Deep Think with Confidence
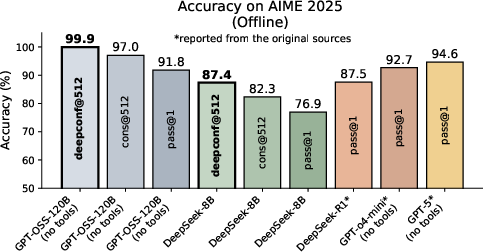
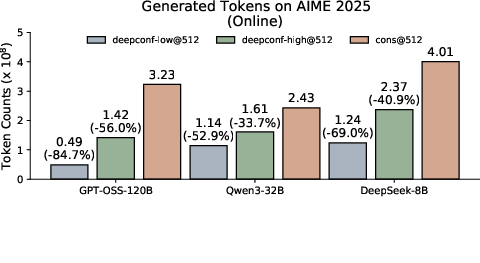
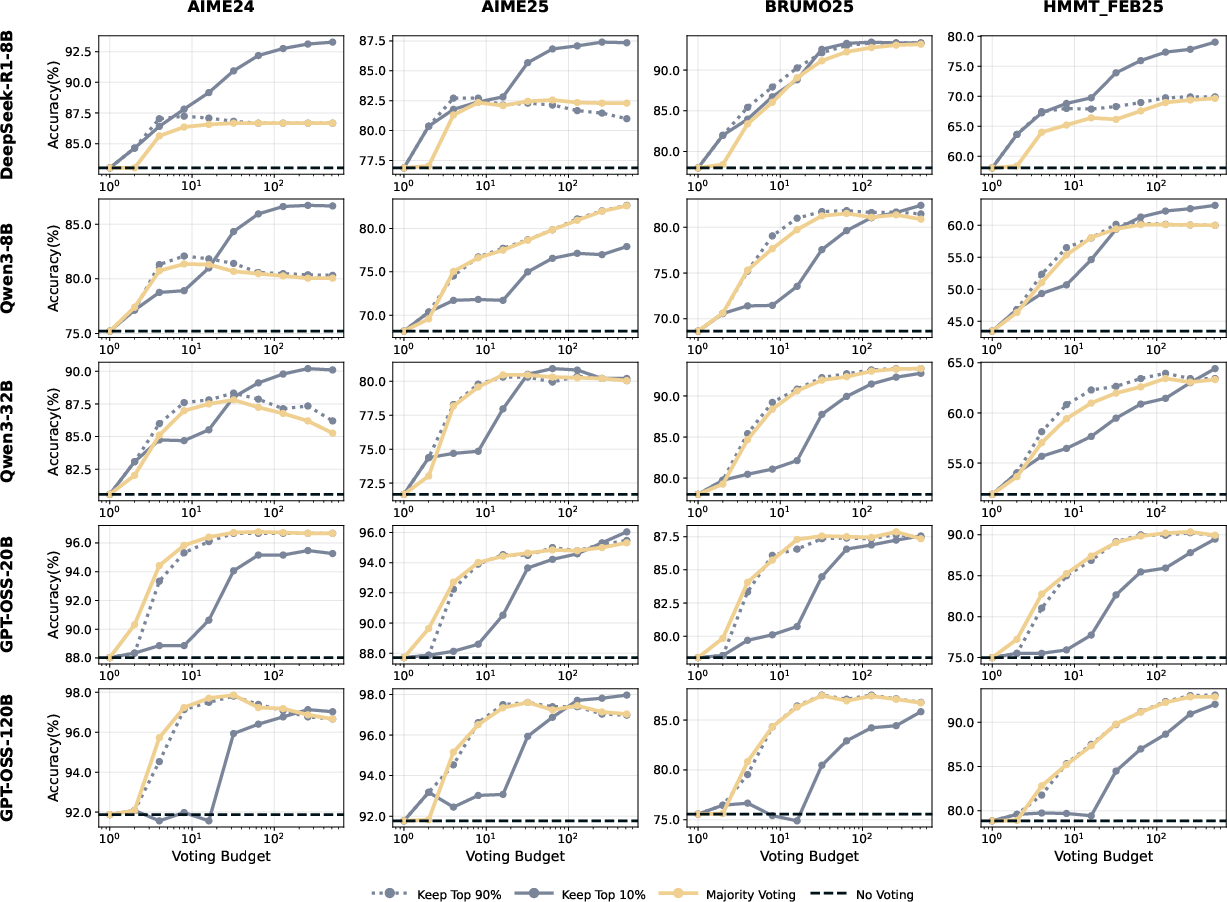
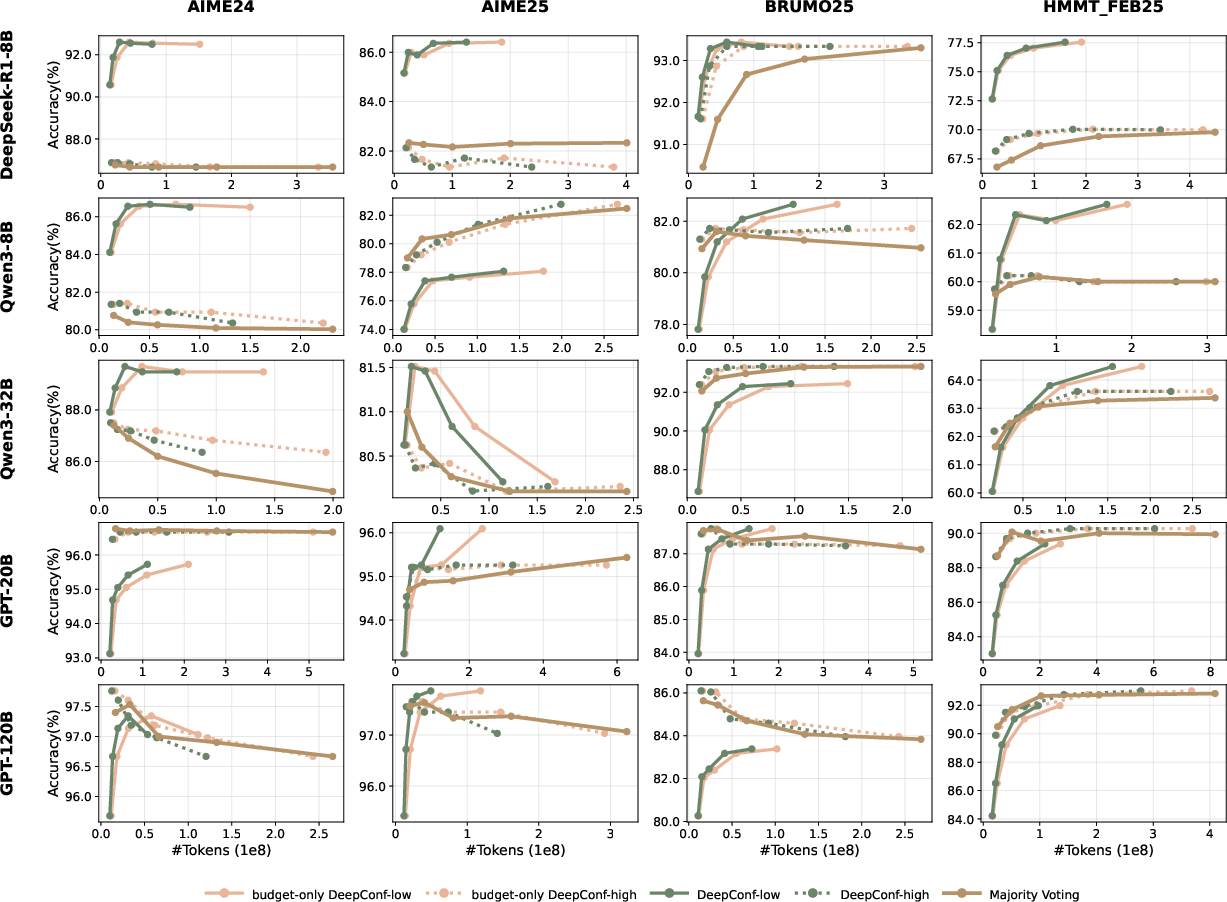
Abstract: LLMs have shown great potential in reasoning tasks through test-time scaling methods like self-consistency with majority voting. However, this approach often leads to diminishing returns in accuracy and high computational overhead. To address these challenges, we introduce Deep Think with Confidence (DeepConf), a simple yet powerful method that enhances both reasoning efficiency and performance at test time. DeepConf leverages model-internal confidence signals to dynamically filter out low-quality reasoning traces during or after generation. It requires no additional model training or hyperparameter tuning and can be seamlessly integrated into existing serving frameworks. We evaluate DeepConf across a variety of reasoning tasks and the latest open-source models, including Qwen 3 and GPT-OSS series. Notably, on challenging benchmarks such as AIME 2025, DeepConf@512 achieves up to 99.9% accuracy and reduces generated tokens by up to 84.7% compared to full parallel thinking.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
- Generalization beyond math-heavy reasoning is untested; performance on coding tasks, commonsense QA, multi-hop retrieval, and open-ended generation remains unknown.
