- The paper introduces a novel framework utilizing whitebox meta-models with linear classifier probes to assess model prediction confidence.
- It employs logistic regression and gradient boosting machines to integrate intermediate layer outputs, significantly improving noise resilience.
- The approach achieved an AUC of 0.88 in noisy datasets, demonstrating superior performance over traditional blackbox methods.
Introduction
This research investigates a novel approach to confidence scoring for deep learning models. It introduces a dual-model system composed of a base model and a whitebox meta-model equipped with linear classifier probes. This meta-model aptly predicts the success or failure of the base model on given tasks, offering enhanced reliability in scenarios where model confidence is paramount, such as medical diagnostics and autonomous driving.
Methodology
The proposed framework involves inserting linear classifier probes into the layers of a neural base model, allowing the meta-model to access and interpret internal intermediate representations. The architecture differentiates itself from traditional blackbox models by providing increased transparency and interpretability, making it "whitebox" (Figure 1).

Figure 1: A schematic overview of whitebox vs. blackbox meta-models.
The meta-model leverages logistic regression (LR) and gradient boosting machines (GBM) to process outputs from the probes embedded within the base model. The primary objective of the meta-model is to derive a confidence score from these probes that reflects the likelihood of correct output. The introduction of probes at varying depths facilitates capturing both basic and abstract patterns in data, which significantly enhances decision-making under uncertain conditions.
Experimental Setup
Experiments were conducted on CIFAR-10 and CIFAR-100 datasets under two conditions: Clean/Clean, where both models were trained on clean data, and Noisy/Noisy, where label noise was introduced. In these settings, the meta-model exhibited superior performance in filtering out low-confidence instances compared to blackbox baselines (Figure 2).
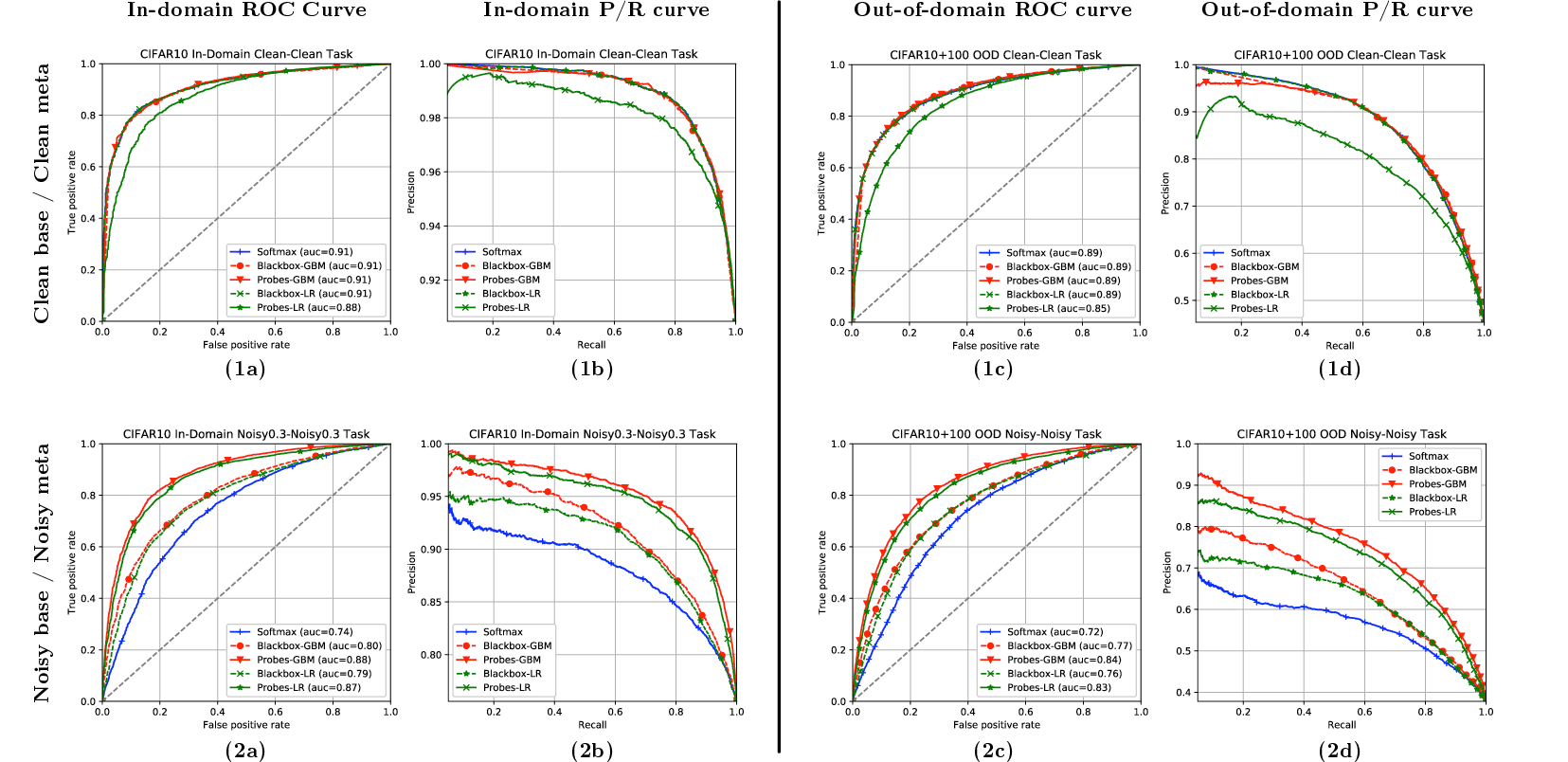
Figure 2: Performance metrics for models in Clean/Clean'' andNoisy/Noisy'' conditions, highlighting AUC and ROC curves.
