- The paper demonstrates that LLMs self-verify using verbalized confidence, improving accuracy and calibration via the CSFT method.
- CSFT employs scalar confidence labels and Low-Rank Adaptation to dynamically modulate chain-of-thought reasoning based on internal uncertainty.
- Experimental results show up to a 37% accuracy gain and a 63% reduction in calibration error, enhancing model safety and interpretability.
Verbalized Confidence Triggers Self-Verification: Emergent Behavior Without Explicit Reasoning Supervision
Introduction
In modern applications involving LLMs, ensuring reliability is paramount, particularly in domains requiring decision support. The paper "Verbalized Confidence Triggers Self-Verification: Emergent Behavior Without Explicit Reasoning Supervision" (2506.03723) addresses the critical issue of uncertainty calibration in LLMs. The study introduces a Confidence-Supervised Fine-Tuning (CSFT) approach, demonstrating that verbalized confidence can enhance model performance in chain-of-thought (CoT) reasoning tasks without explicit reasoning supervision.
The approach notably requires only scalar confidence labels during supervised fine-tuning, promoting self-verification actions where models autonomously extend their reasoning when confidence is low and opt for brevity when confidence is high.
Confidence-Supervised Fine-Tuning (CSFT)
CSFT leverages scalar-confidence labels derived from partial self-consistency in model generations to enhance calibration. This process involves generating CoT reasoning traces and answers while only supervising the confidence component. Through this method, the model becomes adept at modulating its reasoning approach based on internal uncertainty, leading to improved interpretability and reasoning accuracy.
CSFT employs Low-Rank Adaptation (LoRA) to fine-tune LLMs like LLaMA3.2-3B-Instruct. By conditioning verbalized confidence through self-rendered labels, it bridges the gap between internal uncertainty representations and external reasoning dialogs.
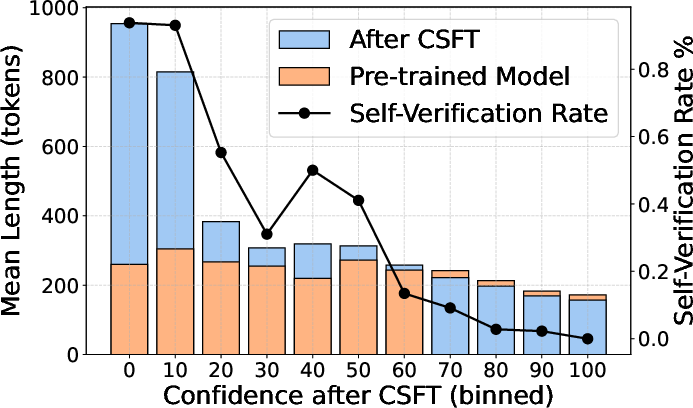
Figure 1: Generation length and self-verification rate across confidence bins on GSM8K using the CSFT-trained LLaMA-3.2-3B-Instruct model.
Experimental Results
Calibration and Accuracy Improvements
The empirical results reveal notable improvements across calibration and accuracy benchmarks such as GSM8K, MATH-500, and ARC-Challenge. CSFT not only enhances the model’s self-verification but also drives length modulation according to confidence levels (Figure 1). The trained models display significant output length variation, with more deliberate reasoning for low-confidence predictions:
- GSM8K Results: CSFT delivered up to a +37% increase in accuracy for the GSM8K dataset while reducing expected calibration error (ECE) by 63% compared to pre-trained baselines.
- Generalization: Models fine-tuned with CSFT exhibited superior performance on unseen structures like MATH-500 and ARC-Challenge. The transferability of reasoning patterns beyond the training dataset further underscores CSFT's robustness.
Self-Verification Behavior
The emergence of self-verification illustrates how LLMs, with appropriately designed fine-tuning strategies, can independently adjust their chain of thought. This capability was particularly evident when models produced longer, reflective answers at lower confidence levels, thereby reinforcing interpretability and correctness through iterative self-assessment (Figure 2).
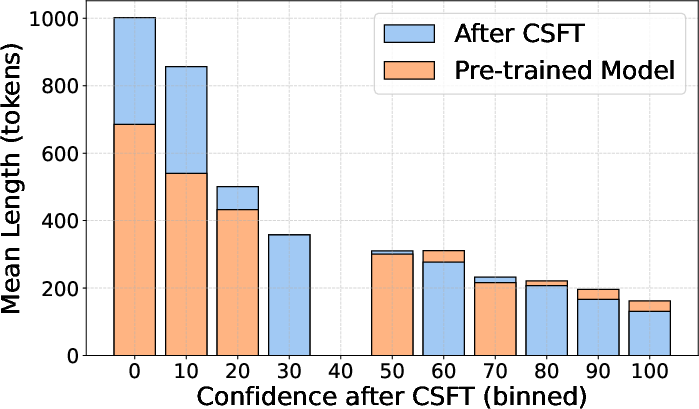
Figure 2: Output length across confidence bins on Math-500, using LLaMA3.2-3B-Instruct fine-tuned with CSFT.
Theoretical and Practical Implications
The intersection of calibration and confidence is increasingly telling of model reliability in practice. By allowing models to express and act upon their uncertainty, CSFT aids in developing LLMs suitable for high-stakes decision environments, improving safety, transparency, and user trust.
The proposed CSFT framework suggests theoretical pathways for enhanced calibration that could be applicable to a broader range of tasks. It offers a platform for exploring uncertainty-driven policy adaptations during inference, potentially optimizing resource allocation based on predicted confidence.
Conclusion
The study advances our understanding of the interplay between confidence estimation and model reasoning. Through a simple yet remarkably effective fine-tuning process, it showcases the possibility of emergent behavior facilitating self-verification without specific task supervision. CSFT highlights the potential for confidence-aware methods to transformatively impact AI's deployment, emphasizing safety and interpretability. Future research could further hone these capabilities, exploring the nuanced dynamics of confidence and reasoning in increasingly complex environments.