- Language and domain robustness are unstudied; all evaluations are in English STEM/math—no results for other languages, humanities, or multi-modal settings.
- Contamination risk is not addressed; near-saturation on small benchmarks like AIME 2025 (30 problems) warrants checks for train/test leakage and reproducibility on contamination-controlled splits.
- Only majority voting is used as the baseline; comparisons to stronger test-time methods (ESC, RASC, Dynasor, Soft-SC, ranked voting, verifier-augmented voting) are missing.
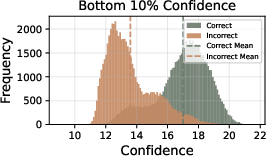
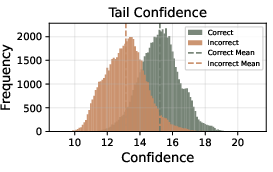
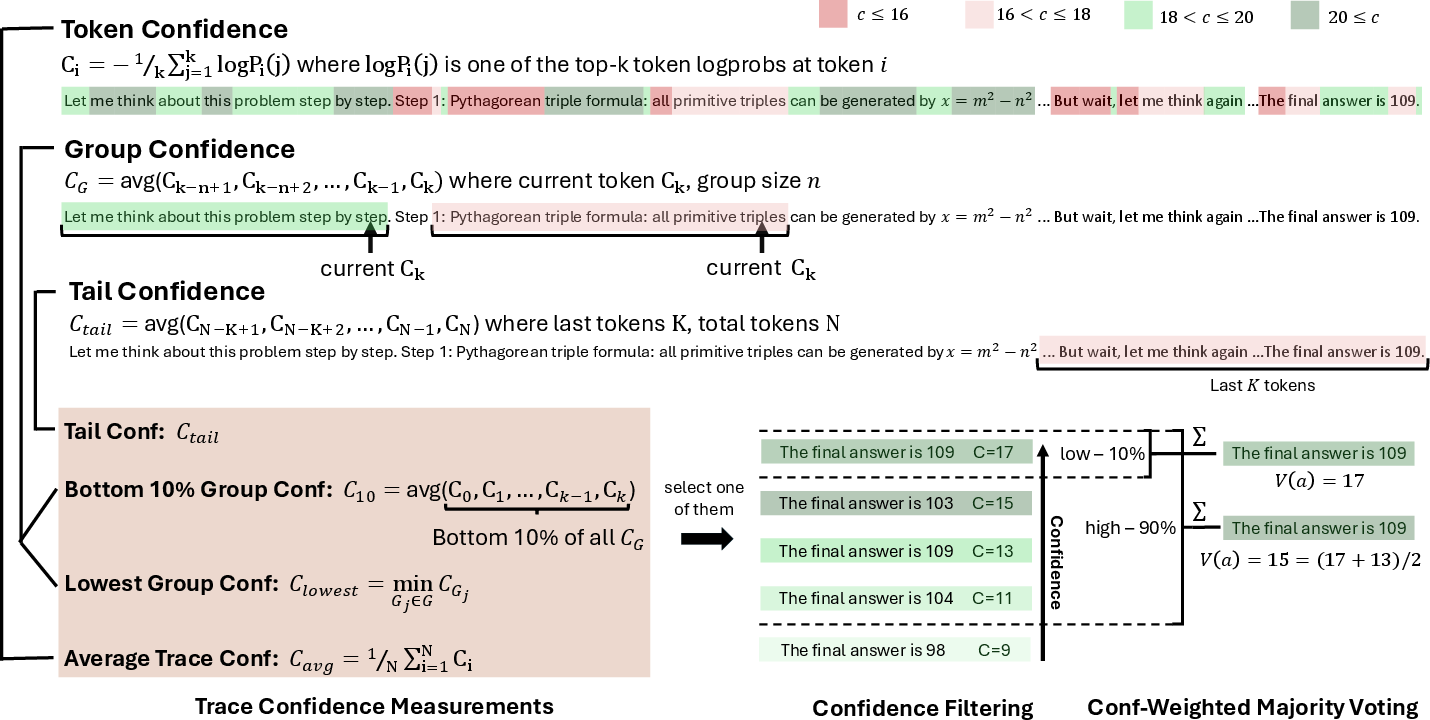
- Confidence metric design is largely heuristic; there is no principled justification for bottom-10% or tail-window choices or for the linear weighting of votes by raw confidence.
