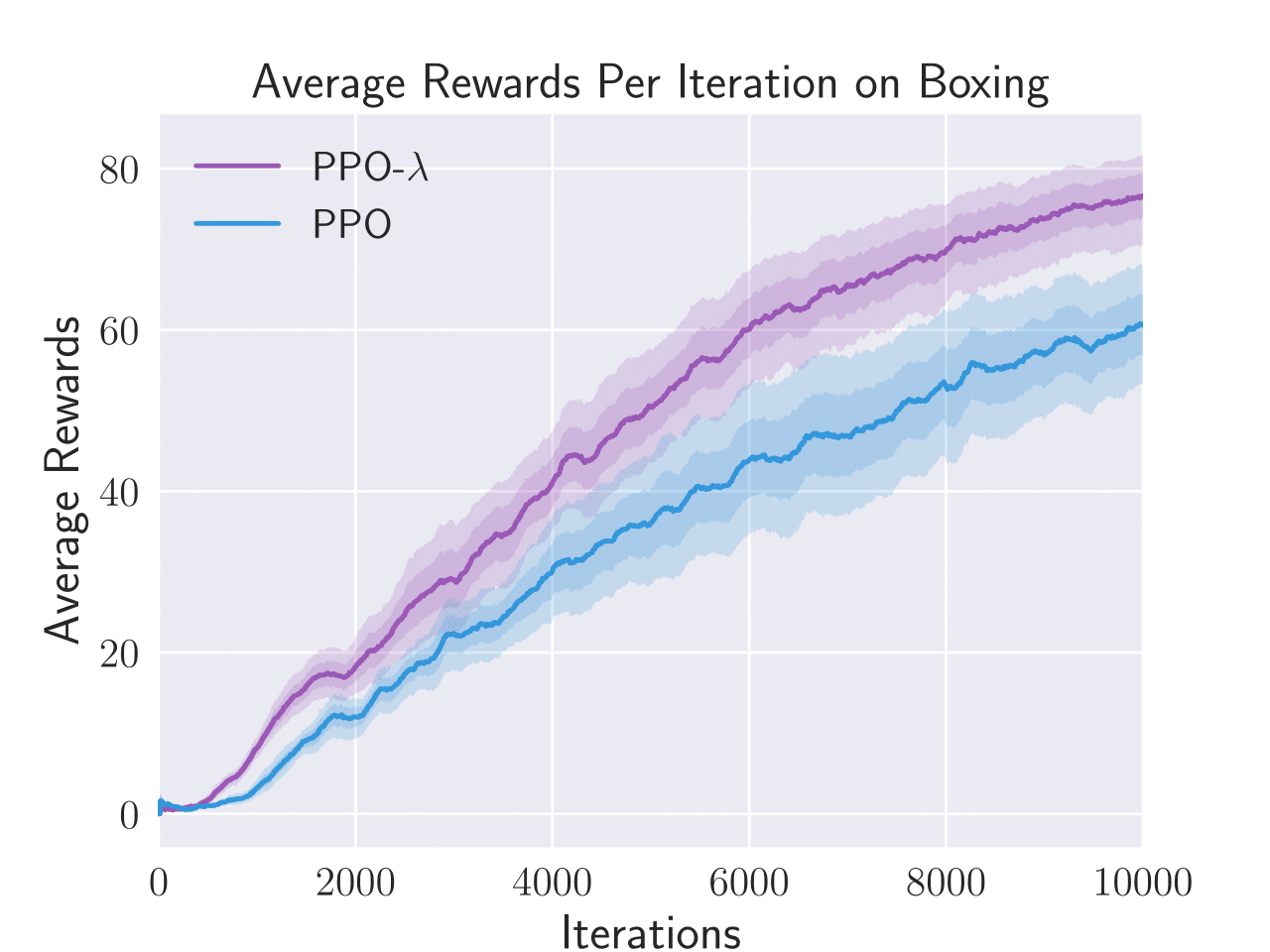
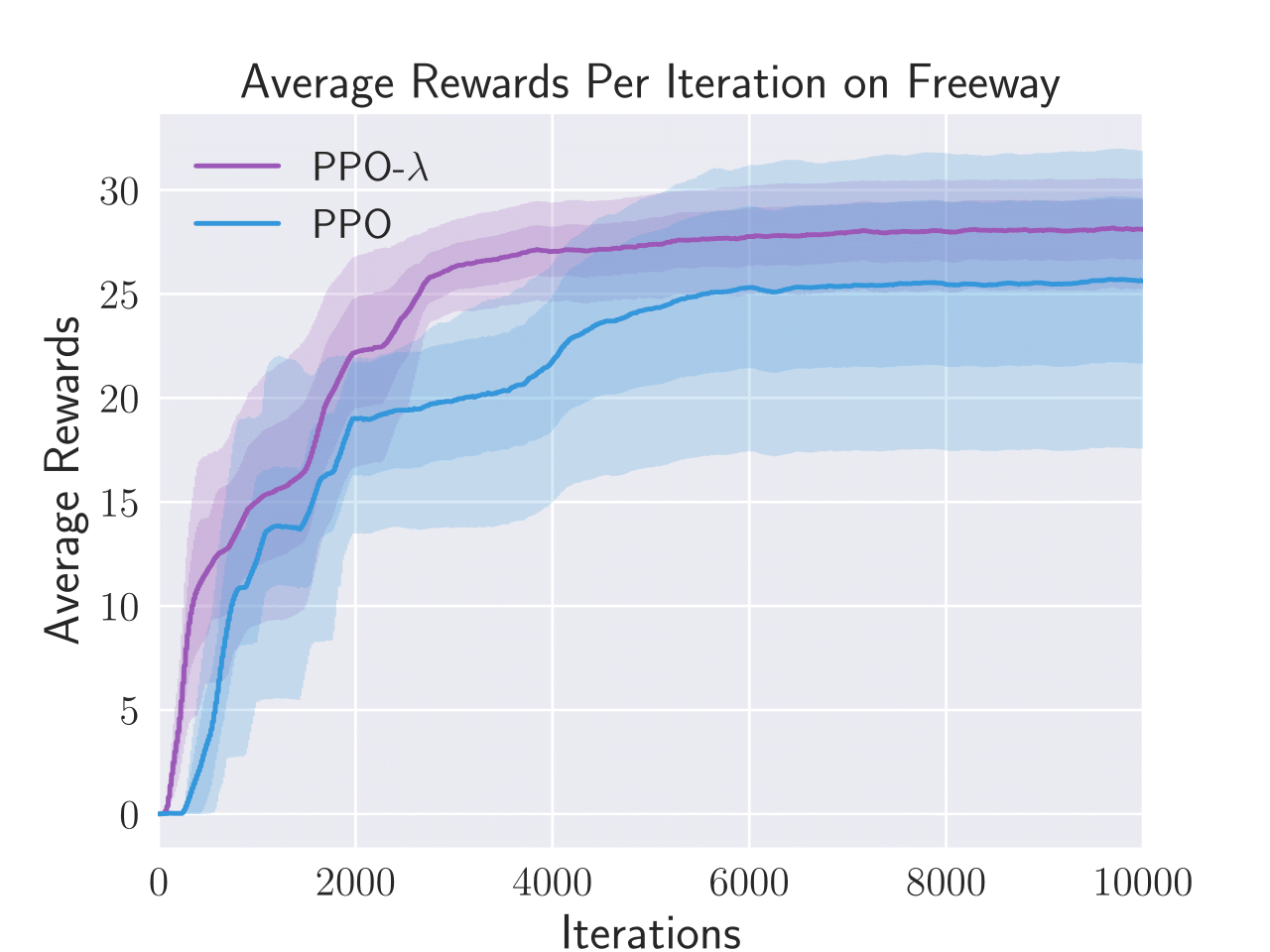
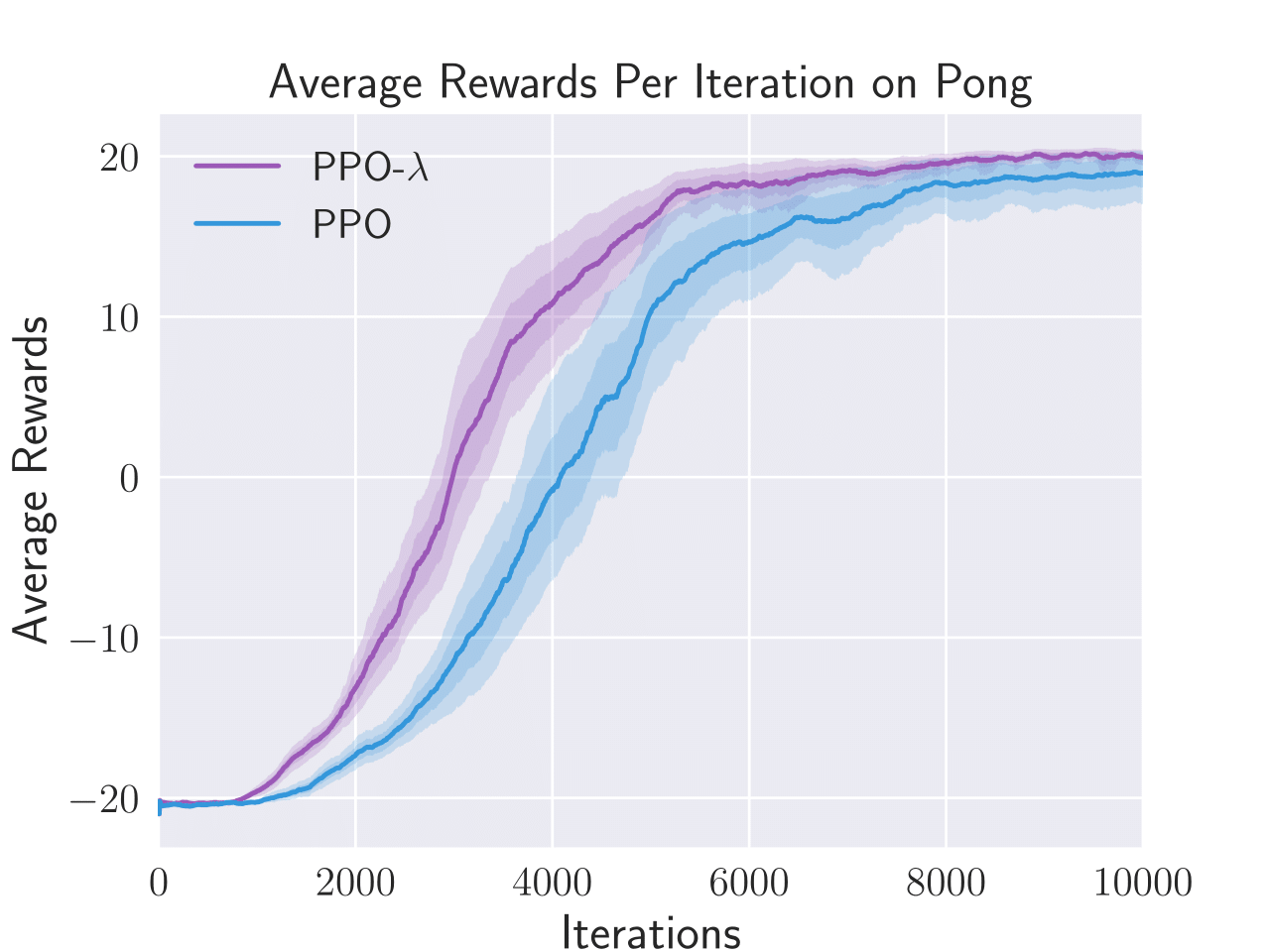
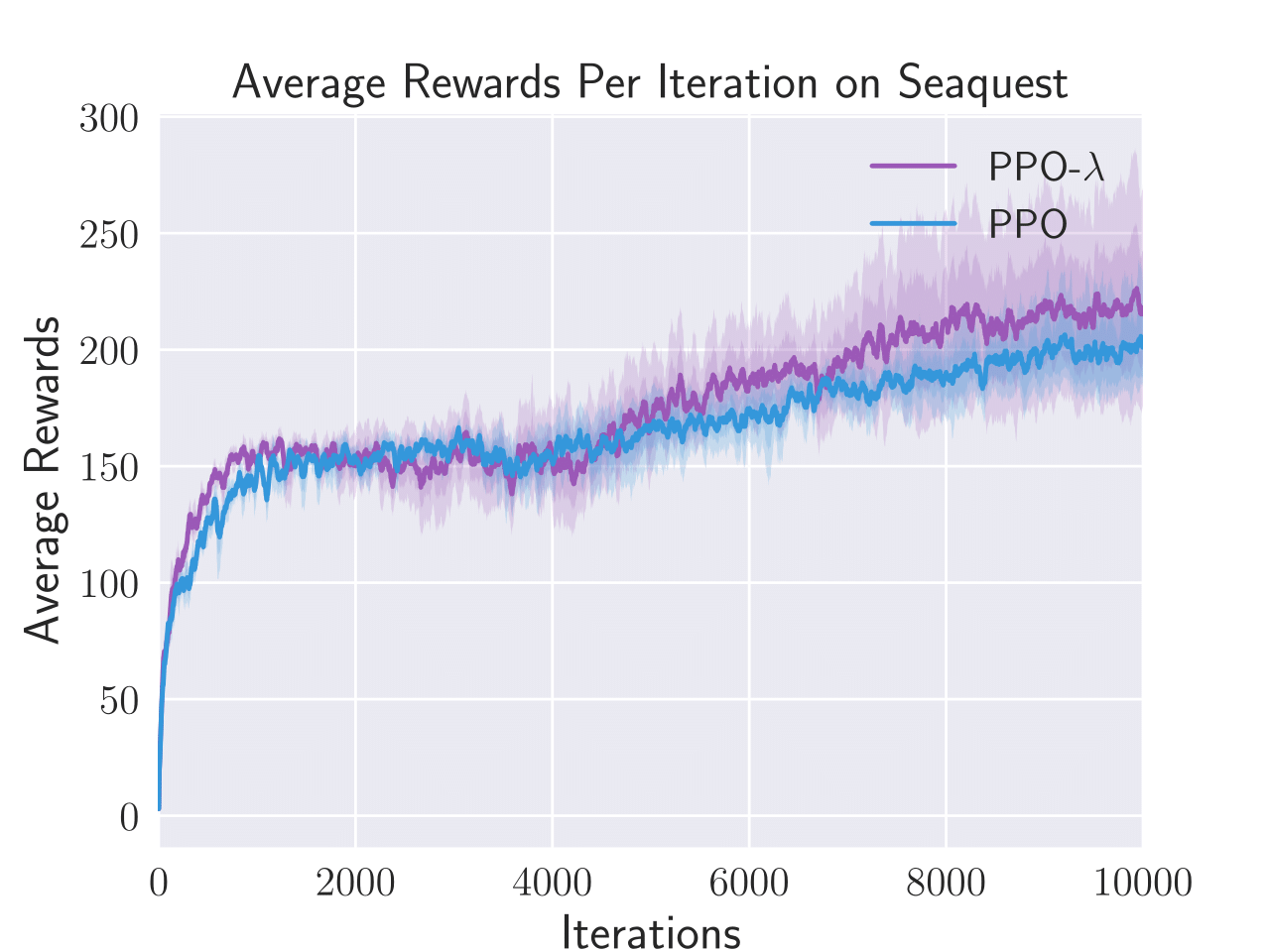
Figure 3: Average total rewards per episode obtained by PPO-λ and PPO on six Atari games, i.e. Enduro, BankHeist, Boxing, Freeway, Pong, and Seaquest.
PPO-λ consistently achieved higher sample efficiency metrics than standard PPO in five out of six tested Atari games. The algorithm specifically excelled in BankHeist, Boxing, and Pong, displaying a noticeable improvement in the capture and recovery of rewards throughout episodes.