The whitebox models demonstrated robustness against noisy data and effectively adapted probe selection to ignore negatively impacted layers, recovering relevant features from deeper network layers.
Results and Analysis
The whitebox meta-model reached an AUC value of 0.88 in noisy environments, surpassing the blackbox counterparts significantly. The model's clarity in leveraging intermediate neural states renders it adept at dealing with both in-domain and out-of-domain prediction uncertainties. The importance of individual features was quantified (Figure 3), revealing shifts in feature dependency from final to intermediate layers in noisy conditions, suggesting increased robustness.
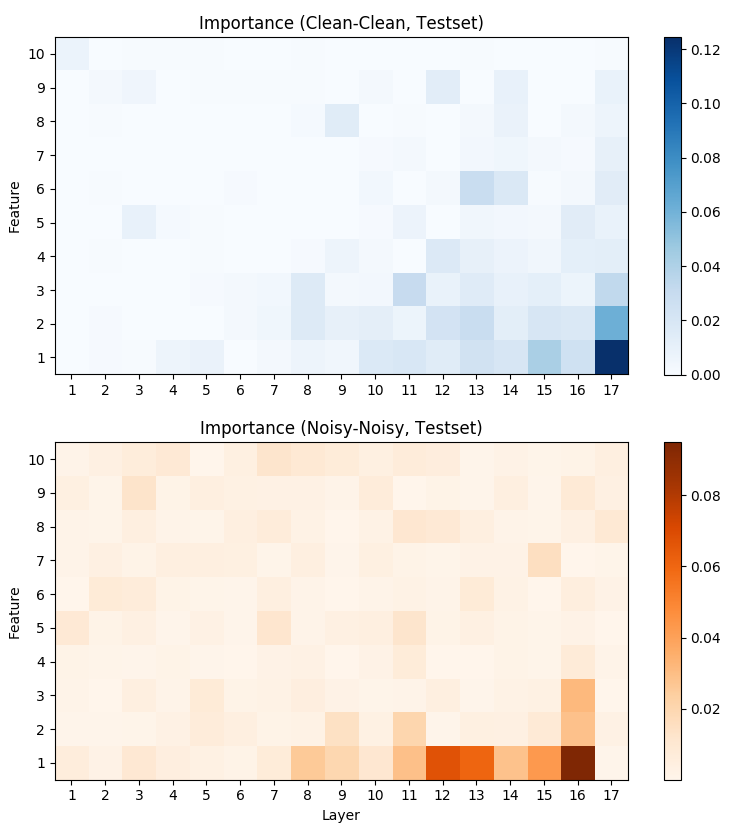
Figure 3: Feature importance scores for Clean-Clean (top) and Noisy-Noisy (bottom) conditions across probe layers.
Conclusion
The research asserts the efficacy of whitebox meta-models in providing reliable confidence scores by utilizing internal model signals processed through linear probes. This approach demonstrates substantial improvement in out-of-domain handling and noise resilience, making it an important technique for critical applications requiring stringent quality of predictions.
Future directions could involve the integration of other interpretability tools and uncertainty measures for compounded predictive accuracy and model confidence, enhancing capabilities in diverse AI-driven tasks.