- Sensitivity to the confidence metric’s hyperparameters is underexplored; e.g., top-k size in token confidence, sliding-window length, stride, overlap, and the “tail” token count are not systematically tuned or justified across tasks.
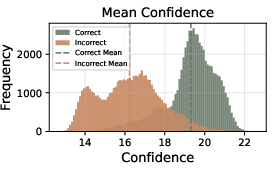
- The numerical direction and calibration of confidence scores are not rigorously validated; reliability diagrams, ECE/MCE, or risk-coverage analyses for trace selection are absent.
- Overconfidence on incorrect traces can harm accuracy under aggressive filtering; the paper lacks strategies to detect or mitigate “confidently wrong” cases at runtime.
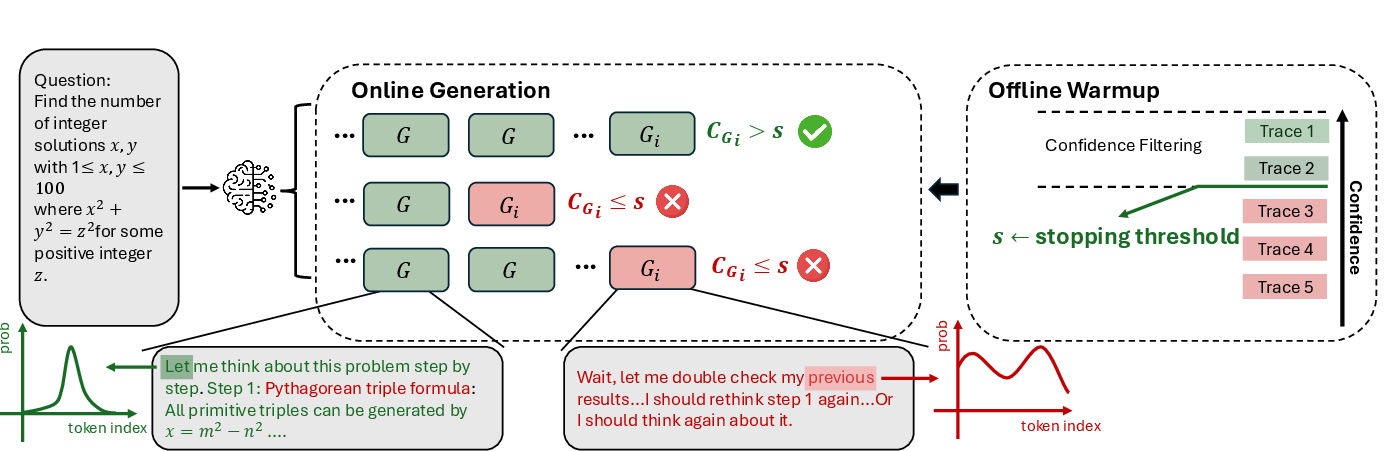
- Thresholding in online mode relies on per-problem warmup percentile estimates; the stability of percentile-based thresholds with small warmup sizes and their transferability across problems is unclear.
- Warmup overhead may dominate at small budgets (e.g., 16 full traces when B=32); criteria for adaptively sizing or amortizing warmup across problems are not studied.