Benchmark Control Tasks
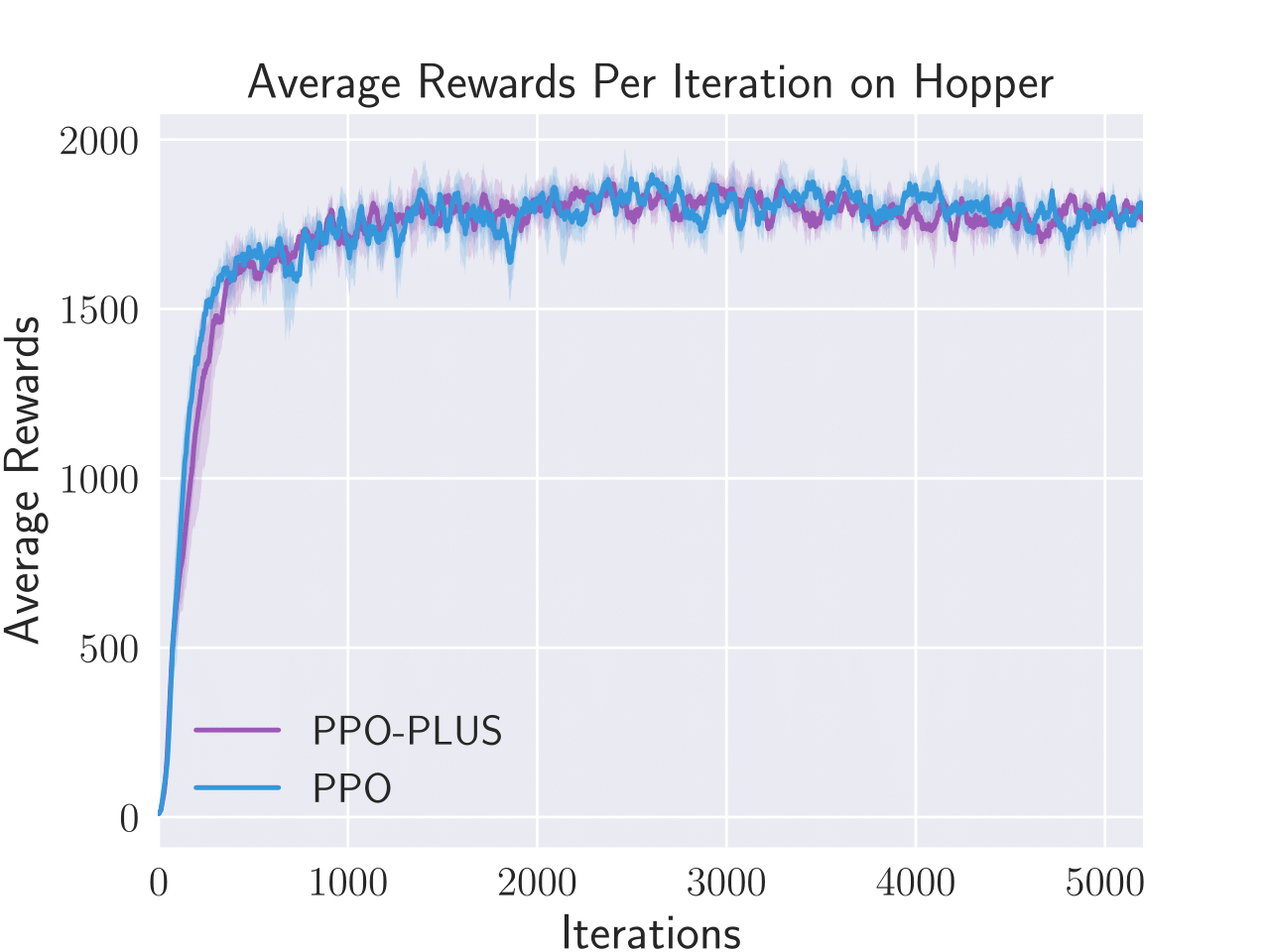
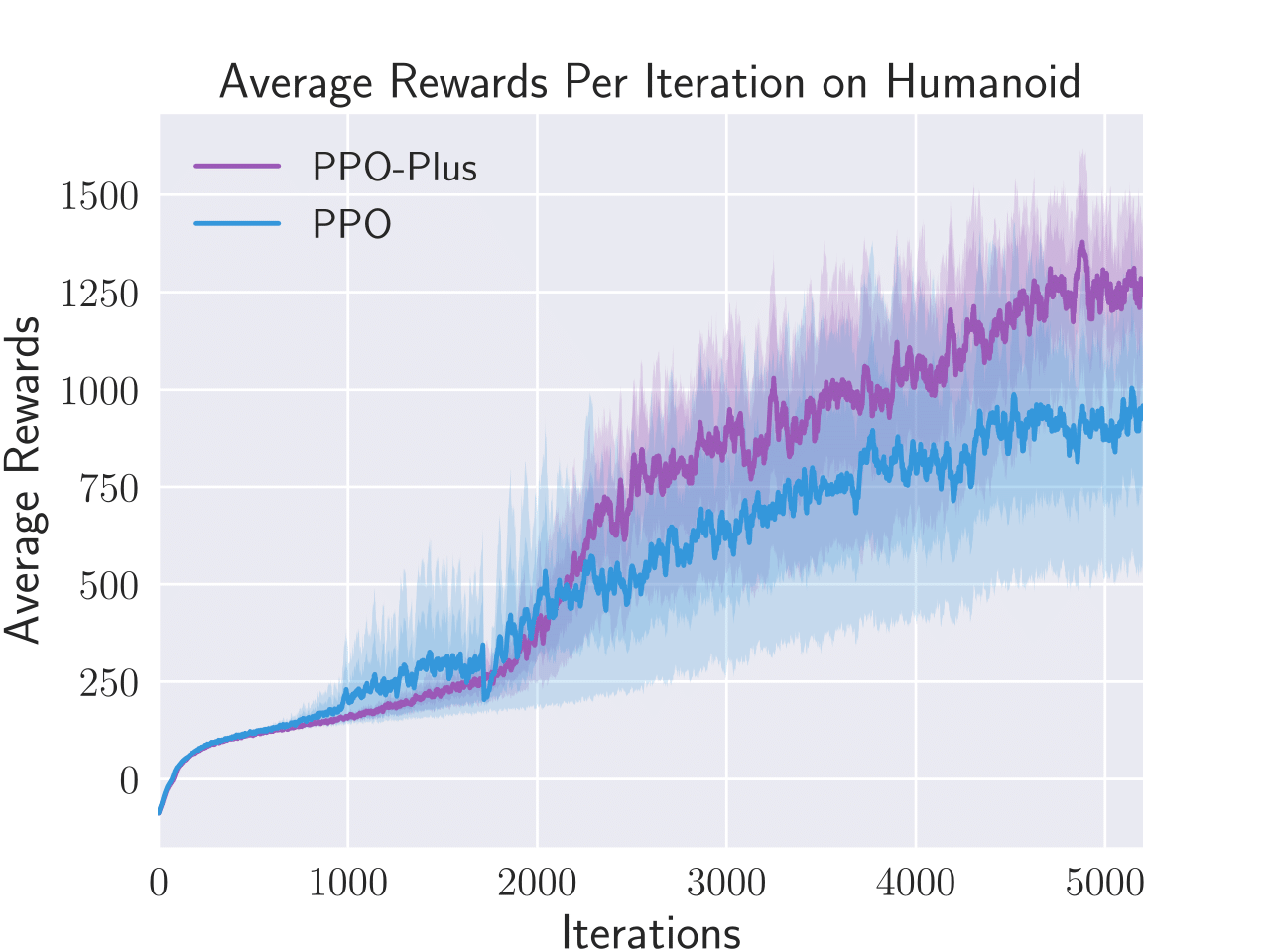
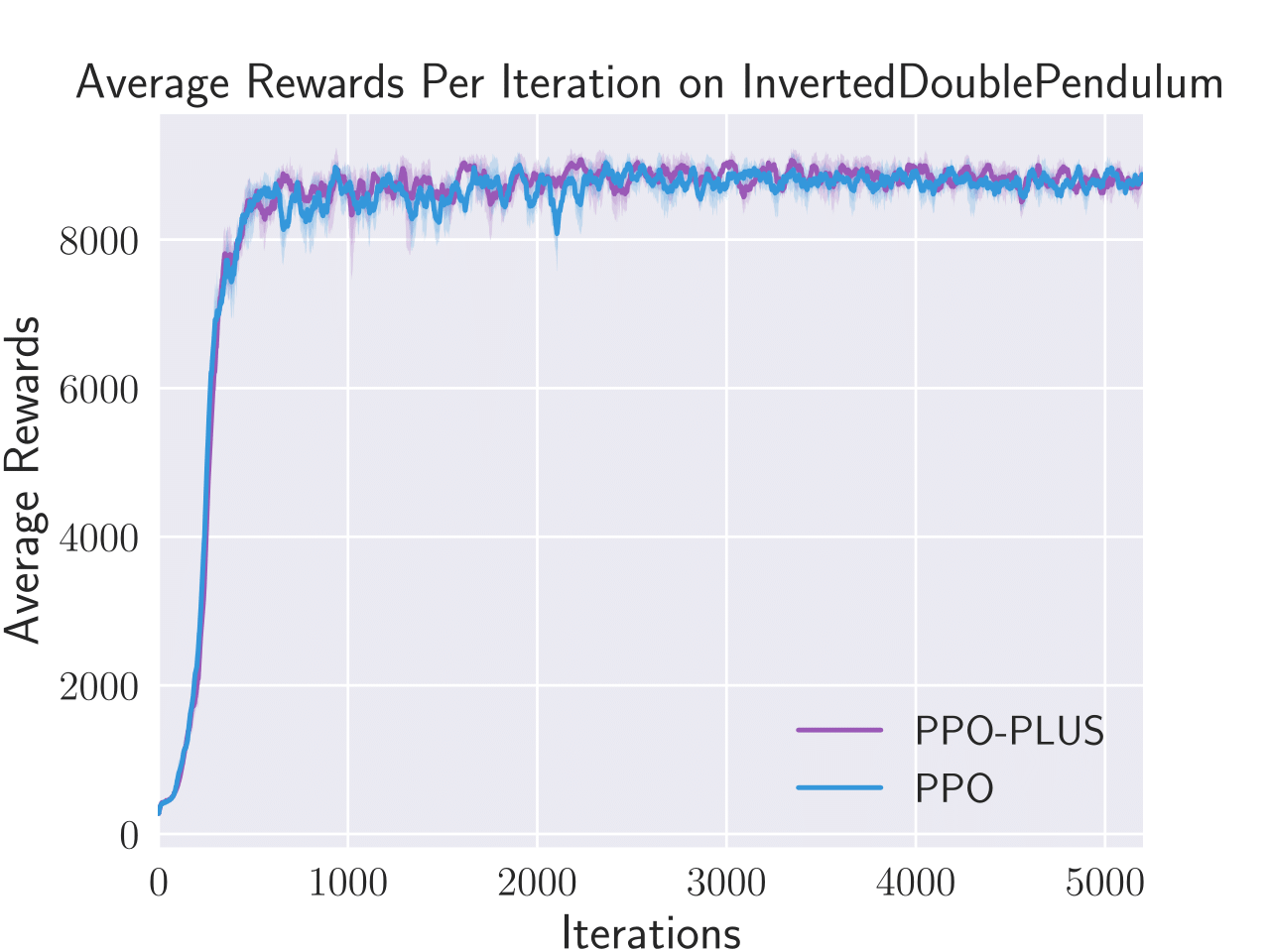
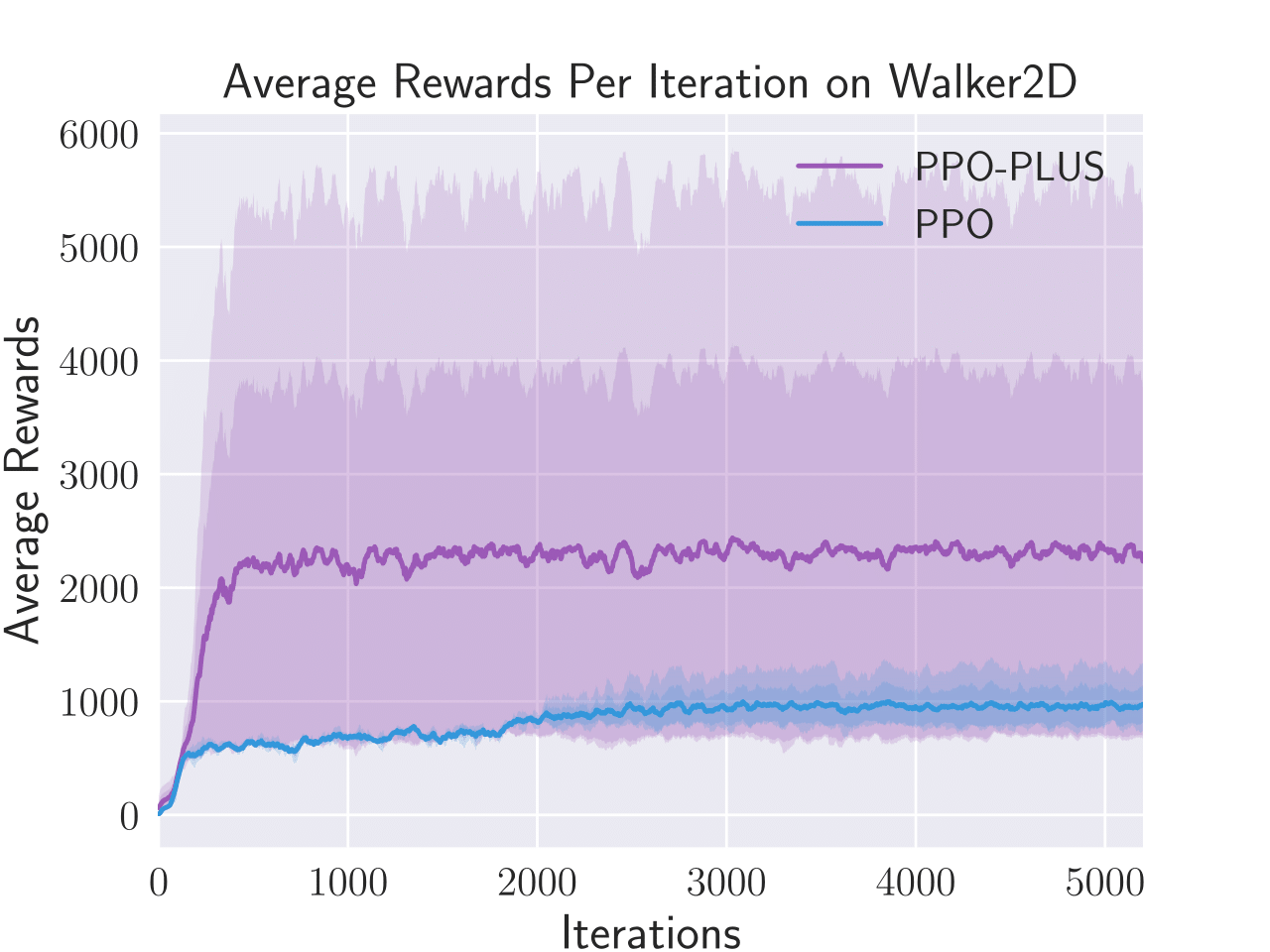
Figure 4: Average total rewards per episode obtained by PPO-λ and PPO on four benchmark control tasks, i.e. Hopper, Humanoid, Inverted Double Pendulum, and Walker2D.
PPO-λ was also tested on several control tasks, such as Humanoid and Walker2D, and demonstrated improved performance efficiency and adaptability in policy execution. The adaptive clipping mechanism helped in maintaining stability during policy updates across complex state spaces.
Conclusion
The introduction of an adaptive clipping mechanism in PPO-λ offers significant improvements in handling the variance of state importance during policy learning. Empirical evidence suggests enhanced reliability and efficiency of PPO-λ over traditional PPO algorithms. Future work proposes to extend this adaptive clipping mechanism to other RL frameworks like A3C and ACKTR and further investigate its applicability in real-world scenarios, potentially broadening its use in complex systems such as network management and resource allocation.