- The consensus stopping rule (τ=0.95) is ablated on a single model/dataset; its robustness across models, tasks, and budgets and principled selection guidelines remain open.
- Early-stop decisions may be brittle to temporary dips in confidence; the effect of patience, hysteresis, or adaptive thresholds to avoid false terminations is not analyzed.
- Local confidence minima (lowest-group) may penalize legitimate exploratory reasoning segments; error analyses quantifying false-positive stops vs true rejections are missing.
- Weighted voting uses raw confidence linearly; alternative transforms (temperature scaling, rank-based weights, monotone nonlinearities) and their effect on robustness are not explored.
- Interaction with chain length is not examined; whether DeepConf biases toward shorter or longer chains, and how that impacts solution quality or spurious shortcuts, is unknown.
- Token savings are reported, but wall-clock latency, throughput, and memory overhead (e.g., computing top-logprobs, sliding windows) are not measured, hindering deployment cost-benefit assessment.
- Dependence on access to per-token top-k logprobs limits applicability to many production APIs; feasibility with restricted or proprietary endpoints is not addressed.
- The method assumes answer-string equality (e.g., via \boxed{} extraction); robustness to formatting variability, unit conversions, or equivalent expressions is not evaluated.
- Diversity loss from aggressive filtering is plausible; the trade-off between confidence concentration and exploration of minority-but-correct reasoning is not quantified.
- No analysis of failure modes by problem type; which categories (algebra vs geometry, multi-step vs single-step) benefit or suffer is unknown.
- Scaling behavior for very large budgets or very small budgets (beyond K∈{32,…,512}) and under different decoding temperatures/top-p settings is uncharacterized.
- Window-size choices (e.g., 2,048) may be mismatched to shorter traces; how metrics behave on short chains and variable-length normalization is not specified.
- The relationship between offline and online policies lacks theory; no guarantees bound the gap between offline optimal filtering and online early stopping as a function of warmup size.
- Global vs per-problem thresholding trade-offs are not studied; learning global thresholds or per-model calibrations that transfer across tasks may reduce warmup cost.
- Combining DeepConf with external verifiers, tool use, or programmatic checking (e.g., symbolic solvers) is not explored; potential compound gains are unknown.
- Interaction with training-time confidence learning (e.g., confidence tokens, calibration finetuning) is untested; whether training can strengthen DeepConf’s signals is open.
- Effects on user-facing outputs (e.g., truncated chains due to early stop) and UX-driven requirements (explanations, partial credit, or abstention) are not considered.
- Fairness and bias implications are unaddressed; confidence-based filtering may preferentially select certain linguistic styles or solution formats.
- Reproducibility details for the confidence definition are ambiguous; the experiments’ effective top-k for confidence computation and its alignment with the vLLM implementation need precise specification.
- Statistical uncertainty is not reported; confidence intervals or significance tests over 64 runs would clarify the robustness of the observed gains.
- Benchmark breadth is limited; results on larger, more diverse, and harder held-out sets (e.g., Olympiad-level math beyond AIME/HMMT, BIG-bench Hard, MATH500, HumanEval+/MBPP for code) would strengthen claims.
- Adaptive selection of retention ratio (η) per problem is not attempted; learning or inferring η from warmup signals could mitigate the risks of overly aggressive or conservative filtering.
Practical Applications
Immediate Applications
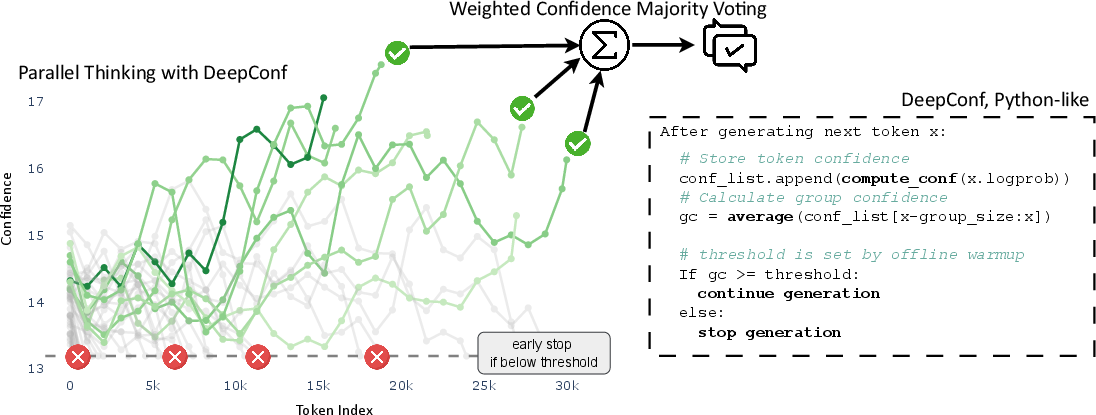
- Sector: AI infrastructure and cloud serving; Use case: Reduce inference cost and latency for reasoning-heavy endpoints by early-stopping low-quality traces and weighting high-confidence traces in voting; Tools/Workflows/Products: vLLM-based “confidence-aware sampler” (minimal patch described in paper), OpenAI-compatible proxy that enables enable_conf/window_size/threshold with logprobs, autoscaler using consensus τ to stop early; Assumptions/Dependencies: Access to per-token logprobs/top-logprobs, ability to run Ninit warmup traces, tuning of η and τ for target workloads, workloads tolerant of multi-sample parallel reasoning.
- Sector: Enterprise assistants and RAG; Use case: Confidence-weighted majority voting for complex Q&A and policy lookup to suppress low-quality chains and reduce hallucinations while cutting tokens by 40–80%; Tools/Workflows/Products: LangChain/LlamaIndex node for DeepConf-weighted aggregation and online early termination, “top-10% confident traces only” answerer, abstain or escalate on low β consensus; Assumptions/Dependencies: Multi-sample generation budget available, stable confidence–correctness correlation on target domain, safe fallback/escalation path for low-consensus queries.
- Sector: Customer support and IT ops; Use case: Faster, more reliable triage and troubleshooting by terminating meandering traces (e.g., repeated “wait/however/think again”) and focusing votes on stable plans; Tools/Workflows/Products: Confidence-gated CoT behind-the-scenes; tickets closed when β ≥ τ; Assumptions/Dependencies: Agent stack can sample multiple solutions; telemetry to log confidence and consensus for audit.
- Sector: Education (math and STEM tutoring); Use case: Higher-accuracy solutions and cleaner explanations by selecting tail- and bottom-10%-confident traces; lower compute on student devices or school servers; Tools/Workflows/Products: Tutor backend with DeepConf-high (safer) by default, DeepConf-low for competitions or expert mode; Assumptions/Dependencies: Math/logic tasks similar to AIME/HMMT/GPQA; hidden CoT usage complies with platform policies.
- Sector: Software engineering (code generation and review); Use case: Generate multiple candidate patches and terminate low-confidence reasoning paths early; weight remaining by confidence plus unit-test pass rates; Tools/Workflows/Products: IDE plugin that runs DeepConf-weighted best-of-N with test harnesses; Assumptions/Dependencies: Access to logprobs and tests; local confidence signals remain predictive for coding models and prompts.
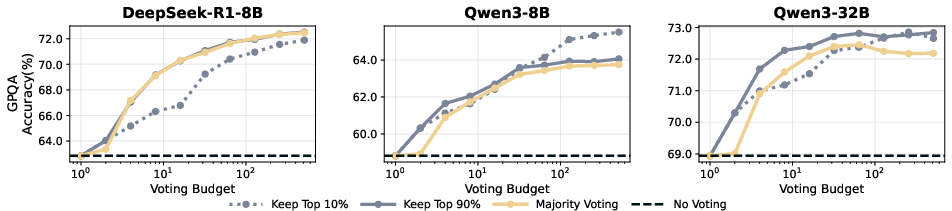
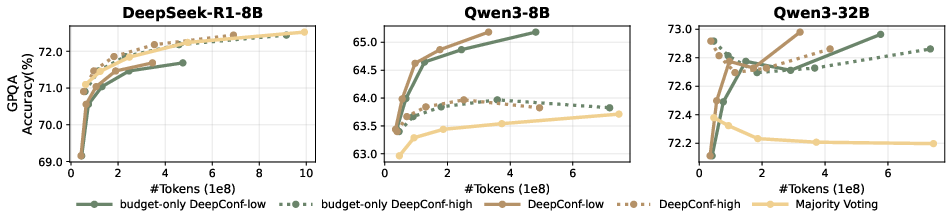
- Sector: Scientific research assistants; Use case: STEM QA and derivation checks with confidence-weighted traces, abstaining or requesting citations when tail confidence is low; Tools/Workflows/Products: GPQA-style pipelines using DeepConf-high for reliability; Assumptions/Dependencies: Domain prompts elicit reasoning where local confidence tracks correctness; human-in-the-loop for critical outputs.
- Sector: Legal/compliance and policy summarization; Use case: Confidence-weighted consolidation of multi-trace summaries; conservative high-retention (η=90%) to maintain diversity and reduce overconfident errors; Tools/Workflows/Products: Compliance assistant with consensus gating and exportable confidence logs for audit; Assumptions/Dependencies: Strict human review; jurisdiction-specific validation; document privacy constraints.
- Sector: Finance (report drafting, risk narratives, reconciliation); Use case: Reduce compute and improve reliability for complex narratives by gating on lowest-group-confidence and consensus; Tools/Workflows/Products: “Conservative mode” using DeepConf-high to avoid sharp regressions; Assumptions/Dependencies: Clear escalation policy for low-consensus cases; robust prompt templates.
- Sector: Model routing and escalation; Use case: Use confidence and β to decide when to stop, continue, or escalate to a larger model/tool (calculator, code runner, theorem prover); Tools/Workflows/Products: Router service that fuses DeepConf with tool-calling heuristics; Assumptions/Dependencies: Tool latency budget; calibration to prevent “confidently wrong” routes.
- Sector: Safety and reliability engineering; Use case: Trigger selective abstention or human review when lowest-group-confidence dips below calibrated threshold; Tools/Workflows/Products: Safety wrapper exposing stop_reason and confidence traces to monitoring; Assumptions/Dependencies: Proper threshold calibration per domain; false-positive/negative trade-off management.
- Sector: Data curation and training; Use case: Select high-confidence CoT traces to construct cleaner supervised fine-tuning datasets or to self-train verifiers; Tools/Workflows/Products: Dataset filter that keeps top-η confidence segments and discards low-confidence spans; Assumptions/Dependencies: License to store/use internal probabilities; risk of confidence-induced bias in datasets.
- Sector: Benchmarking and evaluation; Use case: Re-evaluate majority-vote baselines using confidence-weighted voting to reach higher accuracy with fewer tokens; Tools/Workflows/Products: Open-source evaluation harness with DeepConf metrics (tail, bottom-10%, lowest-group); Assumptions/Dependencies: Comparable sampling frames across methods; reproducible seeds and logging.
- Sector: Batch inference and SLA management; Use case: Adaptive budgets per problem difficulty (β) to meet latency/throughput SLOs while maximizing accuracy; Tools/Workflows/Products: Inference scheduler that prunes low-confidence traces early and stops at consensus; Assumptions/Dependencies: Accurate difficulty proxies from β; queueing and admission control integrated with serving.
- Sector: Edge and on-device AI; Use case: Run smaller models (e.g., 8B) with DeepConf to approach larger-model accuracy on reasoning tasks while saving battery and bandwidth; Tools/Workflows/Products: Mobile SDK exposing confidence-gated sampling with small Ninit; Assumptions/Dependencies: On-device access to top-logprobs; memory for sliding windows; privacy constraints.
- Sector: Search and citation assistants; Use case: Only surface claims when tail confidence exceeds threshold and provide tool-verified citations; Tools/Workflows/Products: “Cite-on-confidence” mode that couples DeepConf with retrieval and verification; Assumptions/Dependencies: External verifier availability; domain-appropriate thresholds to avoid over-filtering.
Long-Term Applications
- Sector: Training efficiency (RL/fine-tuning); Use case: Incorporate confidence-based early stopping into RL rollouts to cut sample cost and focus learning on promising trajectories; Tools/Workflows/Products: RL objectives that penalize low local confidence; curriculum that adapts by β; Assumptions/Dependencies: Access to training loops; stability under confidence-driven truncation; further research on gradient signal quality.
- Sector: Confidence calibration and uncertainty quantification; Use case: Improve robustness where models are “confidently wrong” via calibrated thresholds, temperature scaling, or learned confidence tokens combined with local metrics; Tools/Workflows/Products: Calibration toolkit for tail and lowest-group signals; Assumptions/Dependencies: Additional validation datasets and domain-specific calibration procedures.
- Sector: Cross-model ensembles; Use case: Pool traces from multiple models and select by per-trace confidence to surpass single-model majority voting; Tools/Workflows/Products: Multi-model aggregator with confidence normalization across vocabularies; Assumptions/Dependencies: Comparable logprob access across vendors; inter-model calibration is nontrivial.
- Sector: Verified reasoning systems; Use case: Jointly use DeepConf with external verifiers (checkers, solvers, unit tests) to terminate or continue reasoning adaptively; Tools/Workflows/Products: “Confidence + verification” controller that spends compute where verification fails or confidence drops; Assumptions/Dependencies: Tool coverage; error-tolerant orchestration; latency budgets.
- Sector: Hardware-aware inference; Use case: GPU/TPU schedulers that natively support confidence-driven early stop and dynamic batch compaction for multi-tenant workloads; Tools/Workflows/Products: Serving kernels exposing streaming logprobs and windowed metrics; Assumptions/Dependencies: Vendor support; changes to serving runtimes; profiling to avoid throughput regressions.
- Sector: Regulated domains (healthcare, aviation, law); Use case: After clinical/field validation, use DeepConf-high to provide conservative decision support and trigger mandatory human oversight when confidence tails off; Tools/Workflows/Products: Compliance-grade audit logs of confidence and consensus; Assumptions/Dependencies: Extensive domain validation and monitoring; regulatory approval; strong governance.
- Sector: Robotics and real-time planning; Use case: Maintain real-time deadlines by pruning low-confidence plan expansions and allocating additional samples only when β is low; Tools/Workflows/Products: Planner with confidence-aware breadth/depth allocation; Assumptions/Dependencies: Tight integration with motion planners/safety layers; hard real-time constraints.
- Sector: Personalized tutoring and assessment; Use case: Adaptive compute per student/problem difficulty using β, with explanations sourced from top-confidence traces and formative hints when confidence drops; Tools/Workflows/Products: Tutor that tunes η and τ per learner profile; Assumptions/Dependencies: Fairness and accessibility considerations; privacy for telemetry.
- Sector: Cost governance and policy; Use case: Organizational policies that cap “thinking tokens” per task using DeepConf’s adaptive budgets, with auditability of cost–accuracy trade-offs; Tools/Workflows/Products: FinOps dashboards showing β, η, τ and token savings; Assumptions/Dependencies: Cultural/process adoption; alignment with business risk tolerance.
- Sector: Dataset and benchmark design; Use case: Create “confidence stress tests” where local confidence drops foreshadow errors, to evaluate robustness of reasoning models; Tools/Workflows/Products: New benchmarks focusing on tail/lowest-group behavior; Assumptions/Dependencies: Community adoption; standardized logging of token-level distributions.
- Sector: Auto-routing across tools and models by SLAs; Use case: A unified controller that, given latency/accuracy/cost targets, tunes η, τ, Ninit and escalates tooluse or model size when β remains low; Tools/Workflows/Products: SLA-aware orchestrator; Assumptions/Dependencies: Reliable calibration curves; dynamic cost models; complex system integration.
- Sector: Market and billing innovation; Use case: Cloud providers bill by “effective tokens” (tokens saved via early stopping) and expose confidence telemetry as a first-class metric; Tools/Workflows/Products: New pricing plans and observability APIs; Assumptions/Dependencies: Provider support; standards for confidence metrics; customer education.
Notes on feasibility across applications: Many gains stem from domains where local confidence correlates with correctness (shown for math/STEM in paper); in open-ended creative tasks correlations may weaken. Methods require access to token logprobs and multi-sample generation; hosted black-box APIs without logprobs or n>1 sampling limit applicability. Thresholds (η, τ, s, window size) need per-domain tuning; over-aggressive filtering can amplify bias or “confidently wrong” modes; conservative DeepConf-high is safer in high-stakes contexts.
Collections
Sign up for free to add this paper to one or more collections.